论文总字数:23291字
摘 要
本文针对中国最具影响力的企业信息化门户网站e-works进行了数据的定向挖掘,构建了一个知识管理与分析的系统.可以让企业在组织中建构一个量化与质化的知识系统,让组织中的资讯与知识,透过获取、整合、记录、存取、更新等过程,不断的回馈到知识系统内,使个人与组织的知识成为组织智慧的循环,在企业组织中成为管理与应用的智慧资本,有助于企业做出正确的决策,以适应市场的变迁。本文首先扩展并定制了自己的Heiritrix网络爬虫,实现对数据的挖掘。其次利用HtmlParser和正则表达式实现对数据的预处理,再利用MySQL和Lucene实现对数据的存储和索引,最后搭建了一个WEB平台,实现与用户的交互与检索功能。除了搭建此次检索系统之外,笔者还对抓取到的数据进行了趋势分析,得到了企业信息化的热门领域的发展趋势。
关键词:Heritrix; Lecene;eworks; 信息技术; 大数据
Design of Web data acquisition system based on JAVA Technology
Abstract:Global consulting company McKinsey said:" data has penetrated every industry and business functions in today's field, becoming an important factor in production. The arrival of new wave of productivity growth and consumer surplus wave is a new wave of mining and application of mass data. ". The amount of data is getting bigger and bigger , how to realize data directional mining, analysis and management is particularly important to enterprise. For them, an efficient and integrated information platform for good information is very necessary. For many enterprises, solving the enterprise management problem through the information tool is also imminent.
The article constructs a data mining,knowledge management and analysis system in view of China's most influential enterprise information portals e-works. This System can allow enterprises to construct a quantitative and qualitative knowledge system in the organization and let the organization of information and knowledge feedback to the knowledge system,through the access, integrate,record,access and update process. It turns to be an individual and organizational knowledge cycle of organizational wisdom,whch combines the management and application of intellectual capital in the enterprise organization.As a result,it can lead the enterprise to make correct decision and adapt to market changes. This paper first expands and has customized its Heiritrix web crawler to realize data mining,followed by Htmlparser and regular expressions to realize the data preprocessing,then realize the data storage and indexing with Lucene and MYSQL, finally build a web platform,implementation and the user's interaction with the search function. In addition to build the retrieval system,the author also carries on the trend analysis to the crawled data, which has got the trend of the enterprise informationization in the hot domain.
Key words: Heritrix;Lecene;eworks;information technology; Big data
目 录
1绪论 1
1.1 课题背景、依据及目的意义 1
1.2 主要研究内容 1
1.3 系统总体设计 2
2数据采集 4
2.1 Heritrix简介及分析 4
2.2 取消Robots.txt的限制 5
2.3 利用ELFHash策略多线程抓取网页 6
2.4 向Heritrix中添加自己的Extractor 7
2.5 扩展FrontierScheduler 8
2.6 设置heritrix以只抓取html格式对象 9
2.7 执行抓取任务 10
3信息抽取 12
3.1 分析网页 12
3.2 网页解析 13
4信息存储 16
4.1 建立数据库和表。 16
4.2 java连接MySQL 17
4.3 向数据库插入数据 17
5基于Lucene的索引 19
5.1 Lucene介绍及分析 19
5.2 倒排索引 19
5.3 中文分词技术 20
5.4 索引实现 20
6搭建Web平台 22
6.1 建立web配置文件 22
6.2 Bean类 23
6.3 Eworks数据库访问 23
6.4 索引检索类SearchService实现 23
6.5 前台web页面 24
7趋势分析 26
7.1 关键词创建 26
7.2 数据表格创建 27
7.3 趋势分析 28
致谢 30
参考文献 31
基于JAVA技术的网站实时数据采集系统设计
1、 绪论
1.1 课题背景
在这个网络化的时代,信息和网络技术正在向整个人类和社会蔓延。网络化的时代是数据爆炸的时代,如此众多的数据,如何来对它们进行定向挖掘,管理,和分析成了一大难题。信息检索给专业人士带来了巨大的便利,通过它能够分析更大量的数据,从而得出更接近事实的信息来指导人们的行动。从百度,Google的繁荣,我们就可以看出搜索引擎的巨大应用市场和需求。
随着网络与安全技术的成熟,网上蕴含的信息也越来越多,电子商务也越发流行,阿里巴巴的成功使得这一趋势愈发上涨。在很多领域,数据有时候就意味着财富,某些企业或个人用户对网页信息有着特殊的要求,比如用来研究股市的变化趋势。众所周知,目前通用搜索引擎像百度等给出的查询结果往往都非常广泛,还包含了许多竞价的广告,这给我们进行有效信息的查询带来了很多不便。而随着数据的增加,人们对于数据的准确性要求却越来越高。这一类用户对信息的获取有共同的特点:目标网站明确集中、目标网页涉及特定的主题、对信息的实时性要求比较高[1]。
互联网信息的获取方式通常靠手工去信息源获取,比如用web浏览器获取web页面。[2]但是这些信息有时并不准确,如何将这些信息准确采集下来并分析管理成了一大难题。数据采集技术出现后,查询的准确性和效率大大增加,给专业人士带来了巨大的便利,通过它能够分析更大量的数据,这些数据往往更加客观,得出的结果也更加接近事实,进而更准确的指导人们的行动,数据采集的旺盛生命力已经显现出来。各项基于互联网的服务随着互联网上信息的飞速发展而逐步丰富和日新月异。[3]
网络上的数据每天都在增长,面对如此众多的更新数据,传统的搜索引擎显然是无法及时准确的去更新与查找有关的最新索引数据库。在这种情况下,垂直搜索引擎就如雨后春笋般涌现了。
垂直搜索引擎是专门针对某一专业领域而建立的搜索引擎,其搜索的范围虽然缩小了,但是准确度和速度却大大提高,因为范围缩小导致了不相干信息的减少,让用户在最短的时间内查询到自己所需的信息。垂直搜索引擎,它具有返回结果高度相关性、索引快速更新等特点,而这些都是传统搜索引擎所不及的[4]。
今天的以网络为中心的世界产生了爆炸的信息数量、无处不在的数据来源和社会影响。这种Web交互的现状是前所未有的。知识创造机会,这将极大地影响我们的生活。
1.2 主要研究内容
1.2.1网络爬虫
(1) 取消Robots.txt的限制
(2) 利用ELFHash策略多线程抓取网页
(3) 设置heritrix以只抓取html格式对象
(4) 修改配置文件order.xml加快你的抓取速度
(5) 让Heritrix不间断的抓取
(6) 将FrontierScheduler扩展,实现EworksArticleFrontier类来抓取特定的内容,比如,要去除所有的扩展名为.zip、.exe、.rar、.pdf和.doc的链接
1.2.2HtmlParser和正则表达式
将HtmlParser和正则表达式相结合,对抓取到的网页进行预处理,包括解析,提取文本,去掉标签广告
1.2.3数据库的操作
利用MySQL建立数据库,建立数据库与java工程的连接,定义了ArticleJDBC类将数据写入数据库
1.2.4中文分词技术
1.2.5索引的创建
利用JE分词构建词库并基于Lucene建立eworks文本信息的索引
1.2.6搭建web平台
利用Tomcat再本地搭建服务器,然后利用DWR搭建web平台,编写所需的js页面
1.2.6趋势分析
利用抓取到的大量数据,得出企业信息化的热门领域,并对该领域进行了趋势分析
1.3 系统总体设计
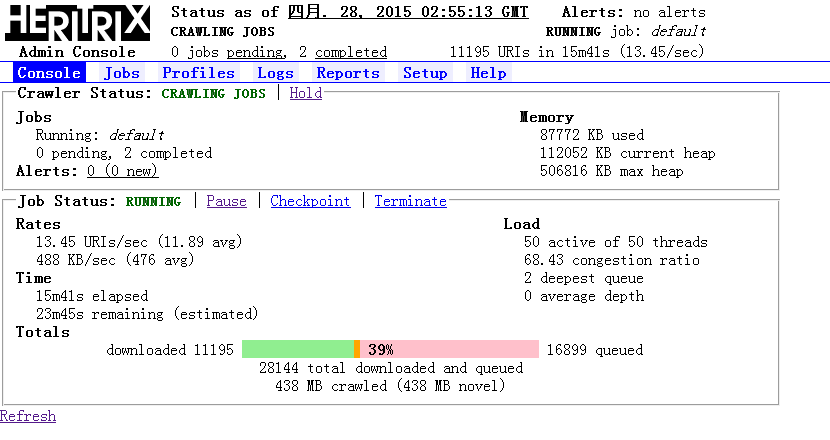
本系统是以e-works企业信息网为基础的垂直搜索引擎,拟建立一个具有垂直搜索功能的信息查询系统,使广大的IE人员和企业能够较为方便的得到他们所需的各种企业信息化的详细信息。E-works是中国最具影响力的企业信息化门户网站,网站上包含了众多企业信息化的资讯,文章,博客等,资源丰富。本系统的研究以开源的Lucene为基础,涉及到的知识广而复杂,是一个面向IE的e-works垂直搜索引擎系统,致力于推荐企业信息化进程不仅利用网络爬虫Heritrix采集到众多的网页信息,还提供了基于WEB的查询入口,可以满足用户对e-works上各种关于企业信息化的搜索。本系统具有较高的查准率和较快的响应速度,总体结构如图所示:
基于JAVA技术的网站实时数据采集系统设计
趋势分析
MySQL数据存储
DWR搭建WEB平台
Lucene创建索引
HtmlParser数据抽取
Heritrix数据采集
图1.1 总体设计
本系统的数据采集模块包括Heritrix数据采集、数据抽取以及数据存储。这三部分的研究和实现是后面搭建信息检索系统和进行趋势分析的基础。本文将数据采集技术做了2方面的应用,第一方面是比较常规的建立一个信息检索系统,该系统是以中国最具影响力企业信息化门户网站e-works为对象,实现了数据的检索查找功能,第二方面的应用是对IE领域中管理信息化的一个趋势分析,得出了近几年发展较快的热门领域,致力于指导广大IE领域的人员对研究方向的选择。有趣的是,该趋势的结果也证实了数据采集和大数据发展的速度也是呈指数上升的,这也充分说明了本文对数据采集的研究在IE领域是有重要意义的。另外,越来越多的高校也逐渐在IE中探索和尝试新的研究领域,与计算机的结合也越来越多,对数据采集技术的研究必然在IE中起到巨大的作用。
2、 数据采集
本系统的数据采集是通过网络爬虫Heritrix来进行的。Heritrix的使用已经越来越广泛。Heritrix涉及到的技术也较复杂而且配置相对麻烦,在Eclipse中配置好了之后还要开发自己的组件来执行抓取。
Heritrix的机制是从一个初始链接开始,初始链接可以通过种子文件配置,在抓取信息的过程中,不间断的从当下网页中获取新的链接放入Frontier队列,如果外链较多,那么Frontier队列就会较长,当满足系统的一定条件后爬虫系统就会停止。
本信息搜索系统的网络爬虫的爬取流程比较复杂,根据自己定制的Extractor和FrontierSchedule过滤掉与爬取内容无关的URL,如果不过滤无关的URL,会大大减低爬取效率,也会浪费流量。去除无关URL后,保留需要的URL并将其放入等待抓取的URL队列,URL的控制是通过Frontier来完成的。接着,本爬虫将根据特定的搜索策略从等待队列中选择下一步要抓取的网页链接,这些网页链接会根据我们设定的条件来改变,再未遇到结束条件前,爬虫会一直重复上述过程。另外,所有被爬虫抓取的信息网页将会被储存在指定的目录下,至此网页采集就结束了。
2.1 Heritrix简介及分析
Heritrix是一个专门为网页进行抓取而设计的网页抓取器,应用领域已经越来越多,它使用Java编写并且完全开源。它主要的用户界面存在于web浏览器中,我们可以在浏览器网页中控制抓取的范围,抓取的规则和保存路径。
剩余内容已隐藏,请支付后下载全文,论文总字数:23291字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

