鉴定葡萄酒品质的数据挖掘方法比较
白玫
()
摘要:相比传统的葡萄酒质量鉴别,数据挖掘方法避免了感官品尝结果容易受各种因素影响的问题,具有广泛应用的现实意义。本文通过运用数据挖掘中的两类分类方法,即神经网络和支持向量机,对葡萄酒质量质量分级做出了分析和比较。首先对11个葡萄酒理化指标变量作描述性分析,观察数据集特征和变量分布。其次进行相关性分析,发现若干变量具有较强相关性,我们挑选出部分相关性较大的变量两点之间的散点图,进一步进行分析比较,使用变量选择进行降维,再进行随后的分类研究。划分训练集和测试集比为7:3,分别建立了神经网络模型和支持向量机模型,分析对比两种方法所得结果之后,发现支持向量机的分类更优。
关键词:数据挖掘 葡萄酒鉴定 神经网络 支持向量机 clemintine SAS
- 引言
葡萄酒理化指标通常是与葡萄酒的质量有着直接的关系,但运用感官评价对葡萄酒质量评级通常会受到主观误差的干扰,所以通过葡萄酒理化指标的研究分析来鉴别葡萄酒质量有很重要的意义。对葡萄酒分级分类的相关文献有很多, 例如,王文静 [1] 研究了感官评价在葡萄酒鉴别中的应用,王金甲等 [2] 采用多元数据图的方式来对葡萄酒进行可视化分类,但这样的分类方法将存在一个非唯一性的问题,即不同排列顺序的多维数据对多元图的表达不一定是唯一的。李运等 [3] 将统计学方法应用于葡萄酒质量分析与评价中,采用通径分析,相关性分析,变异系数分析以及主成分分析等方法,寻找感官评价与葡萄酒成分之间的关系。此外王刚等 [4] 在关于运用数据挖掘方法进行分类的问题也做了一系列详细的讨论,并最后提出要注重多种发现策略和技术相结合的解决相关问题。运用数据挖掘方法进行葡萄酒质量评级避免了感官品尝结果容易受各种因素影响的问题,且具有广泛应用的现实意义。
我们在此处运用了数据挖掘方法中的神经网络和支持向量机分类的方法,希望对葡萄酒质量分级作出有意义的结果,并且探索不同的方法在不同情景下发挥效用不同,哪个方法更适合,在葡萄酒分类中具有更优的分类效果是我们要探索的目的。
- 数据处理
本文使用的wine数据集来自于UCI,该数据集中包含的红白葡萄酒样本分别为1599和4898个,11个输入变量,1个输出变量,输入变量为客观的理化指标测试值(如PH值),输出变量是基于感觉的数据 。最后一列数据为质量评价,数值介于 0 (表示极坏) 和 10 (表示很优秀)之间。对于该数据集,我们观察12个属性,将前11个属性作为输入变量,最后一个属性质量评价作为输出属性。
表 1 葡萄酒数据的整理
理化指标 | 数量 | 最小值 | 最大值 | 均值 | 标准差 | 偏度 |
|---|---|---|---|---|---|---|
fixed acidity | 1599 | 4.600 | 15.900 | 8.318 | 1.741 | 0.983 |
volatile acidity | 1599 | 0.120 | 1.580 | 0.528 | 0.179 | 0.672 |
citric acid | 1599 | 0.000 | 1.000 | 0.271 | 0.195 | 0.318 |
residual sugar | 1599 | 0.900 | 15.500 | 2.539 | 1.410 | 4.541 |
chlorides | 1599 | 0.012 | 0.611 | 0.088 | 0.047 | 5.680 |
free sulfur dioxide | 1599 | 1.000 | 72.000 | 15.875 | 10.460 | 1.251 |
total sulfur dioxide | 1599 | 6.000 | 289.000 | 46.468 | 32.895 | 1.516 |
density | 1599 | 0.990 | 1.004 | 0.997 | 0.002 | 0.071 |
pH | 1599 | 2.740 | 4.010 | 3.311 | 0.154 | 0.194 |
sulphates | 1599 | 0.330 | 2.000 | 0.658 | 0.170 | 2.429 |
alcohol | 1599 | 8.400 | 14.900 | 10.423 | 1.066 | 0.861 |
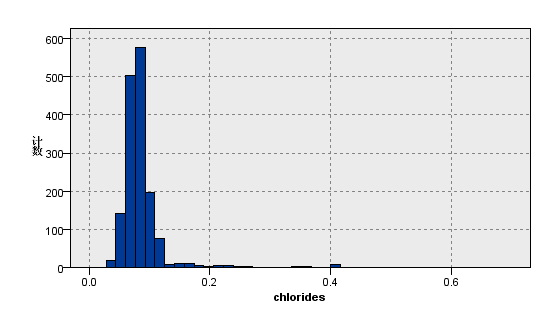 | 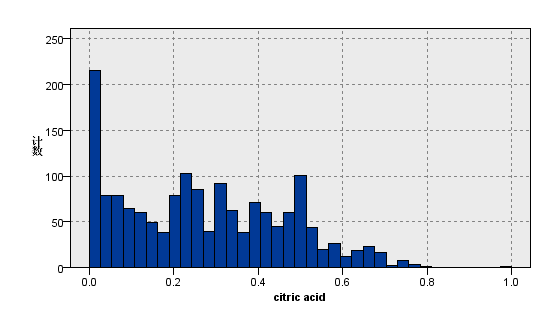 |
图1:变量chlorides的分布图 | 图2:变量citric acid的分布图 |
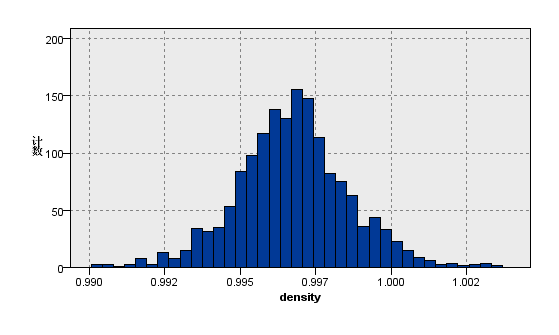 | 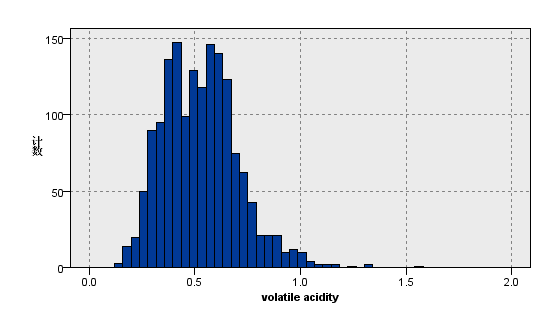 |
图3:变量density的分布图 | 图4:变量volatile acidity的分布图 |
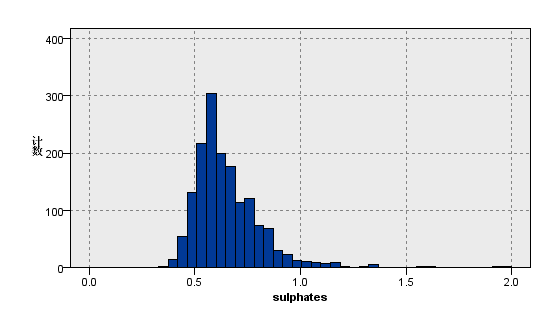 | 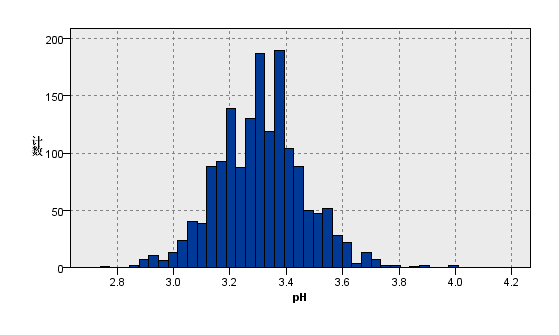 |
图5:变量sulphates的分布图 | 图6:变量PH的分布图 |
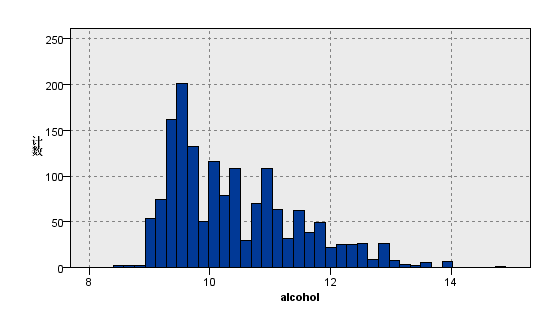 | 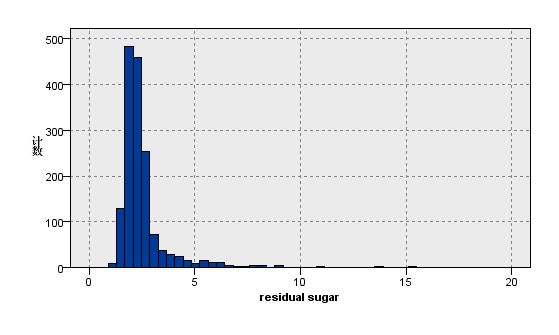 |
图7:变量alcohol的分布图 | 图8:变量residual sugar的分布图 |
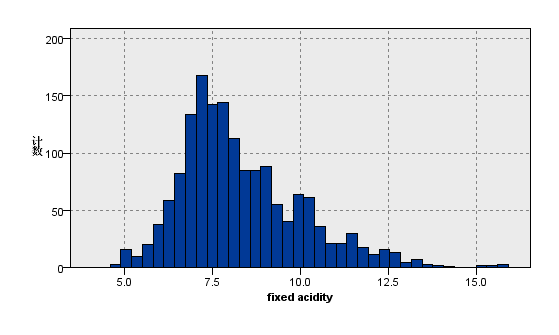 | 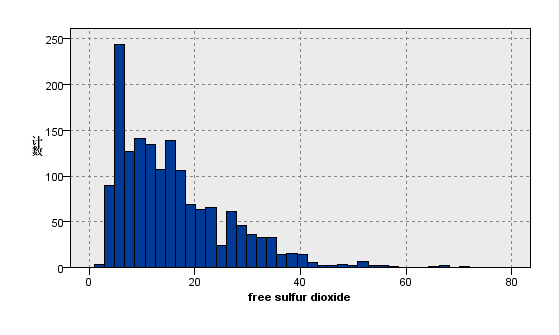 |
图9:变量fixed acidity的分布图 | 图10:变量free sulfur dioxide的分布图 |
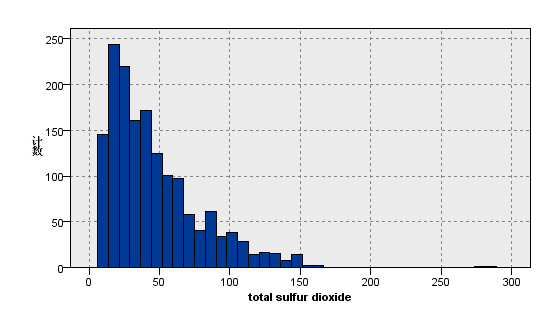 | 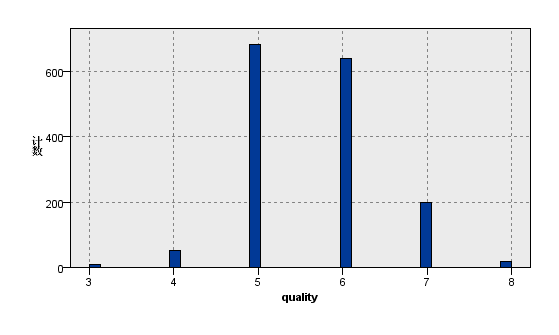 |
图11:变量total sulfur dioxide的分布图 | 图12:变量quality的分布图 |
观察上图关于数据分布的描述性分析,我们看到在质量评级范围在0到10的红葡萄酒数据集,实际等级分布为3,4,5,6,7,8且呈现正态分布。其中反映理化指标的变量除了柠檬酸,游离二氧化硫和总二氧化硫,均大致遵循中间高两边低的分布特征,并且极值的分部数量较少。总二氧化硫含量越高,样本计数梯度下降,游离二氧化硫在含量较低的[0,10]之间,增加含量样本数有急剧增加趋势,之后样本量便逐渐减少,并且注意到其在[40,80]较大区间内有极少量的连续样本分布。
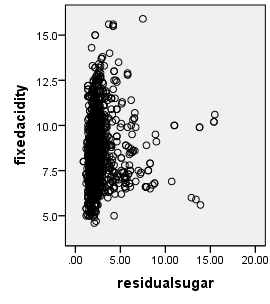
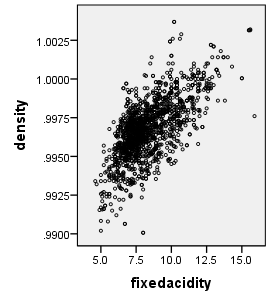
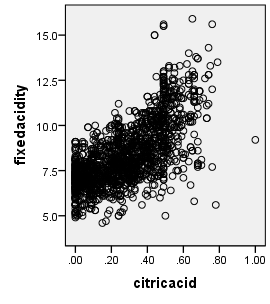
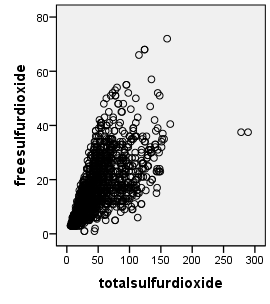
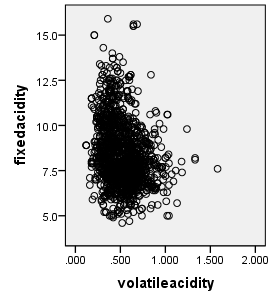
2.1相关性分析
剩余内容已隐藏,请支付后下载全文,论文总字数:9083字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

