论文总字数:26982字
摘 要
随着互联网的普及,全球信息技术的蓬勃发展,面对出现的海量数据,如何通过利用大量的原始数据来进行现状分析和未来预测,已经成为人们面临的一大挑战。由此数据挖掘技术应运而生,得到迅猛发展。
ID3算法是数据挖掘中一种经典的决策树学习算法。该算法由J. Ross Quinlan在1975提出,它选取信息增益作为属性选择的标准。由于ID3算法趋向于选择取值较多的属性,本文介绍了一种基于ID3算法的改进算法。新算法引入了信息增益率来进行属性选择。另外扩展的算法也支持对连续属性的处理。
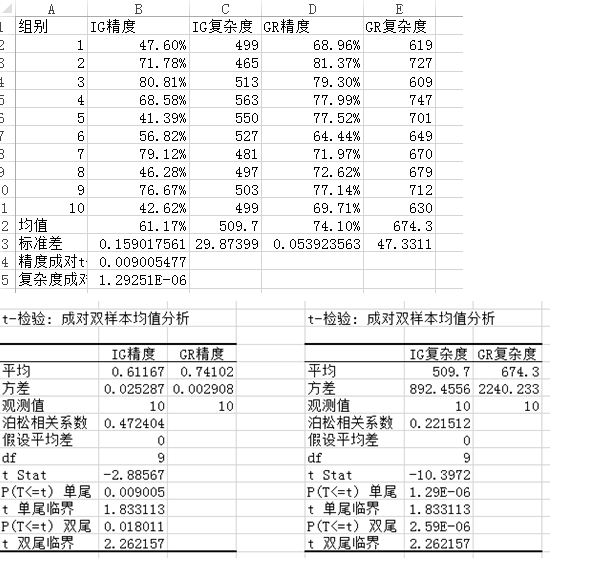
本文分别实现了基础ID3算法和扩展的算法,并通过一系列数据集进行后续实验两者之间的差异。实验首先从UCI机器学习数据库整理了10个数据集并将其划分为训练集和测试集,然后通过对数据集的训练和测试记录两种算法的分类精度和模型复杂度,最后通过成对t-检验的方式在统计意义上检验这两种算法是否有显著区别。
关键词:数据挖掘 决策树 ID3算法 信息增益 信息增益率
The design and implementation of decision tree algorithm based on information gain
Abstract
With rapid popularization of Internet, the vigorous development of the global information technology, how to investigate current status and forecast the future with good use of tremendous original data has been becoming the big challenge to human beings. Consequently, data mining technology emerge and boom quickly.
The ID3 algorithm is a classical learning algorithm of decision tree in data mining. J. Ross Quinlan proposed the ID3 algorithm in 1975. The algorithm chooses the attribute by information gain. The ID3 algorithm trends to choosing the attribute with more values, so the paper introduces an improved ID3 algorithm. The improved algorithm introduces the importance factor gain radio when choosing the attribute. In addition, the improved algorithm supports the processing of continuous attributes.
The paper implements the basic ID3 algorithm and improved algorithm and uses a series of data sets to compare the differences between the two algorithms. First, the experiment coordinates 10 data sets from UCI Machine Learning Repository and divides them into training sets and test sets. Next, the experiment records the precision and model complexity of the two algorithms. Finally, the experiment tests the two algorithms by pairwise t-test in a statistical sense whether they have a significant difference.
KEY WORDS: Data mining, Decision Tree, ID3 algorithm, Information gain, Gain radio
目录
摘要 II
第一章 简介 1
第二章 决策树算法 4
2.1、决策树 4
2.2、ID3 算法 6
2.3、ID3 算法扩展 9
第三章 算法实现 10
3.1、算法代码结构描述 10
3.2、相关难点及其解决方案 14
3.3、具体算法描述 14
第四章 实验分析 18
4.1、数据集介绍 18
4.2、实验结果 19
4.3、实验结果分析 29
第五章 结束语 32
参考文献 33
第一章 简介
决策树算法是数据挖掘中经常使用的一种方法。在介绍决策树之前,首先将对数据挖掘做一下简要的介绍。
1.数据挖掘技术的背景
计算机技术的发展为大规模数据的存储提供了条件,数据库技术广泛应用使数据的积累量急剧增长,互联网技术的成熟让世界各地的人们能方便的生活沟通和信息交流 。海量的数据带给来了便利,但也同样会带来许多负面的影响。这时人们迫切需求一个能深入分析浩如烟海的数据并能发现其中有效的信息加以利用的技术。数据挖掘技术在这样的背景下应运而生。
2.数据挖掘的概念
在数据挖掘之前,首先需要了解一下知识挖掘。知识挖掘,又称为数据库中知识发现(Knowledge Discovery from Database,简称KDD),它是一个从大量数据中抽取挖掘出未知的、有价值的模式或规律等知识的复杂过程,而数据挖掘是整个知识挖掘过程中的一个最主要步骤。数据挖掘作为一门交叉学科结合了数据库技术、机器学习、统计学、模式识别和人工智能等多个领域的技术。
3.数据挖掘的发现模式
数据挖掘根据其发现模式可以分为预言型数据挖掘和描述性数据挖掘。
- 预言型数据挖掘
a.分类模式
分类需要做是对数据进行学习并用于数据测试。分类模式通常在训练集上进行训练并使用训练所得的模型进行测试和新数据分类。而本文着重讲的决策树就是一种常见的分类模型。例如预测不同客户对某种商品的购买倾向、不同病情表现患者的疾病类型和不同外界环境下的机械运行状态等等。
b.回归模式
回归模式与分类模式类似,而其中的区别为回归使用连续属性而分类使用离散属性。最基本的回归模式采用的是线性回归统计技术,一些其他问题也可以通过一定的方式转化为线性问题。但即使如此,回归模式在很多问题解决上都会存在一定的局限性。
c.时间序列模式
时间序列根据数据所处不同时间的状态来建立模型。时间序列模式是在持续的时间流内根据所发现的时间间隔截取时间窗口,每个窗口内的数据作为一个单独的数据单元,然后对多个训练模型产生的训练集进行学习。
- 描述型数据挖掘
a.聚类模式
聚类是将数据分成多个数据有明显差别的类,而一个类中的数据则尽量相似。与分类模式不同,聚类模式的分类规则按照系统的某种性能指标自动确定。
b.关联分析模式
关联分析模式寻找的是数据库中值的相关性。与时间序列模式寻找事件之间在时间上的相关性类似,关联分析模式寻找的事不同项在同一事件上的相关性,比如一次旅行计划中不同旅行地点的相关性。
c.变化和偏差模式
偏差代表的反常实例、模式例外,结果对期望的偏差等,目的是为了寻找结果与参照值间差别,这种差别有的时候会比正常值有用得多。这种偏差数据的挖掘可以应用到异常信息的获取、分析和评测等方面,例如在评测安全系统的性能时,开发者显然更关心的是少量会产生安全隐患的信息。
4.数据挖掘方法
由于数据的形式多种多样,在处理不同数据时使用的数据挖掘方法也不尽相
同,下面将简要介绍几种数据挖掘中常用的方法。
- 决策树:决策树是一种常用的用于分析和预测数据归纳学习方法。决策树算法因为分类方式的不同而多种多样,常用的算法有CHAID、CART、ID3和C4.5等。决策树的优点是方便直观便于预测,缺点是会随着数据量的增大和复杂性的提高产生庞大的分支,最终导致其实现和管理都变得非常困难;
- 模糊方法:系统复杂程度的增加导致其模糊性增加。通过建立模糊函数并进行模糊推理从而得到系统的大概变化趋势;
- 神经网络:人工神经网络通过模拟人脑神经元的结构,通过对连接神经网络的代表知识的权值逐步计算进行学习。神经网络主要用于回归模式和分类模式,有较强的健壮性和容错性。但神经网络模型的封闭性导致其预测很难理解,另外算法对数据的多次读取也导致其学习时间过长;
- 概念树:数据集属性进行归类抽象建立起的结构称为概念树。概念树是对大数据集的简化使其更容易理解,然后再对高度概括的知识进行挖掘;
- 遗传算法:遗传算法是一种模拟生物进化的优化方法,通过选择、重组和突变完成进化逐步获得最优解。遗传算法比较适用于分类学习和优化计算;
- 证据理论:证据理论是一种不确定的推理方法,这一理论有直接表达不确定和不知道的能力。在处理不确定性方面的优势使证据理论在信息融合和专家系统中广泛应用;
- 公式发现:通过对变量进行发现学习通过数据驱动方式或模型驱动方式求得相应的公式。经典的公式发现系统有科学定律发现系统BACON和数学概念发现系统AM。
5.数据挖掘的应用与发展趋势
数据挖掘为实际应用而生,目前已经在很多领域应用广泛。其的典型应用领域包括:
- 市场分析和预测;广播的听众调查调查、便利店的销售预测、商品销售渠道的分析等;
- 工业领域;生产过程分析与优化、产品质量预测、生产系统故障排除等;
- 金融领域;投资管理系统、银行利率分析指导、证券客户需求分析等;
- 科学领域;DNA序列分析、天体的发现、分析地壳的构造活动等;
- 网络领域;网站访问模式分析、网络关联和序列模式分析、网页内容自动分类等;
- 医学领域:患者病情分析与预测、药物适应性研究、专家系统等。
6.数据挖掘的发展趋势
由于数据、任务和方法的多样性,数据挖掘在发展过程中将面临许多困难。而现今数据挖掘所面临的困难也正指明了其自身的发展方向。在将来数据挖掘研究可能会向以下几个方面发展:
- 数据挖掘描述语言的标准化。标准化的数据挖掘语言可以让用户与挖掘系统之间有更好的交互,同使也保证了数据挖掘过程的规范性和可移植性。但是相对于数据库系统,数据挖掘系统的过程要复杂得多,其语言标准化的过程将会较为曲折;
- 数据的高度整合。目前数据挖掘过程绝大部分时间都用到了数据的预处理部分,这大大降低了数据挖掘的效率。数据仓库、互联网和数据库信息的高度整合将是数据挖掘系统的最理想结构,这将使数据挖掘过程有更高的效率、性能和准确性;
- Internet数据挖掘。互联网在生活中扮演的角色越来越重要,人们日常的沟通和交易将越来越多的在网上进行。数据挖掘技术在电子商务等方面的潜力巨大,通过对客户交易记录文件和浏览统计文档的分析和预测,可以提高商业网站与客户之间的关联性。相对于传统的数据,internet数据知识挖掘的侧重点也会有所差别;
- 生物信息或基因的数据挖掘。对生物信息和基因的研究对人类来说意义重大,但是生物信息或基因的数据挖掘和通常的数据挖掘相比,无论从数据的复杂程度、数据量还是分析和建立模型的算法来讲都要更加复杂。这同时也要求探索对复杂类型数据进行挖掘的新方法。
第二章 决策树算法
决策树算法是一种典型的数据挖掘分类算法,首先对数据进行处理,利用归纳算法生成可读规则和决策树,然后使用决策树对新数据进行预测。
2.1、决策树
决策树(Decision Tree)是一种简单直观的分类预测模型。通过对数据集的学习构建决策树,可以对未知数据进行有效的分类。决策树是数据挖掘的常用技术,可以用于对数据的分析和预测。
1.决策树简介
决策树是一种树形结构图,每个内部结点代表测试一个属性,每个分支代表一个测试输出,每个叶结点代表一种类别。汤姆.米歇尔的《机器学习》一书中给出了一颗如图2.1典型的决策树,根据天气情况分类“星期六上午是否适合打网球”。
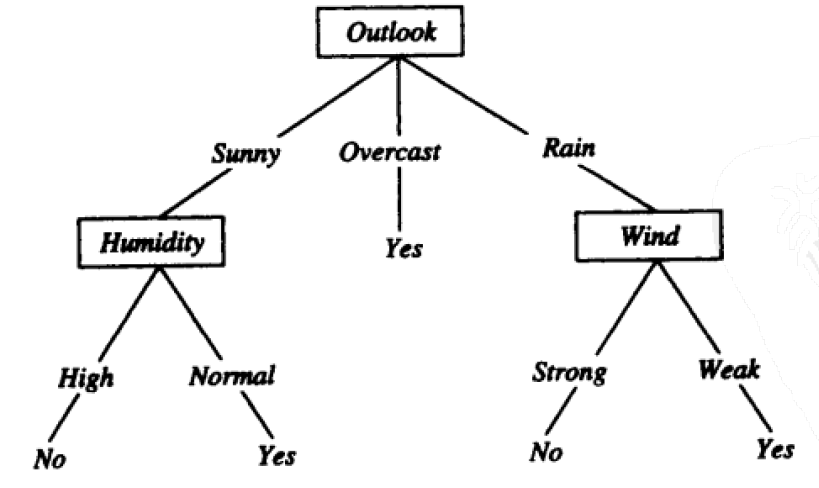
图2.1 概念Play Tennis决策树
2.决策数构建算法的基本思想
常用的决策树算法有ID3、C4.5、CHAID、CART、 SLIQ和SPRINT等,但基本思想都可以用以下几步来表示:
1)决策树从代表训练集的单个结点开始;
2)如果训练集结果在同一类,定义该结点为叶结点并用该类标记;
3)否则选择最有分类能力的属性作为决策树的当前结点;
4)根据当前决策结点属性取值的不同,将训练集分为若干子集,每个属性值产生一个分枝。对得到的每个子集重复1-3步,递归形成每个分类数据集上的决策树。结点使用过的属性要从该结点的后代使用的训练集中剔除;
5)递归上述划分步骤至下列条件之一成立时停止:
①结点的所有结果属于同一类。
②没有属性可以用来进一步划分,则将结点作为叶结点,并以数据集中结果最多的类作为类标记。
③如果某一分枝没有满足已有分类的数据,则以数据集结果的多数类作为叶结点。
3.决策树预测实例
剩余内容已隐藏,请支付后下载全文,论文总字数:26982字
相关图片展示:

该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

