论文总字数:31217字
目 录
摘要 I
Abstract II
第一章 前言 1
1.1 研究背景 1
1.2 研究现状 1
第二章 空间数据挖掘概述 3
2.1 数据挖掘理论 3
2.1.1数据挖掘的概念 3
2.1.2 数据挖掘的基本步骤 3
2.2空间数据挖掘理论 7
2.2.1 空间数据的特点 7
2.2.2空间数据挖掘的特征 7
第三章 数据预处理 8
3.1 数据预处理的概述 8
3.2 数据离散化与数据抽取 8
3.2.1数据抽取 8
3.2.2 数据离散化 9
第四章 聚类算法的实现及应用 12
4.1 聚类的概述 12
4.2 聚类分析的分类 12
4.3 K-means算法 12
4.3.1 K-means算法的简介 12
4.3.2 K-means算法的实现过程描述[31] 12
4.3.3 K-means算法的实现说明 13
第五章 分类算法的实现与应用 19
5.1分类的概念 19
5.2 决策树分类 19
5.2.1 ID3算法的简介 20
5.2.2 ID3算法的决策树构造描述 20
5.2.3 ID3算法的实现过程 21
5.3 朴素贝叶斯分类器 25
5.3.1朴素贝叶斯的简介 25
5.3.2朴素贝叶斯的实现过程 27
第六章 空间数据挖掘系统平台的设计与实现 31
6.1 系统平台的功能设计 31
6.1.1 数据处理模块 32
6.1.2 数据挖掘模块 32
6.1.3 可视化模块 32
第七章 结语 33
参考文献 34
致 谢 36
第一章 前言
1.1 研究背景
1995年在加拿大蒙特利尔举办的的第一届知识发现和数据挖掘国际会议上,“数据挖掘”概念首次由Usama Fayaad提出[1]。随着人类活动的不断发展,方方面面均增加了大量的信息数据,由于数据海量,数据结构复杂,传统的统计方法无法满足日益增长的数据分析需求[3]。联机分析处理(On-Line Analytic Processing,OLAP) 、决策支持(Decision Support)以及分类(Classification)、聚类(Clustering)等复杂算法[3]应用成为必然 ,具有查询过去的数据的功能,可以找出过去数据之间的潜在关系并进行更高层次分析来做出理想的决策和预计未来发展趋势的挖掘新型算法的实践成为了解决问题的有效途径[4]。
在这样的现实背景下,数据挖掘系统的开发便成了首要的解决方法。本研究的目的正是针对这一境地,通过设计与实现一个集成多算法的空间数据挖掘系统平台帮助人们进行高层次分析和趋势预测。本数据挖掘集成系统能方便人们在海量数据中自动地、高效地发现潜在知识,为以后进行分析和决策作基础。尽管进行了多年发展,数据挖掘系统逐渐发展成熟,但不可避免也存在一些遗留问题[5]。一般的系统可扩展性较差,即系统平台中所集成的算法较为局限,实现算法较为单一,且用户在使用系统时无法单独达到预期目标,不利于推广,同时由于还需要进行专业知识的学习才能操作,由此本研究设计的系统为用户提供了能够改进这些问题的集成平台,其中简单的操作可为用户减少学习和操作时间,三种不同的空间挖掘算法可针对客户不同的要求及数据的多样性进行相对应的算法实现。
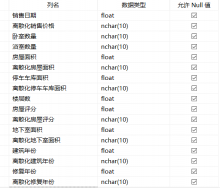
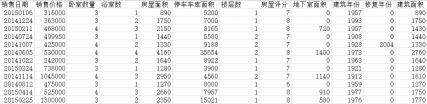
本文采用美国King county房屋基本信息数据对系统进行测试,也可对其他的数据进行聚类和分类分析。此系统可应用到例如制造业生产要素的聚类分类,由此实现生产过程的优化;库存异常检测中判断整体性指标变化和各别指标异常;根据算法得到的综合评价指标选择应急避难场所等[6][7]。
1.2 研究现状
数据挖掘发展至今,已成为许多国际学术会议热议的话题,例如SIGMOD(数据管理国际会议 Special Interest Group on Management Of Data),SIGKDD(国际数据挖掘与知识发现大会Special Interest Group on Knowledge Discovery and Data Mining)等。
在国外,如加拿大的西蒙弗雷泽大学、芬兰赫尔辛大学、德国的幕尼黑大学等。在邻接图理论的基础上,Ester等[7]人提出了一个基于ID3算法的空间分类算法。Koperski[6]提出了两步分类算法。1994年GIS国际会议上[8],李德仁院士第一次提出了从GIS数据库中发现知识的概念,他提出从GIS数据库中可以发现包括几何特征、空间关系和面向对象的多种知识 [9]。在Han和Kamber[10] 的数据挖掘著作中,系统地讲述了空间数据挖掘的概念和技术。Lu,Han和Ooi[1]提出了面向属性归纳的基于概化的空间数据挖掘方法,Koperski和Han[12] 提出了一种逐步求精的空间关联规则挖掘方法。从空间数据挖掘系统的开发角度看,目前国际上有代表性的通用SDM(Security Device Manager)系统有:GeoMiner,Descartes和Arcview GIS的S-PLCS 接口[13]。建立了空间数据挖掘的原型系统GeoMiner的加拿大 Simon Fraser大学计算机科学系的数据挖掘研究小组将空间区分、空间分类、空间数据特征描述、空间聚类和空间关联等空间数据挖掘方法实现应用。ESRI公司研发的Arcview GIS的S-PLCS接口可以提供分析空间数据中指定的类的工具。Descartes支持可视化的分析空间数据可以与数据挖掘工具Kepler动态连接,把传统数据挖掘与地图可视化有效联结[14]。
在国内,对数据挖掘和知识发现的研究起步较晚,数据挖掘研究的工作集中于数据挖掘算法和有关数据挖掘理论方面的研究,全面有效地开展了空间数据挖掘研究的大学和研究所有武汉大学、环境信息系统国家重点实验室、中科院地理所资源等[15]。南京大学的徐洁磐、陈栋等人开发了通用数据挖掘工具原型系统Knight,可用于处理不同领域的知识发现任务,该系统包括聚类分析、分类和关联的规则发现、函数依赖发现和特征知识发现以及及基于查询的知识发现等数据挖掘功能。陈铭[16]提出一种基于基于相似维的高维子空间聚类方法。石亚冰[17]等提出基于最大维密度选择方案,其全面考虑到空间数据对象特征的改进之处可以优化K-means算法。何彬彬[18]等利用EM 和Apriori提出新型挖掘算法模型,改进了空间数据挖掘的不确定性。林长方[19] 等针对关联算法Apriori提出结合固定多阶段和挖掘策略的改进算法。中科院计算所智能处理开放实验室的史忠植等人设计了一个数据挖掘工具MSMiner,提高计算资源的利用效率[20];海尔青大公司开发了具有自主知识产权的iDMiner;复旦德门公司开发的“天眼”数据挖掘工具集DMiner集成了多种数据挖掘算法。近几年,数据挖掘的重心逐步从算法研究过渡到具体应用如网络信息检索、网络数据挖掘等领域,带来了丰硕的成果和丰厚的效益。
第二章 空间数据挖掘概述
2.1 数据挖掘理论
2.1.1数据挖掘的概念
数据挖掘为数据库中的知识发现,是从大量的、不完全的、有噪声的、模糊的、随机的数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程[21] 。
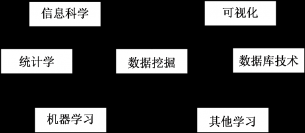
图1 数据挖掘涵盖多个方面
根据用户目的及其所处的领域的不同,数据挖掘所依赖的数据可以是大的数据,或者数据仓库,或者数据集市等从外部世界收集的原始数据存储的地方。适用于多领域的数据挖掘系统工具需要具备从多种数据源中提取数据、筛选、预处理和净化数据进行分析的能力。
2.1.2 数据挖掘的基本步骤
数据挖掘算法,总的来说占用工作时间并不久,而数据准备和预处理工作则占用了大部分的工作时间[22]。
图2 数据挖掘的过程示意图
问题定义阶段可以确定发现的知识类型和业务问题;数据集成、数据选择和数据预处理共同称为数据预处理;数据挖掘分为两阶段:任务确定阶段和执行阶段。最后进行结果解释评估,即解释数据挖掘步骤中发现的模式。
2.1.3数据挖掘的过程模型
现今主要的数据挖掘过程模型主要可分为两类:Fayyad过程模型;遵循CRISP—DM( 跨行业数据挖掘标准流程Cross-industry Standard Process for Data Mining)标准的过程模型。
(1)Fayyad数据挖掘模型
Fayyad数据挖掘模型将数据库中的知识发现看作是一个多阶段的处理过程,它从数据集中识别出以模式来表示的知识,并且在整个知识发现过程中包括很多处理步骤。该过程之间相互影响,反复调整,形成一种螺旋式的上升过程[23]。
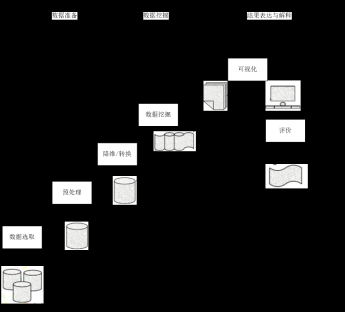 图3 Fayyad数据挖掘过程模型
图3 Fayyad数据挖掘过程模型
(2) 遵循CRISP-DM标准的过程模型
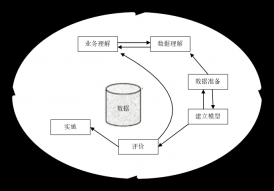
图4 CRISP-DM数据挖掘过程模型
表1 CRISP-DM模型过程步骤

CRISP-DM模型是一个强调技术的应用模型,其特点[24]是注重数据挖掘得到的模型与业务问题相结合、部署应用挖掘出的模型的方式方法。本挖掘系统平台的设计依据Fayyad过程模型。
2.1.4 数据挖掘系统的体系结构
数据挖掘系统是一个融合了信息管理、信息检索、专家系统、分析评价、数据仓库的技术含量极高的应用软件系统。
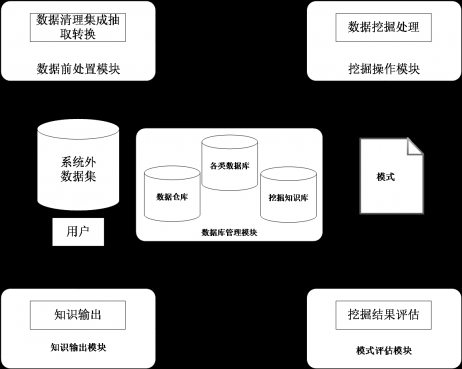
图5 数据挖掘系统的体系结构图
表2 数据挖掘系统体系结构说明

2.2空间数据挖掘理论
空间数据挖掘(Spatial Data Mining)的目的在于从空间数据仓库中提取事先未知且潜在有用的空间规则、概要关系、摘要数据特征、分类概念描述或偏差检测等知识,是基于空间数据的一种决策支持过程,具有数据动态变化、含噪声、数据不完整、信息冗余、数据稀疏和数据量超大等技术难点。
2.2.1 空间数据的特点
空间数据(Spatial Data)是人们据以认识自然和改造自然的重要数据,指空间实体的属性、数量、位置及其相互关系等的空间符号描述。空间数据具备从宏观,中观到微观的整个层次,与一般的数据相比,空间数据具有空间性、时间性、多维性、大数据量、空间关系复杂等特点。空间数据不仅是空间信息的载体,还是形成认知基元——空间概念的要素。用于空间数据挖掘的空间数据一般是经过必要加工处理后的电子数据(即数据清理后的数据)。
2.2.2空间数据挖掘的特征
空间数据挖掘所能发现的空间知识主要包括空间的关联、分类、聚类等规则GIS数据库是空间数据库的主要类型 [25]: 空间分布规律,即地理对象在地理空间中的分布规律。空间关联规则, 即能够挖掘出数据隐含的规则、知识等,将关联规则挖掘算法应用在空间数据库的访问技术中。空间特征规则,即对于某类空间对象,其几何(位置、形态特征等)和属性(数量、面积等)的共性特性。空间区分规则,与 空间特征规则相对,即对象之间几何或属性有所区别的特性(用来区分异类对象)。空间分类规则,即分类分析针对对象的空间或非空间特征将其划分为不同类。空间聚类规则,即划分有相似特征的空间对象为同一类中。空间数据挖掘相较于通用数据挖掘增加了空间尺度 ,即要在一定的空间位置信息基础下进行聚类分析和分类分析。
第三章 数据预处理
3.1 数据预处理的概述
实际上,数据大都具有不一致性、重复性和不完整性,无法满足数据挖掘算法的要求。同时,由于大量数据中常存有与冗余,即数据挖掘任务无关的成分,因此会降低数据挖掘算法的执行效率,使数据的可理解性收到严重影响。数据预处理可以减少数据挖掘过程其他过程的复杂程度、减少工作量;同时能够提高数据挖掘的效率。
剩余内容已隐藏,请支付后下载全文,论文总字数:31217字
相关图片展示:


该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

