论文总字数:25262字
目 录
1 绪论 1
1.1研究的背景和意义 1
1.2 国内外研究现状 2
1.3 本文的主要研究内容 3
1.4 论文组织结构 4
2 特征选择方法 4
2.1 特征选择概述 4
2.2 特征选择的分类 4
2.2.1嵌入式(Embedded)特征选择 5
2.2.2过滤式(Filter)特征选择 5
2.2.3封装式(Wrapper)特征选择 5
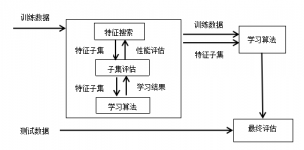
2.3 特征选择方法的基本框架 6
2.3.1子集产生过程与搜索策略 6
2.3.2评价函数 8
2.3.3停止准则 9
2.3.4结果验证 9
3 一致性度量方法 10
3.1 一致性度量方法概述 10
3.2 一致性度量典型算法概述 10
3.2.1 FOCUS算法 10
3.2.2 ABB算法 10
3.2.3 LVF算法 11
4 FOCUS算法及实验结果分析 12
4.1 FOCUS算法描述 12
4.1.1 算法实现工具 12
4.1.2 FOCUS算法概述 12
4.2 focus算法设计与实现 13
4.2.1 FOCUS算法设计 13
4.2.2 FOCUS算法实现 14
4.3 实验结果分析 16
4.3.1数据集一分析 16
4.3.2数据集一实验结果分析 16
4.3.3 数据集二分析 17
4.3.4 数据集二实验结果分析 20
4.3.5 分类精度比较 23
4.3.6 算法总结 23
5 结束语 24
参考文献 24
致谢 26
基于一致性的特征选择
陈燕
,China
Abstract:Feature selection is an important data preprocessing method in the fields of data mining and machine learning. It has been widely applied in many important technical fields. Feature selection can effectively reduce workload and extract efficient feature subset, so as to improve classification performance and reduce data storage and processing costs. In this paper, we mainly study the method of feature selection based on consistency metric, in which the consistency measure is an important evaluation criterion in filtering feature selection. The goal of consistency measurement is to find the smallest feature subset with the same resolution as the original feature set. It can eliminate the unrelated features and get the feature subset that meets the requirements. Moreover, the consistency measure is very sensitive to noise data and can deal with noise effectively. In this thesis, the FOCUS algorithm based on the consistency measurement is realized.In the design, the typical features of the experiment are implemented with the feature map so that the distribution of the eigenvalues of the feature can be clearly and clearly seen from the graph. Through the analysis of the experimental results, we can see that the algorithm greatly reduces the data dimension and is an effective means of data dimensionality reduction. Classification accuracy experiments show that with the decrease of threshold value, the accuracy of classification is also gradually increasing, which shows the effectiveness of the experimental results.
Key words : feature selection;consistency measure;FOCUS algorithm
1 绪论
1.1研究的背景和意义
随着计算机科学的高速发展,众所周知,计算科学的思想与技术已经应用于生活的各个方面,科技水平的发展,使各个领域都能将人类社会的信息转化为能够被计算机识别的信息,信息的转化及计算过程中,积累了大量的信息数据。据研究表明,仅仅2010年,全球就产生了1.2(ZB)数字信息,这是美国一家国际数据公司名为“数据世界”的项目调查结果,由此可见,“数据洪水”的泛滥之势越来越猛烈。这些大量的甚至海量的数据集中存在大量的冗余和噪音数据,人们已经不能通过直观的经验从大量的数据信息中提取出有用的数据信息知识。大规模数据所带来的问题主要体现在两个方面:一方面是指它所包含样本的数量庞大,而且类别不均匀分布;另一方面是指原始数据的特征维度非常高,且存在大量冗余和不相关属性,机器学习的重要性由此可见。机器学习可以将海量的数据进行信息的特征提取,解释数据之间的特征关系,它是人工智能的核心,是使计算机能够智能地应用于人类社会的大量领域的根本途径。
对于机器学习,一个重要的问题就是如何选择一组具有代表性特征,用来构建模型。特征选择是机器学习领域中的一项重要技术,是指从原始特征集合中选择一组具有代表性的特征子集,用来达到降低特征空间维数的目的。目前,特征选择被广泛地运用于各个领域,特别是模式识别和数据挖掘等方面。人工智能、计算机科学的高速发展,使模式识别技术广泛地运用于人们的生活,例如:智能手机的指纹识别功能、安全系统中的人脸识别技术、瞳孔识别技术等。在模式识别系统中,学习样本中是否含有冗余信息对分类器的性能有着重要的影响。而大量的研究调查表明,特征选择可以通过剔除不相关特征和冗余特征来提高分类器的性能,进而降低数据存储和处理成本。特征选择是在不改变每一个特征本身的物理意义的情况下,选择出与类别相关性强、同时选择出特征彼此间相关性弱的特征子集。 通过这种方式,可以实现简化原始数据集,提高学习算法性能以及减少系统运行时间的目标。这个目的可以通过研究样本的分布特性,定义合适子集搜索策略和评价函数,选取一个最优的特征子集替代原始特征空间来实现。因此有一种特征选择的定义为从原始特征集中选择某种评估标准,从而使算法结果能够得到最优的特征子集。
在实施降维的过程中,特征提取和特征选择都是可选择的有效方式。特征提取是将原始数据转换为具有明显物理或核特征的一组特征。特征提取后的新特征是原始特征的映射集。特征提取主要是通过特征属性之间的关系,组合不同的属性,得到新的特征属性,这样就能达到降低空间维度的效果,得到新的特征空间。而特征选择是从原来的特征集中选出有效的特征子集,是一种包含关系,没有改变原始的特征空间,特征选择后的新特征是原来特征的一个特征子集。相对于特征提取来说,特征选择的方法具有几方面的优势,具体如下:(1)特征抽取方法所得到的新的特征是原始特征一种新的特征属性组合,并不具有现实物理意义,而特征选择方法得到的特征子集在原始特征空间中具有物理意义。例如在临床诊断领域,应用于疾病诊断的基因集合的选择更够能够从生物医学角度解释致病基因。(2)特征抽取方法的计算复杂度与特征选择方法来说相对较高,对于大规模的训练数据集来说,这一点是非常难以接受的。而计算复杂度较低、同时效率又较高的特征选择方法对于大规模的数据预处理相对来说则更为合适。
信息技术每一天都在取得可喜进步,在这种情况下,大规模数量集中的特征冗余和不相关属性也呈几何倍数的增加了,相应的对特征选择的要求也越来越高。这就需要更加高效的特征选择算法对数据进行更为高效的预处理,得到最优秀、有效的特征子集信息,最大限度的提高数据处理性能。
1.2 国内外研究现状
特征选择是机器学习和模式识别等领域重要的研究内容之一。早在上个世纪60年代,最早的特征选择研究已经开始了,在那个时候,特征选择的研究一般集中在统计学和信号处理问题上。而且,当时涉及到的特征选择样本通常较小,于是,通常都会假设特征之间相互独立。直到90年代,这个课题才引起了人们的重视。从这个时候开始,随着大规模信息数据的出现,机器学习、数据挖掘的问题就不断地涌现在许多的领域,如文本分类、社交网络、组合化学、基因工程等。这时,越来越多的数据集合的特征空间慢慢的具有了成千上万个维度,而实际上,真正需要的表达本质的特征属性只有很小的一部分,大量的冗余的、不相关的特征将这一小部分有效的特征属性湮没了,对机器学习的算法性能产生了极大地影响。由此,大规模数据的特征选择面临着严峻的挑战,也因此引起了相关领域学者对特征选择的研究热情。
Siedlecki和Sklansky[1]于1988年发表了相关文献,并就如何评估特征选择算法进行了深入讨论。他们将特征选择算法分为三类:过去的、现在的和将来的。学者Doak[2]和Jain等人对特征选择算法搜索的起点、方向以及策略等问题进行了研究,其中包括了如何评价特征子集,也就是评价准则的问题。1992年,Kira和Rendell[3]提出了一种著名的特征选择算法——Relief,即一种特征权重算法(Feature weighting algorithms)。特征权重算法是根据各个特征的相关性赋予特征不同的权重,当某个特征的权重小于特定的阈值,这个属性特征将不再考虑。也在1992年,著名学者Almuallim和Dietterich[4]提出了基于信息论度量的特征选择方法。1994年,Kononenko将relief算法进行了补充,提出了reliefF算法。1997年,新加坡国立大学的M.Dash和H.Liu[5]对以前的特征选择进行了总结。Dash和Liu根据评价标准和搜索策略对特征选择方法进行了系统的分类,其中特征选择的搜索策略可以分为3种:启发式搜索、完全搜索和随机搜索;而特征选择的评价准则被分为5种:距离度量、信息度量、相关性度量、一致性度量和分类错误率度量。
根据特征选择的数据集样本中是否含有类别信息,可以将特征选择分为两类:有监督的特征选择和无监督的特征选择。在特征选择研究的早期,有监督的特征选择是研究的重点,随着研究的深入,渐渐地人们开始了对无监督和半监督的特征选择的研究。近年来,基于半监督(SSL)学习的特征选择也同样成为了研究的关注点。1988年,Siedlecki和Sklansky等对有监督和无监督的特征选择进行了综合的阐述。他们认为有监督的算法,它们的样本和类别是已知的,那么特征选择的任务就是在原始特征集中选择一定的特征子集,使分类器的辨识率最大。之后1992年,Doak等人对无监督和半监督的特征选择方法进行了研究。2003年,Zhu,Ghahramani[6]等人提出了半监督的特征选择,这种方法能够有效的提高算法性能,同时还能减少获取类别信息的成本。
剩余内容已隐藏,请支付后下载全文,论文总字数:25262字
相关图片展示:




该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

