论文总字数:24538字
目 录
1 绪论 1
1.1 研究背景 1
1.2 研究现状 1
1.2.1 爬虫技术概述 1
1.2.2 爬虫面临的问题 1
1.3 研究意义 2
2 关键技术概述 2
2.1 Scrapy框架 2
2.2 数据可视化工具包 3
2.3 其他软件 4
3 系统分析 4
3.1 可行性分析 4
3.2 需求分析 5
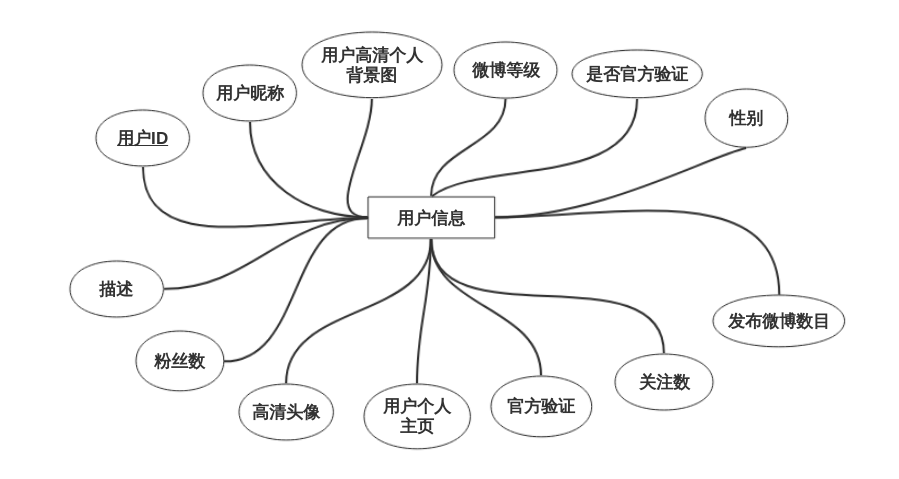
3.2.1 用户需求分析 5
3.2.2 功能需求分析 5
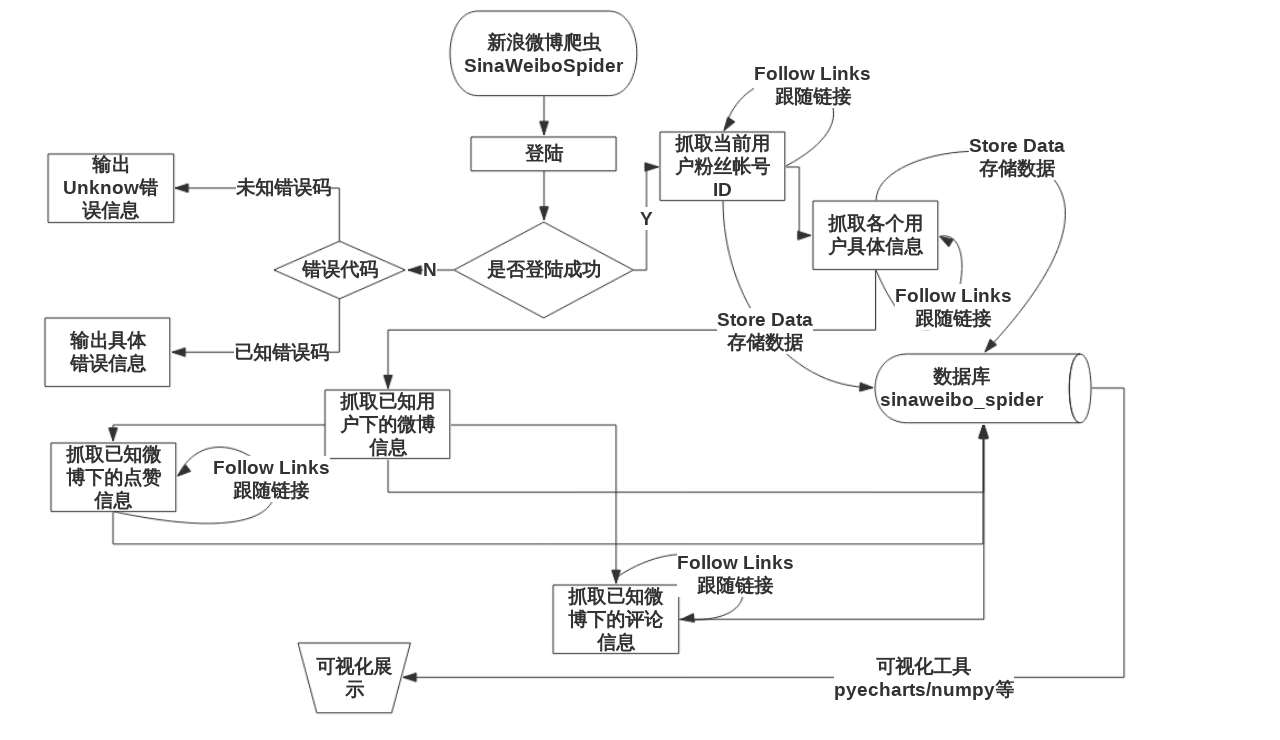
3.3 业务流程图 6
4 整体框架设计 7
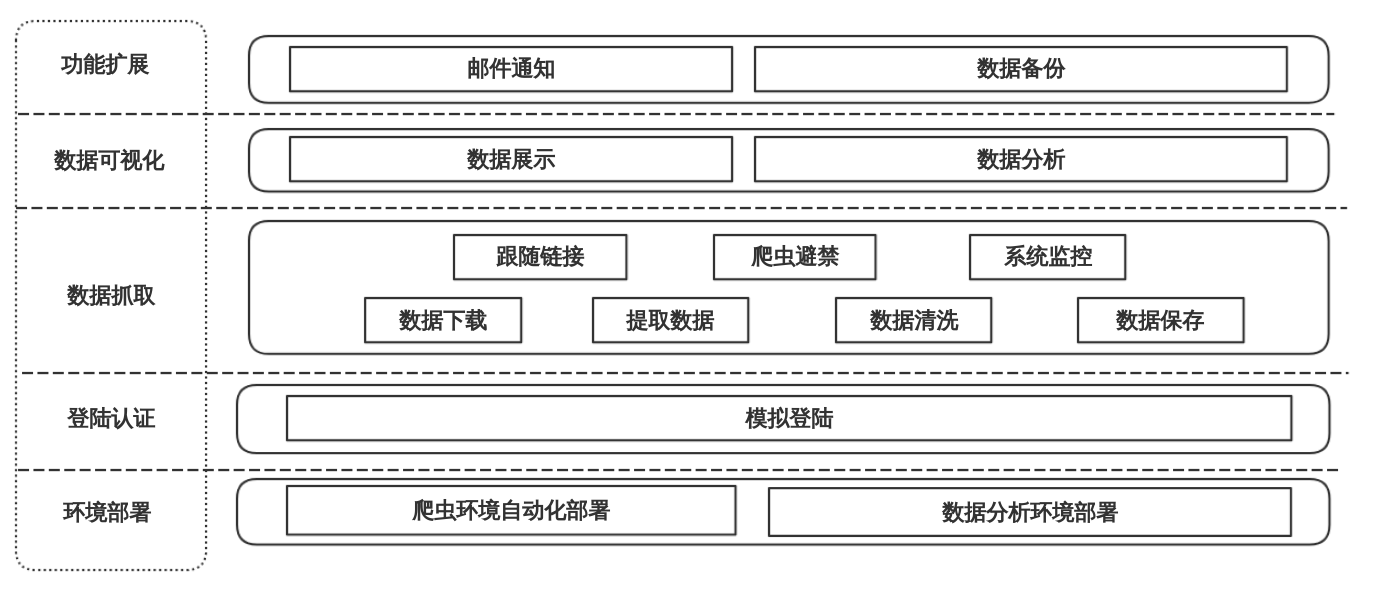
4.1 系统架构图 7
4.1.1 环境部署 7
4.1.2 登录认证 8
4.1.3 数据抓取 8
4.1.4 功能扩展 9
4.1.5 数据可视化 9
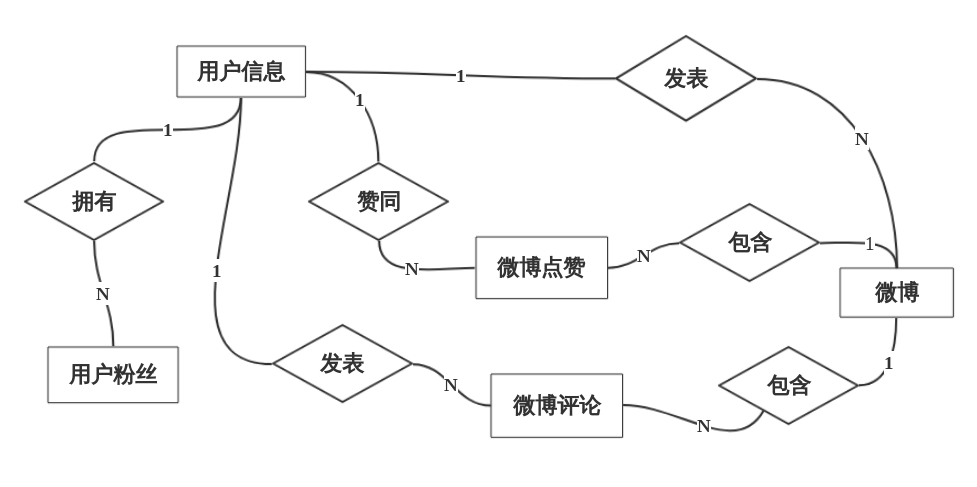
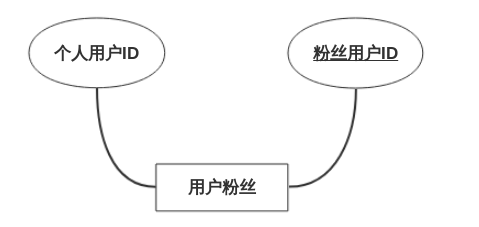
4.2数据库设计 9
4.2.1 E-R模型 9
4.2.2 表结构设计 12
4.3主要函数设计 14
5 系统实现 15
5.1 基于Scrapy数据爬虫设计实现 15
5.1.1 自动化部署 15
5.1.2 爬虫使用 16
5.1.3 登录认证 17
5.1.4 数据抓取 19
5.1.5 功能扩展 21
5.2 微博数据可视化设计与结果分析 23
6 总结与展望 28
参考文献 28
致谢 30
基于Scrapy框架的网络爬虫实现与数据抓取分析
闫晨阳
,China
ABSTRACT:Sina Weibo, a social networking platform of information sharing, dissemination, and access based on user relationship, has many valuable data.This paper will study Sina Weibo, a huge social media platform, from the perspective of data, and use data to discover the hidden rules in a large number of live entertainment, communications, and business data. First of all, it establishes a user request by Scrapy crawler framework and proxy IP settings, using the json module in the Python language standard library to convert captured information to JSON formatted data; then it uses a third-party PyMySQL module to save the formatted data to the MySQL database for storage and maintenance; finally system will uses the data visualization tool to display the key information in an intuitive and visual way on the Web side, and displays vividly massive data and information. Therefore, it achieves the data mining and effective usage of Sina Weibo .
Key words:Python, Scrapy, Crawler, Data Visualization
1 绪论
1.1 研究背景
在如今数据爆炸、智能手机的应用日益广泛的互联网时代,数据的碎片化、多样化、流媒体特征更加明显,并以前所未有的速度颠覆着我们的日常生活。社会化媒体上的信息是我们间接了解现实客观世界和主观世界的一面窗户,我们每时每刻都在受到它的影响。新浪微博,一个通过用户关系来实现信息分享与传播的社交网络平台,拥有许多有价值的数据。通过挖掘并研究新浪微博的数据信息,一方面我们可以足不出户知天下,了解世界所发生的点点滴滴,对特定领域的知识进行分析而了解该领域的发展进程和现状,另一方面我们也可以通过分析新浪微博的大量数据和关系链来展现爬虫和数据分析的魅力,从而实现对新浪微博数据的挖掘和有效利用。
1.2 研究现状
1.2.1 爬虫技术概述
网络爬虫技术源于上个世纪90年代,Google等搜索引擎的发展带来了爬虫技术的诞生。首先,利用爬虫抓取互联网上的Web页面,再通过搜索引擎对其进行索引、存储,最终为我们提供检索和导航服务[1]。从某种意义上来说,搜索引擎的后台系统就是网络爬虫,属于幕后技术,对用户来说完全是透明的,因此在较长的一段时间内并未被广大开发人员所关注。随着互联网技术的不断发展,人们对网络爬虫技术的关注度快速上升,随之也渐渐的衍生出许多优秀的开源爬虫框架,包括Scrapy、Larbin、Heritrix、PySpider等。Scrapy具有Python的简洁性优点,在开发人员之间非常流行,文档和插件丰富,支持灵活的提取各种所需数据[2];Larbin只负责网页抓取,需要用户完成抓取和持久化,但是效率非常高[3];Heritrix专门为网页检索器提供存档,使用Java语言开发,具有良好的可扩展性[4];PySpider是国内作者开发的开源爬虫框架,上手简单,支持可视化页面抓取、活动历史查看和运行状态监控等;Polybot是纽约大学发布的高性能、高扩展性的主从式分布式网络爬虫程序,URL在内存中使用红黑树结构进行存储,其爬取速度可达到100网页/秒[5]。
目前,国内外将网络爬虫按照结构和使用功能划分为4种类型的爬虫,分别是:全网爬虫、聚焦爬虫、增量式爬虫和深层爬虫[6]。然而,在实际的应用中,往往是这4种爬虫的综合使用,仅仅只用其中一种爬虫来进行数据抓取是不能满足需求的。
1.2.2 爬虫面临的问题
最早的爬虫起源于搜索引擎,与其他恶意收集数据的爬虫相比,搜索引擎是一个“善意”的爬虫,可以检索用户的一切信息,并提供给其他用户访问。为了限制用户的搜索范围,他们还专门定义了robots.txt文件来作为君子协定,以此来规定网络上哪些数据是可以被检索到,哪些数据是不可以被检索到。这是一个双赢的局面。
随着电子信息技术的迅速发展,大数据时代的流行将爬虫技术推上了一个浪潮。越来越多的人开始研究爬虫,利用爬虫来获得“互联网”下的海量数据,这使得爬虫技术的许多缺点也渐渐浮现出来。
(1)道德和法律风险:互联网的快速发展使得信息隐私对用户变得越来越重要,然而,爬虫的诞生就是为了抓取数据信息而存在的。如果爬虫爬取的是商用网站数据或者有机密性的网站数据,则会有一定的法律和道德风险。目前,我国互联网在信息隐私的保护还不完善。
(2)爬虫瓶颈:当爬虫频繁的对某个网站进行请求和数据采集时,此时有两个瓶颈:一是爬虫频繁运行会导致对方服务器封闭用户爬虫请求,即封IP或者临时封闭用户账号;二是爬虫的访问速度慢,导致爬虫解析数据并提取结构化数据的能力比较弱,即结果集中的数据条目比较少,难以满足开发者的需求。
(3)验证码:验证码的最初设计初衷就是为了区别人和机器人,防止机器人恶意攻击系统、破解用户密码等。随机技术的不断发展,验证码已从输入几个字母的验证码变成了滑动验证码、根据要求选择答案的验证码以及Google公司这样的基于机器学习的验证码,使得验证码的识别变得越来越复杂,也不容易被破解。因此,爬虫在识别验证码上产生的开销往往比数据抓取产生的开销要大。
1.3 研究意义
通过新浪微博的数据信息,一方面我们可以通过爬虫系统“极客范”的了解世界所发生的点点滴滴,另一方面我们可以对特定领域的知识进行分析而了解该领域的发展进程和现状。分析新浪微博的大量数据和关系链能够全面的解析每个帐号的粉丝性质、关注人数性质,以及原创帖子热门程度等,最终综合反映出该帐号的影响力情况,将会为企业的运营提供一个参考条件来指导运营决策、驱动业务增长。另外,我们可以通过数据可视化技术,发现大量生活娱乐圈以及商业数据中隐含的规律,从而为决策提供依据,使得业务发展蒸蒸日上,这已成为数据可视化技术中新的热点。
2 关键技术概述
2.1 Scrapy框架
Scrapy是一种开源爬虫框架,基于Python[7]语言开发,使用Twisted异步网络库处理网络通讯,能够快速爬取网站数据并提取结构化数据。其特性是简单快捷、可定制性强,非常适用于网页数据的抓取。开发者只需要根据自己的实际需求开发出特定的几个模块就可以轻松的实现一个爬虫,用来从网页中提取数据(如网页内容以及各种图片),非常方便。下图2-1说明了Scrapy的框架原理:

图2-1 Scrapy框架原理图
Scrapy一共有7个组件,其工作流程是:第一步,Scrapy引擎(Scrapy Engine)从爬虫(Spiders)中得到爬虫准备爬取的初始化请求(如:爬取的入口链接);第二步,Scrapy引擎在调度器(Scheduler)中调度请求并且获取下一个待下载的爬虫请求(这两步是异步执行的);第三步,调度器返回下一个待下载的请求给Scrapy引擎;第四步,Scrapy引擎发送请求给下载器(Downloader),途中会经过下载器中间件(Downloader Middlewares);第五步,当所请求的页面完成下载后,下载器会生成一个响应对象并返回给Scrapy引擎,同时中间也会再次经过下载器中间件;第六步,Scrapy引擎从下载器中接收到响应对象后,然后发送给爬虫去处理,途中会经过爬虫中间件(Spider Middlewares);第七步,爬虫处理返回的响应请求并且将已获取到的结果对象和新的请求对象发送给Scrapy引擎,途中会再次经过爬虫中间件;第八步,Scrapy引擎将已获取到的结果对象传递给结果处理器(Item PipeLine)进行处理,然后发送已处理的请求对象给调度器并且请求下一个可能待下载的爬虫请求;第九步,从第一步开始重复执行,直到调度器中没有更多的请求来处理[8]。
2.2 数据可视化工具包
ECharts 是百度开源的一个使用 JavaScript 实现的可视化库,主要用于数据可视化,提供了常规的折线图、柱状图、散点图、饼图以及用于关系数据可视化的关系图和其他多种丰富功能的图表[9]。然而,pyecharts是Python版本的EChart,用于生成 ECharts 图表的类库,提供形象直观的数据可视化图表。
由于Python语言本身的特点,如广大的社区用户支持、作为“胶水语言”与C、Fortran语言紧密结合而拥有高性能计算特性等,使得Python语言也可以拥有进行数值运算、画图特性等第三方类库,如numpy等。
剩余内容已隐藏,请支付后下载全文,论文总字数:24538字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

