论文总字数:32593字
目 录
1绪论 1
1.1 研究背景及意义 1
1.2研究现状及分析 2
1.2.1分类算法 2
1.2.2深度学习 4
1.3本文组织与结构 5
2常见分类算法模型及深度学习模型 5
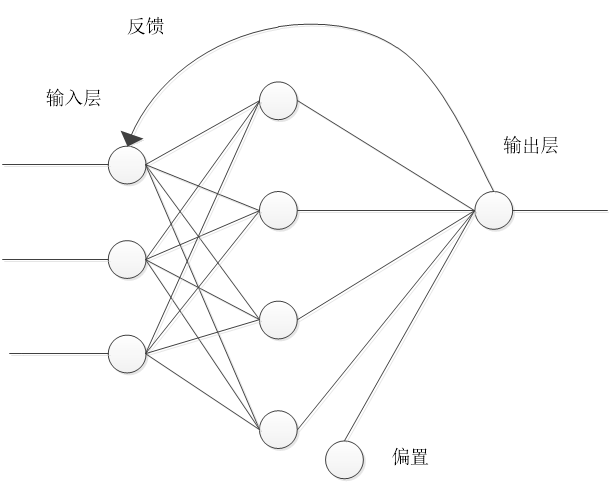
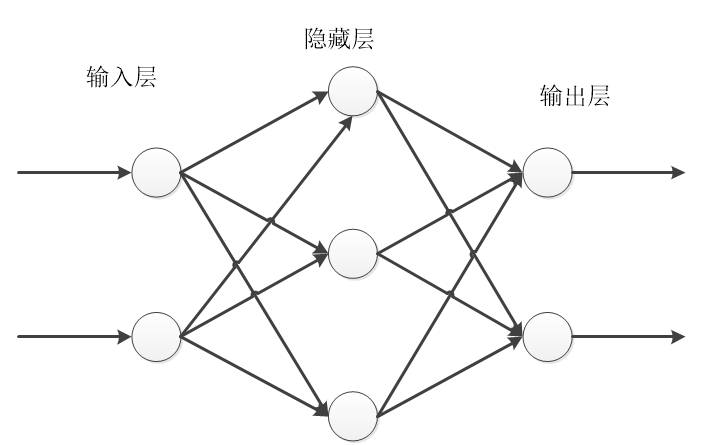
2.1反馈传播神经网络 5
2.1.1人工神经网络 5
2.1.2BP神经网络模型 8
2.2 支持向量机 10
2.2.1 线性支持向量机算法原理 11
2.2.2 非线性SVM算法原理 12
2.2.3 支持向量机核函数选择 13
2.3 深度学习及相关模型 14
2.3.1 自动编码器 14
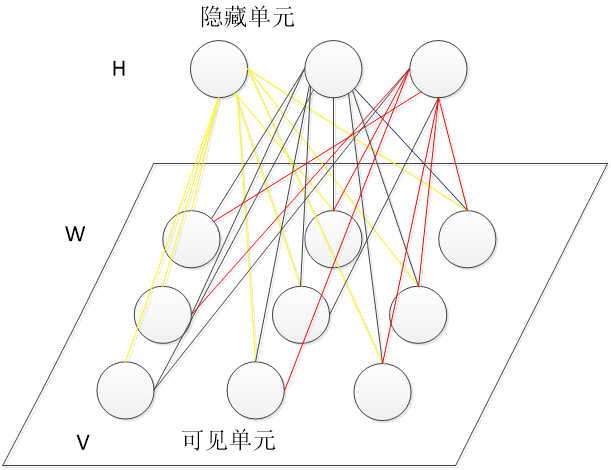
2.3.2 限制玻尔兹曼机 15
2.4 本章小结 16
3基于深度学习的分类算法实验 16
3.1 评估方法 16
3.2准确率对比分类算法 16
3.3 基于UCI数据集的SVM分类算法测试 17
3.3.1 数据集选取及设置 17
3.3.2 分类实验结果 17
3.4 基于UCI数据集的RBM降维SVM分类算法测试 19
3.4.1 数据集选取及设置 19
3.4.2 分类实验结果 20
3.5 基于UCI数据集的BP神经网络分类算法测试 21
3.5.1 数据集选取及设置 21
3.5.2 分类实验结果 22
3.6 SVM和基于深度学习的SVM分类算法结果对比 23
3.6.1 比较对象 24
3.6.2 准确率比较结果 24
3.7算法结果对比 25
3.7.1 比较对象 25
3.7.2 准确率比较结果 25
3.8 本章小结 26
4总结与展望 27
4.1 总结 27
4.2 展望 27
参考文献: 28
致谢 31
本科期间发表论文 32
基于深度学习的分类算法研究
骆翔
,China
Abstract:With the arrival of the big data Era, our life is full of huge amount of information; data mining is a very important tool in this era with rapid development of information, which can help dig out valuable and meaningful information in vast amounts of information. Classifier is an algorithm model commonly used in data mining and it could learn the attributes and labels of the samples that we already know and then build classifier model, after which, it could predict the labels of the unknown samples. This paper first describe the principle and algorithm flow of the commonly used algorithm model: BackPropagation Neural Network and Support Vector Machine in detail and the deep learning model of mind is expounded, putting forward a new classification algorithm model that combine classifier and deep learning model. At the same time, the comparative experiments on the UCI data sets show that the classification algorithm that utilize Restricted Boltzmann Machine to have data feature extraction and then utilize Support Vector Machine to classify outperform the original Support Vector Machine classification algorithm and that multilayer perceptron in multilayer BackPropagation Neural Network has a higher classification accuracy than the original Support Vector Machine classification algorithm.
Key words:Machine Learning;Deep Learning;Support Vector Machine;BackPropagation Neural Network
1绪论
本章主要介绍了原始分类器在目前信息时代所要面临的挑战,同时指出深度学习是一种很好的能优化分类器性能的算法模型。在第二节中着重介绍了应用较为广泛的分类器算法模型的发展历程以及研究现状,并简要概括它们目前在一些领域中的应用。最后,本章指出该论文的整体框架和内容分布。
1.1 研究背景及意义
分类是一种常见的数据挖掘和模式识别技术,通常情况下,要对未知信息进行分类需要首先通过对已知信息进行学习,建立合适的分类器之后再利用所得的分类器模型进行未知信息的分类。早在中国西汉时期,就提出“物以类聚,人以群分”,这里所说的就是一种简单的分类,即具有相似特性的人或者物体容易聚集在一起。随着人类社会的进步,需要进行分类的信息逐渐变得复杂的同时,分类工具的效率也在逐渐上升。直到现在这个信息技术飞速壮大的时代,互联网技术成为这个时代的主流,根据第39次《中国互联网发展状况统计报告》可知,“.CN”注册量稳居全世界域名第一,且截止2016年末,中国移动终端网民数量高达6.95亿人之多。无论是网页或者手机应用程序都会存储着信息量庞大的用户信息,而在这个大数据时代,分类器不仅会被用于处理结构化或者非结构化的信息,它还会被用于对具有数据量庞大、属性繁杂等特征的信息进行分类,这无疑会延长分类器的分类时间并在某种程度上降低分类器的分类效率。由于训练数据集数量和维度的爆炸性增长,传统的分类器算法无论是训练时间或者准确率都处于劣势。
随着人类思维和科技的进步,慢慢地,人类开始探索人脑如何学习,并将此人工神经网络模型应用于计算机中,让机器进行自主学习,人工智能由此诞生。2006年,多伦大学Geoffrey Hinton教授和其学生Ruslan Salakhutdinov在《Science》期刊上发表了一篇有关Deep Learning原理的重要文章,他将Deep Learning推向了这个信息时代的浪潮。Machine Learning是人工智能的核心,Deep Learning是Machine Learning的主要方式和方法,虽然目前有关Deep Learning理论的研究还处于起步阶段,但是它已经在某些领域起着不可忽视的作用。计算机通过深度学习模型,逐渐模仿人类学习,并在一定领域超过了人类。21世纪,以深度学习为主要基础模型的深度神经网络使ImageNet图像识别错误率由原来的26%降低至15%。2015年,Microsoft在ImageNet测评上的错误率已降至3.57%[1]。。
考虑到目前原始分类算法本身所具有的限制,比如,在处理数据量大,属性种类繁多的数据时,分类器会表现出分类时间长、分类效率低等缺点,为了提高现有多分类器的表现能力,本文引入深度学习的思想,增加神经网络反馈层达到充分学习特征的目的以提高分类器的分类性能,同时,利用深度学习的基础模型——限制玻尔兹曼机对原始数据进行重新编码,隐藏层得到的新数据成为原始数据的压缩表示,之后将最后隐藏层的特征值抛给监督学习的支持向量机分类算法进行分类。本论文的研究结合了当今时代最新的深度学习基础模型,具有一定的时代意义,同时,在多分类算法领域引入深度学习模型有利于两者的紧密结合并有利于推动数据挖掘技术的发展,同时,本论文的研究也有助于启发其他学者发现深度学习思想模型与分类算法在其他方向结合的具有意义的新研究方向。
1.2研究现状及分析
1.2.1分类算法
目前为止,针对多分类问题的研究中,出现许多模型成熟的分类算法模型,常见的分类算法模型有贝叶斯分类器,决策树分类器,K最近邻算法,ANN人工神经网络,SVM(支持向量机)算法等。有相关学者对以上分类算法模型进行了更深入的研究以提高各种目前主流的分类器工作效率。
贝叶斯(Bayes)分类器是一种利用统计学知识的分类算法模型,它同时具有Bayes网络特征。早在1763年,著名的数学家贝叶斯发表了一篇具有哲学意义的文章[2],这为以后贝叶斯网络以及贝叶斯分类器的发展打下了坚实的基础。由杰弗里教授所写的《概率论》正式表明Bayes学派成立,对于先验分布问题,他提出了以他名字命名的杰弗莱准则[3],后来,1988年,来自美国知名大学的Pearl教授第一次提出了Bayes模型的概念[4]。Bayes分类器的工作原理是通过首先利用Bayes网络对样本数据进行特征学习,之后对类节点条件概率进行计算,通过计算出的概率值对所要分类的样本数据进行处理。朴素贝叶斯是一种最简单的贝叶斯分类器模型,它处理样本数据丢失和样本异常值过多的数据时表现出极大的包容能力,并且由于它忽略属性之间的相互联系使得当它在对待分类数据处理时,只需要计算出每个单独属性的概率并选择概率较大的属性,所以朴素贝叶斯的这种思想很大程度上降低了计算复杂度,这也让朴素贝叶斯分类器具有分类速度快的优点。近几年,贝叶斯和朴素贝叶斯分类器的研究深受中外学者的关注。田凤占等教授[5]提出新的贝叶斯分类方法以处理连续变量;宫秀军等教授[6]在现有研究基础上提出了基于Bayes网络的主动分类算法;Langley等教授[7]针对朴素贝叶斯忽略数据属性之间的相互联系,建立了具有选择性的贝叶斯分类器来提高具有冗余属性特征数据集的分类效率;一种新的加权朴素贝叶斯模型被Webb等教授[8]提出。随着贝叶斯分类器的深入研究,它已经在多个领域里得到广泛的应用,比如,利用贝叶斯分类器进行文本分类[9],矿样分类[10],恶意代码分类[11],微博情感分类[12]等。
决策树(Decision Tree)是分类和预测领域中常用的技术,它可以被用于分类书籍,档案管理等。实质上,决策树组成的是一个复杂的树状结构。从根节点开始,每一个子节点都是一个类别判断节点,也相当于一个IF判断语句,子节点后的分支代表IF判断语句输出的结果,当此结果被输入到下一个子节点中时,继续进行类别判断,直到该子节点为末端节点。据有关学者研究,Decision Tree算法模型的有效分类正确率可达到19%[13]。概念学习系统是Decision Tree的模型基础,它将全部数据库分割为若干个数据子集,通过对数据子集的递归调用达到将新元素进行分类的目的,而针对概念学习系统无法处理复杂问题的缺点,1986年Quinlan提出了ID3算法[14]。此算法结合了信息增益分析技术和多维数据分析技术,集合复杂的属性并删去简单的属性,同时对属性进行加权,降低不重要属性的重要程度。1984年由L. Breiman,J.H.Friedman及R.A.Olshen等教授提出的分类回归树[15](Classification and regression trees)得到了广泛的应用,CART是基于最简化吉尼指标的方法并生成标准的二叉树结构。再后来,随着技术的发展,1996年,IBM的有关科研人员提出了一种基于决策树的快速分类算子法(Supervised Learning in Quest),同样,此基于决策树的快速分类算子法利用吉尼指标代替信息增益率作为评价节点参数,此方法可以处理复杂度更高的数据集并以相对花费较少时间达到分类结果。
剩余内容已隐藏,请支付后下载全文,论文总字数:32593字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

