论文总字数:48195字
摘 要
本文应用经典的RBT空间数据转换方法,设计并实现了对数值型关系表数据进行隐藏处理的软件系统。
RBT方法,即“基于旋转的数据转换”方法,通常用于解决数据集中分布的隐私保护聚类问题。本文实现的软件系统模拟了RBT方法转换数值型关系表数据的过程,并具有以下特点:(a)用户自行选择原始数据表;(b)用户自行选择两个属性组成属性对,并可选择属性对内属性的次序;(c)用户自行设定安全临界值和转换角度;(d)展示转换前后的相异度矩阵以验证算法的准确性。
经过测试和分析,系统能够实现对数值型关系表数据进行转换以保护隐私属性,且转换前后的数据表近似保距,误差在万分之一的范围内,结果说明软件系统较好的实现了使用RBT方法隐藏数据的预期功能。
关键词:数据隐藏,RBT方法,数值型关系表,软件系统
ACHIEVING OF DISTANCE-PRESERVING DATA HIDING SYSTEM
Abstract
In this thesis, we achieved a data hiding system for numerical relational table with the classic RBT method.
The RBT method, based on data transformation, is usually used to solve the problem of privacy-preservation clustering over centralized data. The software system we achieved here had simulated the transformation process operated on numerical relational table, and the major features of our system are: (a) users can select a data table to transform; (b) users can choose attribute pairs and decide the order of an attribute in a pair; (c) users can also set a pairwise-security threshold and transformation angle; (d)verify the accuracy of RBT method through computing dissimilarity matrix before and after the conversion.
After testing, the system can successfully convert numerical relational table in order to protect private attributes. We also find the global distances between data points are approximate the same, and the result shows that the software system achieved the expected functions to hide data with RBT method.
KEY WORDS: data hiding, RBT method, numerical relational table, software system
目录
保距数据隐藏系统的设计与实现 I
摘 要 I
Abstract II
第1章 绪论 1
1.1 研究背景 1
1.2 面向聚类的隐私数据保护问题的研究现状 1
1.3 本文的研究内容和结构安排 2
第2章 数据隐藏系统实现的相关技术 3
2.1 基本概念 3
2.1.1 等距变换 3
2.1.2 数据矩阵 4
2.1.3 数据标准化 4
2.1.4 相异度矩阵 4
2.2 RBT方法的算法描述 5
2.3 RBT方法的性能指标 6
2.3.1 RBT方法是n维空间的等距变换 6
2.3.2 RBT方法的安全性 7
2.3.3 RBT算法的时间复杂度 7
第3章 软件系统的设计 9
3.1 设计隐私保护系统的一般步骤 9
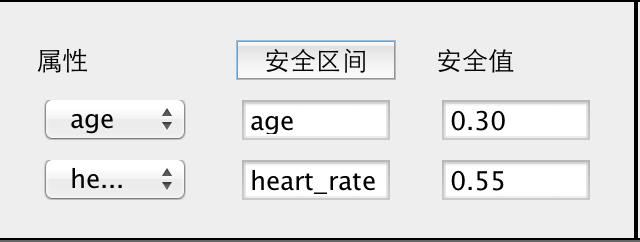
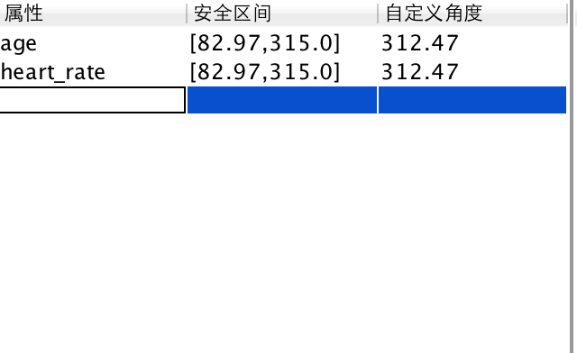
3.2 软件系统的功能需求 9
3.3 软件系统的设计流程 9
3.4 软件系统的界面设计及特点 11
第4章 软件系统的实现与测试 12
4.1 软件系统的实现 12
4.1.1 原始数据读入部分 12
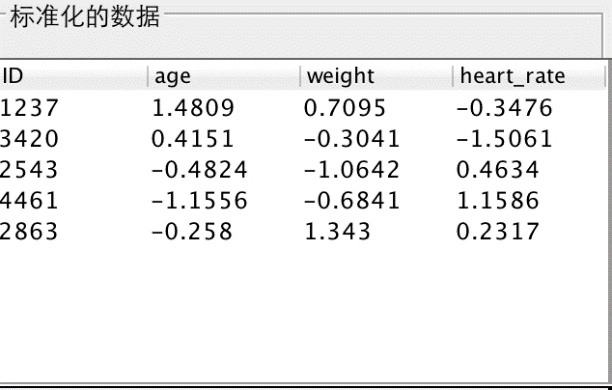
4.1.2 原始数据标准化部分 12
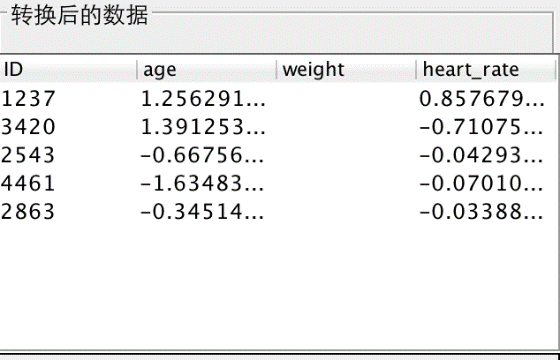
4.1.3 数据转换部分 13
4.1.4 求相异度矩阵部分 13
4.2 软件系统的设计与分析 14
第5章 结束语 19
参考文献 20
致谢 21
附录A 22
绪论
研究背景
随着互联网技术的发展,人们每天都要产生和处理大量的数据。随之产生了数据挖掘技术,用于从大量的数据中发现规律,抽取出潜在的,有价值的知识。例如,个人信用记录,网上购物习惯,犯罪记录等数据的收集和分析可以帮助政府和企业做出更加合理的决策。然而,如果数据挖掘结果被不正确的使用或发布,则有可能会泄露数据中的个人隐私属性。随着人们保护个人隐私和敏感信息意识的加强,共享数据用于聚类分析时的隐私保护问题逐渐受到人们的重视。通常,这一问题的应用场景可以描述为:数据持有者信任数据收集者,但是不信任数据使用者[14]。数据持有者通常可以将真实的数据交给数据收集者,而数据收集者必须将真实数据通过数据隐藏技术进行处理,并将处理后的数据交给数据使用者进行聚类分析。
例如,医院在病人群体中进行相似病症的研究,需要给进行聚类分析的数据使用者提供相关数据。然而,这些数据中可能包含姓名,家庭住址等病人不想泄露的个人隐私信息。因此,医院需要使用数据隐藏技术对原始数据加以转换。
为了解决面向聚类的隐私保护数据发布的问题,一些数据隐藏方法应运而生。一般而言,数据隐藏技术需要考虑以下两点:
(1)如何保证发布数据的聚类可用性。
聚类可用性与所有数据点的分布和相似性有很大关联。而数据隐藏技术在转换数据时,很有可能改变数据点的分布及相似性,从而使隐藏后的数据失去可用性。
保证聚类结果的可用性要求隐藏前后的数据集合具有相似的聚簇结构和特征,通常可以采用对象间的距离的概念来衡量两个对象的相似性。若通过数据隐藏技术进行扰动之后,数据点之间的距离改变,则对扰动后的数据表进行基于距离的聚类分析所得到的结果会缺乏可信度。相反,若数据隐藏算法能够保持隐藏前后数据记录的距离近似不变,则可以获得较好的聚类可用性[14]。
(2)如何保证真实数据的安全性。
只有同时考虑可用性和安全性这两个指标,才能较好的解决面向聚类的隐私保护数据发布问题。
面向聚类的隐私数据保护问题的研究现状
对于共享数据聚类时的隐私保护问题,目前已有一些解决方法。这些解决方法基本依赖于数据划分和数据失真。文献[2]的研究用于解决数据垂直划分的隐私保护聚类问题,而文献[4]关注数据水平划分的聚类问题。在水平划分中,不同对象在所有站点以相同的集合形式存在;而在垂直划分中,同一对象的属性分布在不同的站点。
文献[2]介绍了一种基于安全多方计算的解决方法。特别的,作者提出了一个k-means聚类方法,适用于不同站点包含大量对象的不同属性的情形。在这种解决方案中,每个站点知道自身属性的聚类,但是不知道其他站点的属性,从而在保证合理隐私的同时限制了交流费用。
数据失真技术也可以用来解决面向聚类的隐私数据保护问题。常用的失真方法有对原始数据进行随机化,扰动处理,对隐私属性进行匿名化处理等。对隐私属性进行匿名化处理即禁止发布该属性,随机化处理即对隐私属性添加“噪声”,发布扰动之后的数据,从而实现保护隐私属性值的目的。在进行随机化处理时,需要保证扰动前后的数据维持统计方面的相关性质不变,方便数据使用者进行聚类分析。
文献[3]介绍的几何数据转换方法主要基于数据失真。这项研究揭示了在进行诸如平移,放缩,旋转这样的几何数据转换之前,如果我们不考虑数据的标准化,那么转换的数据就不能用于隐私保护聚类分析。原因在于使用这三种方法转换数据可能改变了数据点间的相似性,结果导致用于共享聚类的数据不可用。这个研究也揭示了被成功应用于统计数据库中去权衡隐私与安全的失真方法应用在被扰动属性被当做是n维空间的一个向量时是行不通的。通过实施平移,放缩,旋转等变换实现数据的隐藏,但是在数据失真过程中,一些数据点可能会从一个聚类向另一个聚类移动,从而导致误分类的问题。对于文献[3]的研究,一个可行的方向是通过等距变换使数据转换的隐私保护聚类在某种程度上成为可能。例如,在欧几里得空间中移动对象同时保持对象间的距离不变的转换方法。
最近,人们提出了一种基于生成模型的解决分布式聚类隐私保护的新方法。在这种方法中,每个本地站点不是共享原始数据或者扰动数据的一部分,而是建立适合生成模型的参数,这些参数被传递到中心站点。经验表明,这种模型可以通过对隐私属性使用马尔可夫链蒙特卡罗方法生成人工样本而近似。基于生成模型的方法在可接受的隐私泄露和通信费用的情况下实现了高质量的分布式聚类。
本文的研究内容和结构安排
本文利用经典的基于旋转的数据转换(RBT)方法,编程实现一个具有对数值型关系表数据进行隐藏功能的数据隐藏软件系统。本文的研究重点是软件系统的设计与实现的过程,并给出了系统的测试用例。本文的内容按照以下结构安排:
第一章介绍数据隐藏系统实现的研究背景、研究现状和本文结构安排。
第二章介绍数据隐藏系统实现的相关技术,其中重点介绍了RBT数据隐藏方法。
第三章对软件系统进行总体设计,介绍了数据隐私保护系统的一般设计步骤,软件系统的设计流程及设计思路。
第四章介绍了软件系统功能的实现细节,并且使用UCI机器学习知识库的Cardiac Arrhythmia数据库进行系统测试。
第五章分析软件系统测试结果并总结全文。
数据隐藏系统实现的相关技术
数据集中划分的面向聚类数据隐藏技术一般基于数据失真和数据限制发布技术。本文的数据隐藏软件系统是基于RBT方法(基于旋转的数据转换)[1]实现的。RBT方法是一种基于数据失真技术的数据随机化扰动方法。
RBT方法是在文献[3]的基础上改进的,且与文献[3]在一些方面有所不同。首先,与文献[3]中使用平移,放缩,旋转甚至几种变换的组合的方式对聚类数据进行失真的处理不同,仅仅对属性对使用旋转进行失真处理,从而避免数据点的误分类。其次,转换算法支持转换前的数据标准化。对标准化的数据的连续旋转会保护隐私属性值,并且能够得到较为准确的聚类结果。关于RBT方法的安全性,我们发现RBT算法的计算安全性不依赖于形式证明的安全性。相反,它取决于反向转换过程所要求的计算量。
使用RBT方法进行数据隐藏之前,需要将原始数据进行标准化处理,以保证原始数据表的所有属性具有相同的权重。在变换的过程中,可以随机选择两个属性配对,在提供的隐私保护度范围内随机选择转换角度,这样能够实现对原始数据进行较好的保护。
RBT方法能够保证转换前后对象间的距离近似不变,是一种保距的数据转换方法,且具有以下特点:
(1)RBT算法不依赖于任何聚类算法;
(2)RBT算法具有完备的数学理论基础;
(3)RBT算法具有高效性和准确性;
(4)RBT算法既不依赖于较难的代数学假设,也不要求CPU密集型的运算。
基本概念
等距变换
假设T是n维空间的一个变换,例如,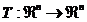 ,T被称作等距变换,如果T满足如下约束:|T(p)-T(q)| = |p-q| 对于任意的
,T被称作等距变换,如果T满足如下约束:|T(p)-T(q)| = |p-q| 对于任意的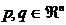 恒成立。
恒成立。
等距变换要在保持角度不变的前提下,把原始点集转换成与之全等的点集。旋转是一种等距变换,且拥有一个旋转中心a,使得对于任意的点p,有|T(p)-a| = |p-a|。RBT方法主要关注旋转变换。为了简化问题,本文使用2维离散空间中旋转的基本概念。在最简单的形式中,这种变换是数据点以坐标原点为中心,关于坐标轴线的旋转。2维离散空间中的一个点的旋转角度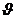 是由如2-1中的公式的变换矩阵实现的,其中旋转角度按顺时针方向。这种变换会同时影响X和Y两个坐标的值。这样在平面二维空间里旋转一个角度,可以在不改变数据点之间的距离的前提下达到改变原始属性数据值的目的。假设原始数据点在2维平面的坐标为(x,y),以坐标原点为旋转中心,则转换后的数据点的坐标为,其中。因此,一个点在2维离散空间的旋转可以看成一个矩阵,用v’ = R v代表,其中,矩阵R是一个2 * 2的旋转矩阵,v是包含原始坐标的列向量,v’是一个列向量,它的坐标是旋转后的坐标。
是由如2-1中的公式的变换矩阵实现的,其中旋转角度按顺时针方向。这种变换会同时影响X和Y两个坐标的值。这样在平面二维空间里旋转一个角度,可以在不改变数据点之间的距离的前提下达到改变原始属性数据值的目的。假设原始数据点在2维平面的坐标为(x,y),以坐标原点为旋转中心,则转换后的数据点的坐标为,其中。因此,一个点在2维离散空间的旋转可以看成一个矩阵,用v’ = R v代表,其中,矩阵R是一个2 * 2的旋转矩阵,v是包含原始坐标的列向量,v’是一个列向量,它的坐标是旋转后的坐标。
(2-1)
数据矩阵
本文实现的数据隐藏系统只针对数值型关系表数据进行隐藏处理。一个数值型关系表通常由若干条记录组成,这些记录可以看成一个个的对象。同时,每条记录又包含若干个数值型属性。
在多维空间中,一个对象(例如个体,模式,事件)常常被表示成点(向量),其中的每一维代表了描述对象的一个不同属性。因此,一个具有m个对象,每个对象有n个属性的数值型关系表可以被表示成m * n的矩阵D,这个矩阵D叫做数据矩阵,它被表示成:
剩余内容已隐藏,请支付后下载全文,论文总字数:48195字
相关图片展示:
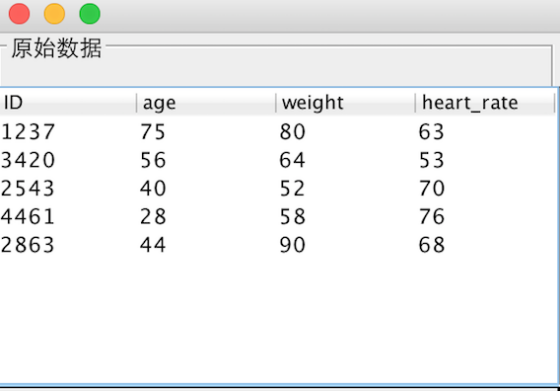
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

