论文总字数:23019字
目 录
1引言1
1.1研究背景1
1.2研究现状1
2灾害信息挖掘2
2.1 数据获取2
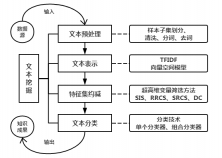
2.2 文本挖掘4
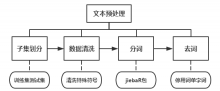
2.2.1文本预处理4
2.2.2文本表示6
2.2.3特征集约减7
2.2.4文本分类12
3灾害信息传播研究17
3.1 基本统计分析17
3.2 如何实现灾害信息有效传播18
4总结与展望21
参考文献22
致谢24
基于社交网络的灾害信息挖掘
时倩倩
, China
Abstract:Based on social network, we did two researches on Sina microblog data of five disaster events captured by web crawler and page parsing technology. On the one hand, we did text mining for disaster information. On the other hand, we studied how to achieve the effective dissemination of disaster information in microblog. In terms of text mining, we realized the detection of disaster events through text preprocessing, text representation, ultra-high dimensional variable selection and text classification. In the study of disaster information dissemination, we established Random Forest and other models to investigate the effect of different feature words on the level of microblog’s forwarding number, and used ROC curve to evaluate the models. The results indicate that adding words about the earthquake, casualties, rescue and encouragement in the microblog article, and emphasizing on disaster areas can lead to more microblog users’ forwarding, so as to promote the spread of the disaster information.
Key words:social network; text mining; ultra-high dimensional variable selection; information dissemination
1 引言
1.1 研究背景
近年来,我国自然灾害发生频繁,且受灾地区广泛。既有2016年罕见龙卷风重创盐城阜宁、最强霾致27城拉响重污染预警、汛期44次大范围暴雨造成近百城内涝,又有2017年6轮暴雨橘子洲头被淹、四川九寨沟7.0级地震、台风天鸽重创粤港澳大湾区。频繁发生的自然灾害不仅对人民生命财产带来严重威胁,也造成了巨大的社会经济损失。据中国国家减灾委员会发布的报告[1],2017年,我国各类自然灾害共造成全国1.4亿人次受灾,881人死亡,98人失踪,525.3万人次紧急转移安置,170.2万人次需紧急生活救助;15.3万间房屋倒塌,31.2万间严重损坏,126.7万间一般损坏;农作物受灾面积18478.1千公顷,其中绝收1826.7千公顷;直接经济损失3018.7亿元。随着社会经济的迅速发展,自然灾害造成的损失将会越来越大,因此政府部门和社会人员的减灾救灾工作和公众的自救工作尤为重要。其中,充足、准确、及时的灾害信息在减灾救灾过程中发挥着关键性的作用。然而,传统的灾害信息数据多为政府部门经过实地考察后上报的数据,对于普通大众来讲,获取难度大且时效性差,这给减灾救灾工作带来了巨大的挑战。
随着互联网的快速发展,我国的网民数量日益增多,越来越多的人活跃在QQ、微信、微博等社交网络平台上。据中国互联网络信息中心(CNNIC)发布的第41次《中国互联网络发展状况统计报告》[2],截至2017年12月,我国互联网用户规模达7.72亿,超过我国总人口数的一半,微信、QQ和微博的使用率分别达到87.3%、64.4%和40.9%。截至2017年第三季度,新浪微博月活跃用户达到3.76亿。以新浪微博为代表的社交网络平台凭借用户基数大、信息传播快、互动功能强等特点,成为网上内容传播的重要力量。尤其当重大灾害事件发生后,众多用户群体便在社交网络上发表言论,并做出转发、评论、点赞等互动行为,与此同时产生了海量的灾害信息数据。这使得微博等社交网络平台成为灾害事件发生时灾害信息的重要来源和沟通媒介,在灾害信息的传播和联合救援上发挥了重要的作用(朱雪(2013)[3])。较为典型的是2017年“8.8”九寨沟地震事件,地震发生后,第一时间,在新浪微博平台上便出现了几条带有“九寨沟地震,群众受困”等标语的微博,通过活跃在微博平台上的用户及“大V”博主的转发,九寨沟地震的消息传遍了各个角落,得知此消息的许多用户通过微博平台自发组织救援行动,实时发布求救和救援信息,不仅及时传播了灾情信息,使得公众能够第一时间了解灾情并做出应对措施,还有效提升了受灾群众得到救援的机会。此外还有2013年的“余姚水灾”事件以及2012年“721”北京暴雨事件,在交通通讯重度瘫痪的情形下,新浪微博充当了灾害信息传播的最佳媒介和海量灾害数据的重要来源。因此,在传统灾害信息数据获取难度大且时效性差的巨大挑战面前,对社交网络中产生的充足、准确、及时的灾害信息数据进行挖掘研究具有十分重要的意义。
1.2 研究现状
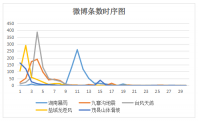
社交网络中的灾害信息数据凭借其传播性、实时性、充足性的特点及在防灾减灾、灾情传播中的重要作用成功引起了研究学者的重视,国内外研究学者纷纷展开基于社交网络平台的灾害信息挖掘与研究。国外学者Crooks等(2013)[4]和Sakaki 等(2013)[5]通过对Twitter上的灾害信息数据进行挖掘和分析,研究地震的实时预警和灾害事件的监测;Yan等(2017)[6]利用Geotagged社交媒体数据监测和评估灾后旅游恢复情况。此外,美国、澳大利亚、日本等国家相继开发了一系列面向社交网络用户的灾害事件检测系统,在相关领域的研究上已取得较大进展。在国内,相关学者在灾害事件的检测、分类、特征分析、信息传播等方面取得了一定的研究成果,但总的来说,对灾害信息的挖掘并不全面和成熟。Zhou等(2013)[7]以青海玉树地震微博为研究对象,从救援角度采用贝叶斯算法对灾害博文进行分类;曹彦波和毛振江(2017)[8]则是以九寨沟地震微博为研究对象,分析了此次地震微博的数量、灾情分类、词频统计、时间序列和空间分布等特征。但两者都仅局限于对地震这一灾害事件进行研究,对其他灾害事件并没有涉及。为此白华和林勋国(2015)[9]面向新浪微博平台,探索高效的中文灾害微博信息分类算法,借鉴澳大利亚科学院研发的Twitter灾害实时预警系统(ESA)的经验,开发了新浪微博灾害事件检测系统(SWIM),实现了基于社交网络平台的地震等其他灾害事件检测。然而白华和林勋国(2015)是对各个灾害事件分别进行检测,实现的是灾害事件信息与非灾害事件信息的二分类,过程繁琐,且并没有进一步对检测出来的灾害事件信息在微博中的传播(张大瀚等(2016)[10])做相关的研究。然而,当灾害发生后,灾害信息的有效传播对于防灾减灾工作的实施具有重要作用。因此,本文主要从两个方面对社交网络中的灾害信息数据进行研究,一是对灾害信息进行文本挖掘实现灾害信息的多分类,即实现多个灾害事件检测;二是灾害事件发生后,对灾害信息在微博中的传播展开相关的研究。
2 灾害信息挖掘
2.1 数据获取
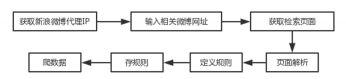
既然要对社交网络中的灾害信息进行研究,那么首先就要从社交网络中获取灾害数据。数据质量的好坏对研究进程和研究结果有重要影响,因此高质量的灾害数据对本文来讲至关重要。目前,微信朋友圈、QQ空间和微博是我国网民使用率最高的三大社交媒体,据第41次《中国互联网络发展状况统计报告》[2] 显示,截至2017年12月,微信朋友圈、QQ空间和微博用户使用率分别达到87.3%、64.4%和40.9%,而知乎、豆瓣和天涯社区的用户使用率相对来讲比较低,分别为14.6%、12.8%和8.8%。在各类社交媒体中,新浪微博的影响力逐渐放大,截至2017年第三季度,新浪微博月活跃用户达到3.76亿,微博实名认证用户、网络红人等对网络话题有较大的影响力。鉴于微信朋友圈和QQ空间的封闭性以及新浪微博用户基数大、信息传播快、互动功能强、影响力大等特点,本文主要基于新浪微博平台来获取灾害信息数据。在新浪微博数据的抓取(莫诗清等(2015)[11],廉捷等(2011)[12])上,主要有两种抓取方法,一种是基于新浪微博API的微博抓取,另一种是基于网络爬虫与页面解析的微博抓取。API接口的调用可以实现新浪微博数据的便捷抓取,然而微博运营商不会无条件开放给普通用户完整的API,同时对微博用户在API接口的调用频率及返回结果数量上也会有所限制,普通用户每小时最多只能调用API接口1000次,一次请求最多只能返回5000个结果,这就导致不能有效实现新浪微博数据的全面获取。然而,基于网络爬虫与网页解析的微博抓取方法约束性小、可操作性强且过程简单,因此,本文主要利用网络爬虫与网页解析技术来实现微博数据的采集,采集流程如图2-1所示。
剩余内容已隐藏,请支付后下载全文,论文总字数:23019字
相关图片展示:


该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

