论文总字数:28696字
摘 要
搜索服务是计算机领域,尤其是互联网应用领域的基本需求。但是随着互联网的发展,资源的海量增长,搜索服务面临着越来越复杂的功能要求。目前的通用搜索引擎无法满足用户差异化的定制,而其他搜索服务都基本作为某个系统的一部分,耦合性高,无法抽离作为单独的服务,再次使用时需要根据新的需求设计新的搜索方案。
本文针对这一需求,描述了这种第三方自定义搜索云服务的设计与实现,分别从索引、搜索等部分入手,研究现有方案的优点与不足,分析其难点与解决方案,并且详细阐述了这一系统的架构设计与接口设计,设计了完善的安全机制与管理界面,最后对系统进行测试,验证其功能的完整性。
关键词:搜索引擎,云服务,RESTful API
Abstract
Search service are widely used in computer science, especially in the field of Internet. A massive resource are generating with the development of Internet. And there are some complex requirements before it. And now, the general search engines can not meet customization differentiated. Meanwhile, the rest of them are as a part of a large system, the coupling is high so that the service can not be independent. So it requires the design of new solution according to the new requirements.
In this paper, to meet the requirements, design and implementation of such third-part custom cloud search service. Separately from the indexing, searching and other, I studied the advantages and disadvantages of existing programs, analyzed the difficulties and solutions for different steps. Then I describe in detail the architecture of the system design and interface design, and the design of the entire security mechanism and management interface. Finally, the performance of the whole system is tested to verify its requirements.
KEY WORDS:search engine,cloud service,RESTful APII
目录
第一章 引言 1
1.1 选题背景和意义 1
1.2 研究现状 1
1.3 课题主要内容和难点 3
1.4 论文组织结构 4
第二章 需求分析 5
2.1 资源组织 5
2.2 RESTful API 6
第三章 系统设计 7
3.1 系统架构设计 7
3.2 系统接口设计 8
3.3 安全机制设计 21
3.4 图形化管理界面 23
第四章 系统实现与测试 24
4.1 系统开发环境 24
4.2 系统各部分实现 25
4.3 系统测试 30
第五章 总结与展望 35
5.1 总结 35
5.2 展望 35
引言
搜索服务是诸多计算机领域,尤其是互联网应用领域的中基本需求,本章将分析搜索云服务的意义,针对当前的技术与解决方案进行阐述,将简单阐述本课题设计的主要内容,分析其技术难点。
1.1 选题背景和意义
由于计算机技术的不断发展和应用软件的逐渐成熟,一种新的软件应用模式渐渐兴起——SaaS(Software as a Servic,软件即服务),这是一种通过Internet交付软件的新模式,开发好的应用软件部署在服务商自己的服务器上,通过单一或者多种收费模式将软件租借给客户使用,客户按照功能需求按需购买,随需应变,节省了自己的时间成本以及运维成本,没有了传统软件的缺点,SaaS为客户带来了更良好的体验以及更低廉的价格,比如专注非结构化数据存储与分发的又拍云、七牛云存储,专注服务监控的监控宝、阿里云监控,专注即时通信的融云、环信等,就像在线音乐取代了传统碟片一样,随着技术的进步SaaS终将取代传统的软件交付模式。
Web 2.0 的出现造就了目前互联网的海量资源,由于企业对自身资源的管理需求以及用户对资源的查询需求越来越强烈,使得搜索功能越来越复杂,相应的对企业的技术要求也越来越高,在之前经手的许多项目中,都遇到了“要提供搜索功能”的问题,在试用了各种不同的搜索引擎解决方案之后才逐渐意识到,这样的工作,就和CDN服务、监控服务、长连接推送服务等等一样,如果有一个专门的团队提供服务,由他们去调试、优化、运维,开发者就能只需要专注于自己核心功能的实现。对双方来说都节省了大量的成本,这些成本包括昂贵的硬件设备、人力资源以及时间投入。由于规模经济效益,每个客户的租赁费用并不高,但是开发出的应用可以供给成千上万的客户,随着量级的增加,其经济收入也十分可观。搜索服务的提供商只需专注于搜索功能性能的优化,客户无需投入大量资源即可快速得到性能出色的搜索引擎。
1.2 研究现状
谈到搜索引擎,不得不提的就是Google与百度,分别作为全球最大的搜索引擎和最懂中文的搜索引擎,无论是Google还是百度以及其他等等通用搜索引擎都免费开放了Custom Search功能,从稳定性和易用性上来说,他们都达到了一个很高的高度,但是相对于本课题中的搜索服务来说,其弊端有二:
- 这些通用的搜索引擎无法及时索引网站的最新内容,对于餐饮、电商等一些时效性(优惠时间、价格等)较强的网站来说,这是致命的缺陷,用户不应该查到过时的信息。
- 作为通用搜索引擎,通用意味着缺少变化,其展现搜索结果的方法也是相同的,不能够按照客户自身的业务特性去做排序、过滤、展示,缺少差异化是其最大的弱点。
因此,一个第三方自定义搜索的云服务是很有可能在搜索的准确度和结果的展示效果上击败传统的通用搜索引擎的。
为了方便描述,这里还有几个相关概念需要了解,搜索的流程简单来说分为两部分,索引和搜索:
- 在索引环节,需要将待搜索的资源提交到搜索引擎中,搜索引擎对其做相应处理,例如要对博客里的文章提供搜索功能,需要将博客里的文章提交到搜索引擎中,我们把“将待搜索的资源提交到搜索引擎中”的过程称为索引资源,简称索引(indexing)
- 在搜索环节,向搜索引擎提交要搜索的内容,比如一些关键词,搜索引擎会在前一步中索引的资源里进行搜索,返回符合搜索要求的资源,比如返回一系列的文章。值得注意的是,自动补全是一种特殊的搜索,在不引起歧义的情况下,我们所说的搜索包含自动补全。
这两部分是必不可少的,下面对已有的索引、搜索解决方案逐一描述。
1.2.1 索引
搜索引擎最重要的一部分就是索引程序,工程实现的索引程序的解决方案非常多,有基于SQL 的Sphinx,有由Java实现的Lucene,以及基于Lucene的Elastic,它们不是完整的索引程序,而是索引程序的架构,其中:
- Sphinx与Lucene是同一纬度的竞争对手,较为底层。Sphinx通过使用MySQL、PostgreSQL 等传统的关系型数据库做索引,直接与数据库协作使得其建立索引的速度非常快,进程占用资源极小[4]。Lucene出自名门,是Apache软件基金会jakarta项目组的一个子项目,相比Sphinx与数据库协作,Lucene的索引文件格式是跨平台的,其索引文件格式以8 bit为基础独立于平台之上,所以应用能够轻松的跨平台共享索引文件,并且在倒排索引的基础上实现的分块索引极大的提升了索引速度[5]。在仔细研究了Sphinx和Lucene的相关文档之后,我发现在项目中集成Lucene或Sphinx并不容易,或者说如果想要提供一个相对比较健壮的服务来说,需要一个很好的架构设计,需要时刻留心很多细节。
- Elastic是基于Lucene的一个程序架构,提供了一套分布式解决方案,本身并没有做索引的功能,其索引部分使用Lucene完成,然后将Lucene分布式化,拥有比较先进的分布式模型,包括了分布式索引、自动分片、索引的自动负载[6]等等,极大的方便了水平扩展,同时Elastic使用了HTTP和类似JSON形式的DSL作为API,使得系统独立于语言之上,无论什么编程语言都可以轻松的调用它。
1.2.2 搜索
在针对中文的搜索中,一个重要的挑战就是中文的分词问题,从理论算法上讲目前大致可以分为两类:
- 基于字符串匹配,通过对字符串进行逐步扫描寻找与搜索内容相同的子串。这个类型的分词算法会在实现时加入启发式匹配规则,比如“基于正/反向最大匹配”以及“长词优先”等规则,这类算法的优点在于实现较为简单而且运行速度快,但是当出现歧义或者出现字典中未曾出现的词时无法很好的处理结果。
- 基于机器学习的分词方式,这类分词算法通过一些训练样本对中文进行建模,根据训练数据计算模型参数,在分词阶段再经过训练时得出的模型参数计算出各个分词可能的概率,常见的模型例如“隐马尔科夫模型(Hidden Markov Model,HMM)”、“条件随机场(Conditional Random Field,CRF)”等,这类算法的优点在于能够很好的处理歧义以及词典中未出现的词,分词效果要准确与基于字符串匹配的算法,但是在实现时需要事先由人工标注大量训练样本并且计算模型参数,而且分词速度低于基于字符串匹配的算法。
1.3 课题主要内容和难点
根据以上研究现状的比较和分析,本课题将设计并实现一个第三方自定义搜索云服务系统。该系统将解决用户结构化数据搜索需求的托管服务,支持自定义数据结构、可以对结果进行排序、对行为进行分析,并提供一整套涵盖从创建、索引到搜索的方方面的RESTful API。
要实现以上功能,还从在以下主要的技术难点:
- 海量数据在数据库中查询效率低下的问题。传统数据库采用B-Tree索引,在查找过程中,只有前缀查找(prefix)能够使用索引,而其他搜索过程均无法使用索引,导致查询性能下降,而且数据库无法进行针对搜索引擎的制定优化,通常搜索引擎使用的是多级分布式存储的倒排索引作为其结构。
- 中文搜索中关于中文分词的问题。中文搜索的分词问题其根本问题是一个如何消除歧义的过程,目前解决这个问题的理论算法大致有基于字符串匹配的分词方式以及基于机器学习与统计的分词两种,工程实现也有较多选择,目前主流的实现有ikanalyer,paoding 以及ICTCLAS,其中ikanalyzer与paoding都是是基于字符串匹配这类算法的分词工程实现,ICTCLAS则是是基于机器学习分词方式中隐马尔科夫链算法的分词工程实现。在生产环境中应该根据不同的需求应该选择不同的算法,比如在搜索框输入自动补全的部分,着重考虑的是速度快、兴趣相关,分词算法的准确性在其次,而像全文搜索这样在大篇幅的文字中搜索需求则更注重的应该是精确,速度反而在其次。
- 搜索结果的排序问题,搜索结果的排序是一个重要的问题,排序的结果直观的反映了一个搜索引擎的性能,全球最大的搜索引擎Google正是凭借其出色的排序算法PageRank奠定了其互联网巨头的地位,其基本思想是“一个网页如果有很多优质网页都链接向了它,则它必定是优质网页。”,但对于本课题中的搜索引擎而言,某一个网页的PageRank 值并不能很好的决定其排名,因为我们无法像Google一样计算出一个全局的PageRank值,所以还需要结合一些Related-Rate算法才能较好的解决这个排序问题。
1.4 论文组织结构
论文分五个章节来阐述第三方自定义搜索云服务系统的设计与实现:
第一章为引言,阐述了课题的背景与意义,对于目前计算机领域搜索服务研究现状以及本课题方案设计内容和技术难点分别进行阐述。
第二章为需求分析,包括了系统功能性需求分析。
第三章为系统设计,包括了系统架构、数据库、系统接口、安全机制设计等。
第四章为系统的实现以及测试,包括各个功能模块的实现以及测试。
第五章为论文的总结,主要对本课题工作进行总结,提出了可以进一步完善的内容以及可能。
第二章 需求分析
本课题设计系统的主要功能是通过RESTful API提供资源的索引、搜索以及分析。下面分别进行阐述:
2.1 资源组织
搜索服务的最基本需求是实现索引与搜索资源的组织,一方面要保证其在大规模数据下的索引效率,方便扩容;另一方面是要保证搜索的响应速度,具有良好的柯水平扩展性,因此本课题中将资源按照Engine、Collection和Document三个层面进行组织,如下图。

Engine
Engine是资源组织结构中最顶层的概念,类似于MySQL中的database,MongoDB中的db,S3中的Bucket。
每个Engine有一个name,为全局唯一,可由字母、数字以及‘-’构成。另外每个Engine有一个engine_key可用于调用搜索API时指定Engine。
Collection
Colletction定义了Document的‘schema’,包含了拥有同构‘schema’的一系列Document,类似于MySQL中的Table,MongoDB中的collection。
每个Collection有一个name,在同一个Engine中唯一,可由字母、数字和‘-’构成。另外每个Collection还有一个field_types,描述了所包含Document的‘schema’。例如:
{
"title": "string",
"tags": "string",
"published_date": "date",
"url": "enum",
"body": "text"
}
表示Document由‘title’、‘tags’、‘published_date’、‘url’、‘body’这些field组成,每个field的类型(type)分别是‘string’、‘string’、‘date’、‘enum’、‘text’。
field_types详细列表见系统设计章节。
Document
Document对应于具体的一个个资源,类似MySQL中的record,MongoDB中的document,每个Document拥有一个id,以及符合所属Collection中规定‘schema’内容。
2.2 RESTful API
REST(Representational State Transfer 表现层状态转化[1])是Roy Thomas Fielding在他2000年的博士论文中提出的。如果一个架构模式符合REST原则,则称其为RESTful架构。RESTful API让使用者可以通过正确的方法修改服务器中的某种资源或者进行操作。简单来说就是通过URL定位资源,客户端与服务端传递该资源的某种表现层使用HTTP动词(GET、POST、PUT、DELETE)对资源进行操作实现表现层的状态转化。
在系统实现过程中,首先要确保RFC一致性,在请求的处理与响应的过程上应该符合HTTP/1.1 的RFC标准以保证接口间的一致性,本课题中需要着重考虑RFC中对请求method/head以及响应status code的一致性。
由于RESTful API将资源和操作暴露给了外界所以其安全性非常重要。安全并不单单是指加密或解密,而是要保证一致性(integrity)、机密性(confidentiality)和可用性(availibility)[8]。
第三章 系统设计
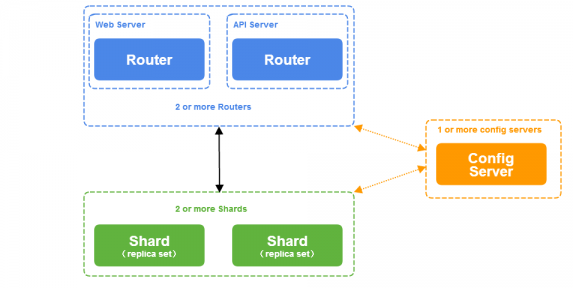
3.1 系统架构设计
根据需求分析,本课题设计系统采用传统的三层架构模式,由接口层,应用层和资源层组成,如果图所示

- 接口层
向本系统发送请求的可能是浏览器、移动客户端以及服务器等,这些请求通过Web Server与API Server两种接口实现功能性访问,用户通过Web Server可以使用图形化界面管理后台实现索引、搜索与分析功能,或者使用更加通用的API Server实现更加复杂的功能,API 严格按照REST标准设计,通过多台机器启动多个Nginx实例进行负载平衡可以实现本层的水平扩展。
- 应用层
应用服务器使用Ruby on Rails框架,每个应用服务器都包括了用户的身份认证、资源索引、搜索、分析等业务功能。使用Ruby on Rails以MVC方式组织代码,使得整个系统的层次变得更加清晰,同时也降低了耦合度,提高了代码的质量与复用率,通过多台机器启动多个unicorn实例可以实现本层的水平扩展。
- 资源层
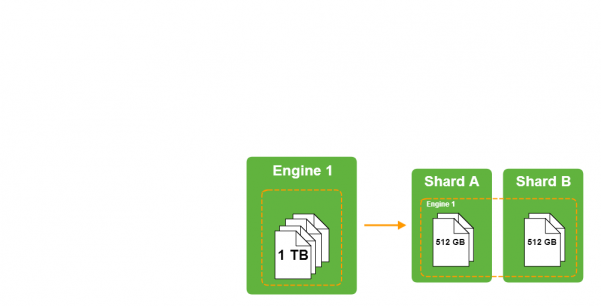
所有被索引、待搜索的资源都存储在资源层,根据2.1.1资源的组织方式进行存储。通过大量的对比研究,本系统使用Lucene定义的索引文件格式对资源进行索引,通过Elastic对本层进行水平扩展。
3.2 系统接口设计
本系统中所有接口均为RESTful API符合HTTP/1.1标准保证了接口的一致性。HTTP RFC中将不同的动词来区分不同的动作,其中:
- GET用于获取获取某个资源,需要满足幂等性而且无副作用。
- POST用于创建一个新的资源。
- PUT用于替换某个已有的资源,需要满足幂等性。
- DELETE用于删除某个资源,需要满足幂等性。
一个操作符合幂等性的意思就是说资源在相同的请求和参数下执行一次或多次产生的效果是一样的。
本系统所述基础URL均为:
剩余内容已隐藏,请支付后下载全文,论文总字数:28696字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

