论文总字数:20451字
摘 要
近年来android技术飞速发展,以andorid为平台的智能手机迅速占领市场,逐步超越电脑成为人们获取信息的主要手段。而且伴随着网络上信息量的不断膨胀,传统的被动式搜索获取信息的方式不再能够满足人们需求。因此开发一种结合用户自身兴趣将用户需要的信息推送到用户的移动终端的系统成为当务之急。
本文就是为解决信息量过大用户难以找到自己想要的信息的问题,构建一个文本推送的原型系统。首先我们把推送目标定位人们日常关注的新闻,通过研究相关文本分类技术将杂乱的新闻数据分类管理。然后根据用户兴趣挖掘技术,分析用户兴趣点,构建用户兴趣模型,利用个性化技术生成推荐列表,并对推荐列表运用多样化技术保证推荐结果的多样性,最后将推荐结果发送到用户的移动终端。
本文采用主要技术包括:CHI特征选择、KNN分类算法、SVM分类算法、VSM兴趣模型、
基于互信息的词语相关性技术、基于内容的个性化技术、MMR算法等。
关键词:文本分类、数据挖掘、用户兴趣模型、兴趣推荐
News push technology based on Android
Abstract
In recent years, as the rapid development of Android technology, smart phones based on the Android platform occupied the market quickly, and gradually beyond the computer as the main means of access to information. And along with the information quantity unceasing expansion, the traditional passive search information acquisition way can no longer satisfy people's need. Therefore, it is a urgent matter to develop a system which combines the user's own interest to push the user's information to the mobile terminal.
This paper is to solve the problem that the amount of information is too large to find the information they want by building a text push prototype system. First, we choose news as the information to push, through the study of the relevant text classification technology we can make the mixed news in order. Then based on user interest mining technology, analysis user interest point, build user interest model, generate a list of recommendations by the personalization technology, and using diversified technology ensure the diversity. Finally,push the recommended results to the user's mobile terminal.
The main techniques include: CHI feature selection, KNN classification algorithm, SVM classification algorithm, VSM interest model,The relevance technology based on mutual information, personalized technology based on content, MMR algorithm, etc..
Keywords: text classification, data mining, user interest model, interest recommendation
目录
摘要 II
Abstract III
第一章 绪论 1
1.1引言 1
1.2论文的主要工作 1
1.3论文组织结构 1
第二章 系统总体结构 3
2.1系统功能划分 3
2.2本章小结 4
第三章 文本分类 5
3.1文本信息模型 5
3.2文本分词 5
3.3特征提取 6
3.3.1CHI算法 6
3.3.2考虑上下文信息的特征选择 8
3.4特征向量权值计算 8
3.4.1特征选择和权值计算的区别 8
3.4.2TF-IDF算法 9
3.4.3上下文关系的权值计算 9
3.5分类算法 9
3.5.1knn算法 10
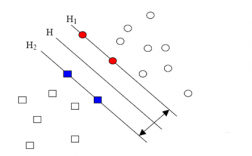
3.5.2svm算法 11
3.6knn算法与svm算法结果分析 12
3.7本章小结 13
第四章 用户兴趣挖掘技术 14
4.1模型数据提取 14
4.2用户兴趣模型 14
4.3模型更新算法 15
4.3.1新闻主题提取 15
4.3.2更新策略 15
4.3.3个性化推荐技术 16
4.4本章小节 17
第五章 实验环境及实验结果分析展示 18
5.1开发环境 18
5.2实验数据 18
5.3实验结果分析 18
5.4本章小结 20
第六章 总结与展望 21
致谢 22
参考文献 23
第一章 绪论
1.1引言
随着信息技术的不断发展,在上世纪八十年代,信息翻倍大约需要一年半,到了九十年代这个时间明显缩短,进入2000年全球的数据总量达到300万TB,而到了今天,我们已然进入一个大数据时代。数据越来越多,人们就将面临数据过剩的压力,传统的被动式检索信息的方式在某种意义上不再适用海量的数据模式的要求,与之相对的推送技术成为主流。
顾名思义Push技术就是服务器主动为用户推送信息而不需要用户自己去搜索,在这个过程中用户是被动的。与传统检索获取信息相比,push技术拥有效率高、费用低、事实性强和用户体验好等有点。将push技术与用户兴趣挖掘技术相结合,只推送用户感兴趣的内容,可以进一步提升push技术的用户体验[1]。
Android系统自推出以来,就以明显的优势逐渐扩大自大的市场份额,尤其在国外,正处于蓬勃发展的开拓阶段。据美国某市场调研机构2012年发布的一份最新报告显示。2012年一季度在美国,基于Android系统的智能手机的销售量已占据全美手机销售量的28%份额,而IPhone手机其市场份额紧追其后,占到21%的市场份额,已经确定了Android系统的市场占有比。据业内人士分析,随着Android系统相应软件的不断开发应用,选择Android系统手机或者无线终端设备的人会越来越多,其市场霸主的地位在更新更好的系统出现之前是不可动摇地。中国是世界上最大的手机销费国。当前国内手机市场正在快速向智能手机推进,而Android系统无疑是最大的市场需求。 [2]。
因此面对目前的市场需求,本文研究基于android平台的推送技术。以新闻作为推动的主体,考虑新闻载体特点,结合文本分类、兴趣挖掘以及个性化等相关技术,模拟一个符合市场需求的推荐系统。
1.2论文的主要工作
本文主要研究实现一个新闻推荐系统,并将其移植到android平台,在移动终端使用。
(1)本文选取网易新闻中心的新闻作为处理数据,先对原始新闻进行分词、选取特征等预处理工作,考虑新闻载体的特点,利用上下文技术借助几种经典的分类器完成新闻分类。
(2)用户兴趣提取是影响推送结果的重要因素,本文以vsm用户兴趣模型为基础建立两层vsm兴趣模型,以期更好的适应复杂的用户兴趣。
(3)用户使用系统会产生日志文件,通过分析日志文件,借助反馈更新机制实时的更新的用户兴趣。
(4)每当用户登录,读取用户兴趣,计算待推送新闻与用户兴趣的相似度,将结果排序按照推送策略进行推送。
1.3论文组织结构
第一章 选题背景和主要工作
第二章 系统的整体结构
第三章 文本分类相关技术
第四章 用户兴趣模型建立及推送策略
第五章 实验环境及实验结果分析展示
第六章 总结
第二章 系统总体结构
2.1系统功能划分
本系统主要由四个部分,数据预处理部分,用户交互部分,用户兴趣挖掘部分,推荐部分,系统结构图如下:
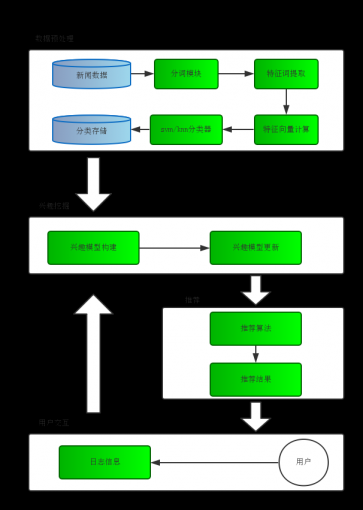
图2-1 系统总体结构
1.数据预处理
本系统处理的基础数据是来自网易新闻中心的新闻数据,爬取300多篇实时新闻,按照标题加内容的形式存放到本地磁盘用于后续处理。预处理的内容主要包括使用中科院的中科院ictclas将新闻文本数据分词,采用CHI算法选取特征值,通过计算特征值的TF值来确定特征向量,最后通过libsvm和knn分类器实现新闻文本的初分类。为了使分类结果更加准确,本文主要从特征选择方面入手,考虑新闻标题高度概括文章主题的特点以及考虑词语之间的上下文关系,利用互信息的相关方法使选取特征更具代表性。
2.用户交互
该部分主要负责系统服务器与用户交换信息,本系统是在移动客户端使用,是基于android系统的信息交互,客户端向用户展示推送的新闻,用户可以点击相应标题浏览新闻全文,同时客户端会向服务端发送用户的浏览记录以便形成访问日志。
3.用户兴趣挖掘
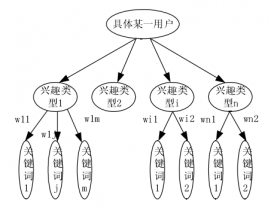
该部分主要是建立用户的兴趣模型并根据日志信息定期更新用户模型,本文采用基于VSM的双层兴趣模型,第一层兴趣为我们通过预处理之后得到的分类结果,第二层分类则是在每一个分类内部构建的兴趣关键词列表。兴趣模型更新部分则根据日志信息采用简化之后的Rocchio反馈模型计算得出新的用户兴趣关键词和权值。
4.推荐部分
该部分主要用于在检测到用户登录之后,根据建立好的用户兴趣模型,读取出兴趣向量,计算当天新闻与兴趣向量的相似度,排序之后将拥有最高相似度的新闻推送给用户。
2.2本章小结
本章主要介绍系统的整体功能结构,针对系统的各个模块分别进行简要的描述,在后续章节将详细介绍相关技术。
第三章 文本分类
3.1文本信息模型
计算机不可能像人一样直接处理原始的文本数据,因此就需要找到一种模型将复杂的文本信息转变成计算机可以处理的格式化的数学信息,并且最大程度的保证信息的完整性。目前最为常用的文本信息模型有三种:
(1)布尔模型
该模型主要基于布尔代数理论,如果某一特征在文本出现则权重置为1,反之则为0。这样一篇文章就会被表示成布尔表达式,文章中的词都是与的关系。但是布尔表达式有时构造比较复杂,如果构造规则过于严格那么会使得日后匹配结果太少,如果构造过于简单则会导致相关度不高。
(2)概率模型
该模型通过依次计算将一篇文本归类到所有类的条件概率,然后将条件概率排序,排名最靠前的就是我们认为的该文本所属的类。
(3)向量空间模型
该模型目前是信息检索领域最为经典的模型,被广泛用于与众多经典问题。本文设计的分类系统也是基于这种模型。
向量空间模型将文本表示成一个N维向量,每一维由一个特征表示,也就是说,选取N个特征来表示一篇文章,每一维的值反应了该特征相对于这篇文章的重要程度。向量空间模型的一般构造过程图3-1所示:
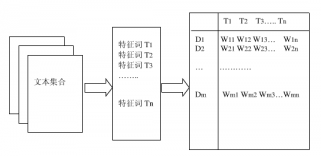
图3-1向量空间模型构造流程图
3.2文本分词
对文本进行处理我们可以将其分为句子、词语或者是单个字,他们都可作为文本的基本单元用于分类,但是通过阅读资料,用词作为文本的基础单元分类效果是最好的,本文就是采用词来作为基本单元。中文文本不同于英文文本可以通过词语之间的间隔来划分词语,中文文本的分词通常分为三类[3]:
1.基于字符串匹配
顾名思义,该方法需要给定一个词典,按照相关的方法将需要被分析的字符串与字典中的给定词相匹配,若两者能够吻合则匹配成功。
2.基于理解
该方法则是模拟人的思维,不仅要分词还要进行语法分析,这就需要大量的汉语语言信息。我们都知道汉语语言体系非常庞大而且复杂,很难将所有的语言信息都标准化之后交给机器学习,所以这种方法目前还处于试验阶段。
3.基于统计学
统计学的方法用于处理分词这也是目前最为常用的方法,主要思想是如果两个字在文章中相邻出现的次数越多则这两个词就越可能构成一个词,可以通过设定一个阈值,当两个字的联系大于该阈值则判定它们构成一个词。
本文在分词部分是直接使用中科院的ICTCLAS分词系统的java包。该系统是目前公认比较好的汉语分词系统,主要采用了层叠的隐马尔可夫模型,将汉语体系映射到完整的理论框架中,做到了分词效果和分词速度最优组合,不仅如此该系统还提供词性分析、命名词语识别以及支持用户词典等功能。
经过ICTCLAS分词之后,并不能直接用于特征提取,一般而言名词和动词最能代表文章的主旨,而像“我”、“他”、“的”、“不但…而且…”等人称代词、助词及关联词则没有任何实际意义,因此我们需要将这部分词去除掉。
ICTCLAS的强大之处也在于它可以给我们进行词性标注,本文就根据词性标注结果,只保留含有最多信息的名词部分。另外考虑到新闻文本的特殊性,本文还构建了自己的分词词典,用于去除新闻文本中诸如数字、新华社一类的词以减少无关词语对后续试验的影响。
3.3特征提取
在文本分类领域把用于表示文本的基本单位成为特征,特征具有能够标识文本内容、区分文本差异、数量少以及便于提取等特点。上文中提到我们通过分词之后得到每篇文本的词集,词集的中的所有词都可以称作该文本的特征词,但是一篇文本经过分词和去除无关词处理之后通常还是剩余几十到数千个词语,如果把所有的词语都作为特征词会使得空间向量的维数会非常庞大,不利于后续的处理,因此我们需要对词语集合进行降维。目前降维的方法分为两大类特征抽取和特征提取,区别在于特征抽取是对现有特征集的进一步概括,可能会用一个新的词语来表示特征,也就说新的集合T’不会原来集合T的子集;特征提取则是选取现有特征集合中最具代表性的部分词语作为新的特征集,也就是说新的特征集T’是原来特征集的子集。
3.3.1CHI算法
在文本分类领域,由于文本特征集本身维数比较高而且相对复杂一点,特征抽取的方法算法本身计算复杂度可能会比较高不适合用来降维,因此我们选用特征提取的方法来降维。常用的提取方法有互信息、CHI、文档频率和信息增益等。这些方法各有优劣,本文通过比较之后,选择CHI最为最终的特征选取算法。
剩余内容已隐藏,请支付后下载全文,论文总字数:20451字
相关图片展示:

该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

