论文总字数:17722字
目 录
1引言 1
1.1证件识别系统的研究背景和意义 1
1.2证件识别系统的国内外研究现状 1
1.3证件识别系统的研究目标与内容 3
1.3.1 研究目标 3
1.3.2 研究内容 3
2设计的基本原理 4
2.1图像预处理方法 4
2.2字符空间分布特征 5
2.3字符结构特征 6
2.4模板匹配法 6
3系统设计与实现 7
3.1图像预处理 8
3.2图像二值化 9
3.3字符块定位 10
3.4字符分割和提取 10
3.5字符识别 11
4系统测试与分析 12
4.1模板库获取 12
4.2 人机交互界面 13
4.3 系统功能检测 14
5总结与展望 15
5.1总结 15
5.2展望 16
参考文献 18
致谢 19
基于MATLAB的证件识别系统
李鹏飞
,China
Abstract: This design takes the identification technology of the second generation identity card image as the research object, and uses the software system to quickly and accurately extract name, sex, nationality and address information from the identity card image as the research object. The software algorithm of this system is designed based on MATLAB virtual simulation platform, and images are preprocessed by median filtering, graying, binarization and other technical means, and character blocks and individual characters in images are segmented and extracted by methods such as position coordinate calculation, expansion corrosion, searching for connected areas and the like. Normalize the segmented and extracted character blocks and character images, so that the size of the characters to be recognized is unified with the template standard. finally, the template matching method is used to match the characters to be recognized with the character template library established in advance, and the template sample with the highest similarity coefficient is selected as the recognition result output. The identification speed and accuracy of the system can basically meet the requirements of practical applications.
Key words: ID identification; MATLAB; Image processing; Template matching.
1引言
1.1证件识别系统的研究背景和意义
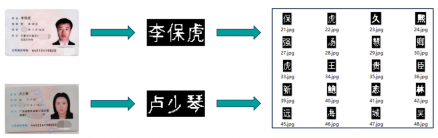
在当今社会,第二代居民身份证作为每一位中华人民共和国居民身份的象征,已然成为日常社会活动中不可或缺的物品。为了保护公民的正当利益不受侵害、维护稳定有序的社会环境,越来越多的行业都开始要求对居民的身份证信息进行登记管理,例如轨道交通安检、银行业务办理、通信业务办理、酒店旅馆住宿及网吧上网等。目前,以上行业对于身份证信息的采集管理相当一部分仍然采用传统的手工登记方式,也有一些采用磁条读取设备获取证件的有效信息。然而上述两种方式中存在着一些问题:1、手动录入方式用时较长,内容较多,效率较低,而且可能由于人为因素导致信息登记发生谬误,造成较为严重的后果或者较大的损失;2、使用磁信号读取设备来获取证件的有效信息可能因为证件被消磁或其他原因而无法正常使用。基于上述情况,现今需要研究出一种便于日常登记使用、信息识别性能良好、使用快速高效的证件识别系统,能够使客户使用端自动提取、识别身份证中的有效信息并将其按需求分类保存,以便于日常生活中的信息管理和应用。为此,我们基于MATLAB软件工具平台应用OCR(Optical Character Recognition光学字符识别)技术研究开发出了此项证件识别系统来解决上述问题,本设计较为突出的设计点是从图像处理入手对身份证证件信息展开研究,先对要求识别的身份证图像采取预处理手段,将预处理后得到的归一化字符图像与模板库中的标准样本进行匹配,最终选择相似程度最高的模板样本值作为识别结果输出,上述步骤均基于MATLAB软件工具平台通过程序算法设计来对图像进行处理,最终达到自动识别的目的。因此,综上所述,此项证件识别系统的研究对于社会生产实践的现实意义非常重大。
1.2证件识别系统的国内外研究现状
基于OCR技术和模板匹配的证件识别系统目前国内已经出现实例化的商用系统,其研究内容归属于特殊光学字符的识别及处理范围。其不同于普通的光学字符识别的点在于:身份证证件图像识别的图像背景比一般图像的背景要更为复杂,而且由于身份证特殊的防伪标识设计和拍摄条件的影响,身份证证件图像往往存在着大量的噪声干扰,影响识别结果。目前许多国内外学者对于复杂环境背景中的字符(主要指英文和数字字符)识别工作开展了较为深入的研究,其研究对象主要集中在车牌号码识别和集装箱编号的识别[1]。在上述这些研究工作中对于字符识别技术的研究论证均比较详细,其中很多的研究方法和技术理论对于本设计的研究有着极其重要的参考价值和借鉴意义。
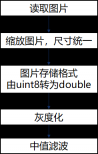
目前基于模式识别和图像处理的字符识别研究主要可以概括为下面这些内容:图像的预处理,字符的特征提取,字符的识别,识别的后续处理等。目前已有大量的国内外学者针对以上问题开展了许多深入而又详细的研究,根据不同的识别环境研究出了许多切实可靠的应用结果。根据目前的研究现状来看,证件识别系统的图像预处理大致包括后面这些过程:图像灰度化和二值化,图像的非均匀光照校正和倾斜校正,图像字符块的切割、提取和归一化处理,以及单个字符的切割、提取和归一化处理等。目前大多数的证件识别设计工作中所开发的证件图像处理系统均以普通的RGB图像作为的待识别图像。图像预处理过程中的非均匀光照校正通过对强光照部分和光照不足部分的分别处理来进行校正,然后通过强光照部分来获取身份证图像的像素空间特征分布,根据JPG空间的颜色偏移率不同来实现高强度光照区域的自动校正;对于光照不足部分则需要对其强度进行增强。
在我国,对于OCR技术的系统研究起步相对较晚。在70年代初,才开始研究数字字符、英文字符已及常见简单符号的识别与判断;70年代末才开始了对汉字进行字符识别的研究;直到1986年,对于汉字字符识别技术的研究才取得了一定成果,相对来说进入了实质性的研究阶段[2]。此后,多家研究单位陆续推出了各种不同的OCR中文产品,在中文信息处理领域中较为资深的清华大学和汉王公司等都推出了具有各自特点的代表性产品,其中包括汉王表格自动录入系统,汉王尚书五号、六号系统,蒙恬OCR文字扫描识别系统,清华文通的TH-OCR2000,清华紫光的紫光OCR等著名产品[3]。以上这些系统软件在字符识别方面,就识别的速度和识别准确率而言,基本满足了用户的实际需求。到目前为止,汉字印刷体字符图像识别技术的系统性能在各方面均有了较大程度的提升,系统的稳健性也得到了极大的改善。
早在1999年,汉王公司就率先推出了国内首套中文名片识别软件系统,经过多年的发展,字符识别的技术水准得到了极大的提升,功能也越来越完善,并逐渐趋向于多元化发展。目前,在国内证件识别商用领域中较为知名的名片识别软件有:北京汉王科技有限公司的汉王名片通、台湾蒙恬公司的蒙恬名片王、清华紫光公司的紫光名片大师、新加坡维优公司的维优名片管家等。其中“汉王名片通”的设计研发起步相对较早,识别准确率更高,从1999年至今的十几年中已经研发出了几十个不同的版本,占领了国内中文字符识别软件领域市场份额的70%以上[4]。
对于字符识别的研究,早在上世纪,就有德国科学家Tausheck率先提出了字符识别系统的相关理论,并成功申请了专利。另外据记载,关于印刷体汉字字符的识别技术的研究最早可以追溯到上个世纪60年代之前。在1966年,IBM公司的Casey和Nagy经过研究,联合发表了第一篇关于印刷体汉字字符识别技术的论文,在这篇论文中作者通过简单的模板匹配法成功识别了1000个印刷体汉字字符[5]。
近些年中,在2017年台湾学者民仁仔与印尼学者在印刷文件的来源识别的研究中从灰度共生矩阵(Glcm)、离散小波变换(Dw)两种方法研究了几种字符统计特征集。空间滤波器、维纳滤波器、Gabor滤波器、Haralick滤波器和分形滤波器利用支持向量机(SVM)和特征选择的决策融合来识别文本和图像文档[6]。即使是相同的文本或图像文档在不同的液晶屏和触摸屏上的显示结果也不尽相同,所以在字符识别过程中还需要考虑用户的输入输出设备[7]。
70年代以来,日本的学者们针对汉字字符识别技术做了大量的研究工作,其中较为显著的研究成果有:1977年东芝综合研究所开发出的能够识别2,000个单体汉字的印刷体汉字字符识别软件。80年代初期,日本武藏野电气研究所开发出的可识别2300个多体汉字的印刷体汉字字符识别软件,是当时全世界范围内汉字字符识别系统的最高水平研究成果。除此以外,日本的理光、松下、二洋和富士等公司也有他们各自独立研发的印刷体汉字字符识别系统[8]。
1.3证件识别系统的研究目标与内容
剩余内容已隐藏,请支付后下载全文,论文总字数:17722字
相关图片展示:


该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

