论文总字数:23818字
目 录
摘要 I
Abstract II
1引言 1
1.1研究背景 1
1.2国内外研究进展 1
2 数据来源与数据处理 2
2.1问卷调查 2
2.1.1问卷设计 2
2.1.2问卷数据说明 3
2.2大众点评数据介绍 3
3方法介绍 3
3.1熵值法简介 4
3.2多项Logistic回归方法简介 5
3.3决策树CHAID方法简介 6
4实例分析 6
4.1影响因素研究——针对商家决策 6
4.1.1 消费者选择美食商户重要影响因素研究 6
4.1.2美食商户星级等级研究 9
4.2美食商户数据分析——针对消费者决策 12
4.2.1浦东新区美食商户区域分布与菜系种类分析 12
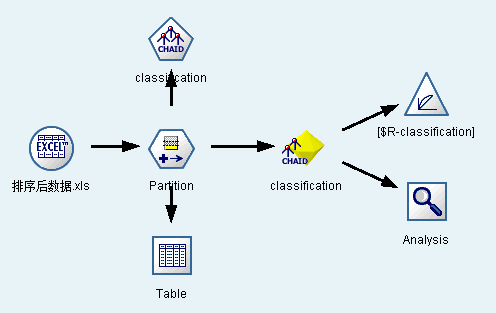
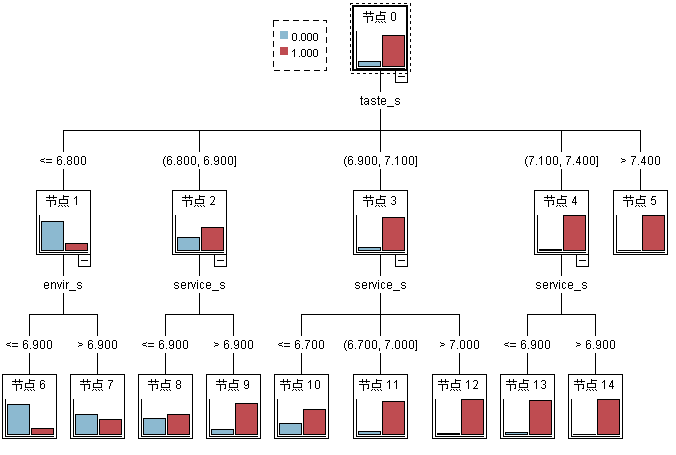
4.2.2 美食商户CHAID决策树分析 13
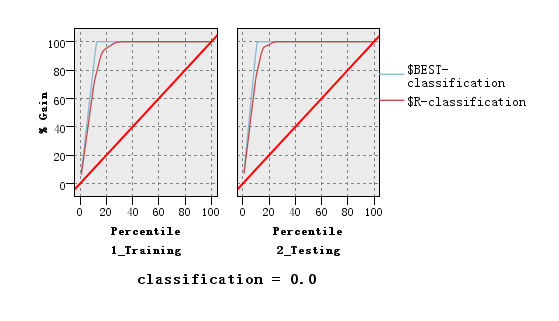
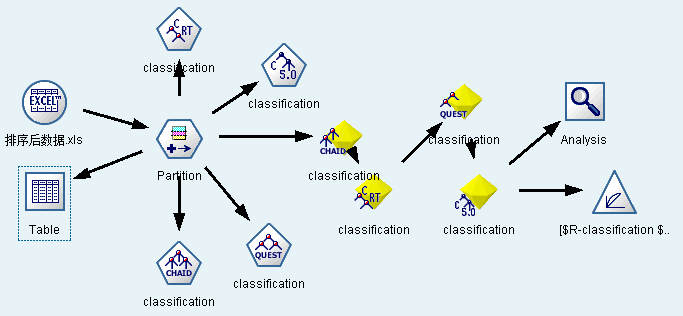
4.2.3 美食商户四种决策树模型对比分析 15
5总结 17
参考文献 18
附录 19
致谢 24
美食商户和消费者双向决策的数据挖掘分析
蒯云
, China
Abstract: The purpose of this article is to make a two-way decision for both merchants and consumers. Firstly, we select 6 first level indicators of specialty of the cuisine, merchant’s own conditions, price factors, publicity factors, mode of payment and after-sale service as the index of the important factors, and use entropy method to objectively empower them. Then we sort out the important factors with the radar picture of questionnaire data. Next, we use multinomial Logistic regression to model the star-grade and taste, environment and service scores of the merchants based on the data of Shang Pudong New Area food merchants. Finally, four methods of CHAID, CART, QUEST and C5.0 were used to analyze the data of food merchants in Pudong New Area. The results showed that the ranking of the importance of the 6 first level indicators were 82.62 points for specialty of the cuisine, 79.52 points for merchant’s own conditions, 74.71 points for mode of payment, 72.08 points for after-sale service, 69.83 points for price factors and 60.14 points for publicity factors. Meanwhile, multinomial Logistic regression method showed that the scores of taste, environment and service had a significant impact on the star-grade, different star levels have different scores on the three factors. Lastly, camparing with the above four different decision tree methods, it is found that the highest prediction accuracy of the CHAID model is 95.35%, and the result is the best. The options offered to consumers are: merchants with a taste score less than or equal to 6.8 points with environment score less than or equal to 6.9 points or taste score between 6.8~6.9 points with service scores less than or equal to 6.9 points are not recommended for consumers. If the taste scores are greater than 7.1 points, the consumers can choose them though the environment or service scores are slightly worse.
Key words:Influential factors of gourmet merchants; entropy method; multinomial Logistic regression; CHAID decision tree
1引言
1.1研究背景
这是一个“无网不入”的时代,随着科学技术的日益发展,网络给人们的工作、学习、生活带来了巨大的便利。网络的飞速发展促使电子商务迎来新纪元,使得电子商务与人们的生活密切相关。其中,餐饮行业在电商平台中占有大量份额,随着美团、大众点评等一系列平台的崛起,越来越多消费者青睐于网上选择美食商户,美食商户网上平台为餐饮行业带来新的生机,注入新的血液。2010年以来,越来越多的餐饮类网站如雨后春笋般横空出世,团购成为本地生活中最成熟的交易模式之一。基于以上原由,越来越多的学者致力于美食商家影响因素的分析,针对不同平台、不同地区的数据,层次分析法、回归分析、关联分析、结构方程等方法在此类问题中应用最为广泛。也有不少学者从顾客满意度角度出发,运用多种方法进行实证分析,得到顾客满意度与商家经营之间的关系。
综上来看,虽有很多学者对网上美食商家进行分析,但是如今网络发展迅速,信息更替快速,学者们对该问题的研究存在滞后性。同时,多数学者将角度定位于消费者的角度,对商户经营策略提供相关建议,但是近年来,我国学者鲜少有人对具体一个地区的美食商家进行实证分析,为消费者提供详实的参考意见。对于消费者而言,面多琳琅满目、良莠不齐的商家,如何快速选择优质商家已成为消费者非常重视的问题之一。
鉴于上述缘由,本文宗旨在于双向决策——对消费者和商家同时进行研究,为双方提供参考意见。首先借助问卷设计,得出消费者在网上选择商户时最为关心的影响因素数据,采用改进的熵值法来分析不同的因子权重,得出消费者最重视的影响因素,对商家提出一些合理的建议,帮助其提高自身竞争力。然后以上海市浦东新区大众点评网上的美食商家数据为研究对象,首先分析不同种类菜系与浦东新区陆家嘴、八佰伴等29个片区之间的关联分析,得出不同地区的美食偏好关系。然后,根据熵值法得出的结果用多项Logistic回归研究商户星级等级与口味、环境、服务得分之间的关系。最后用决策树方法为消费者选出最为优质的美食商户,为消费者在选择商家时提供重要的参考意见。
1.2国内外研究进展
虽如今电商经济发展迅速,餐饮商户与网络一体化也越来越符合当今经济发展的趋势。2013年,学者Z.Chen和Lurie[1]对在餐馆在线正、负面评论做研究,发现负面审查价值不包含评论的时间连续线索,并表明时间邻近线索增强了正面评价的价值,同时增加了选择具有正面评论的产品的可能性。J.A.Chevalier[2]通过两个网站研究消费者评论对书籍销售的影响。2015年,学者陈梅梅和薛阳阳[3]用因子分析法得出网购影响因素,然后将消费者聚类,发现不同消费群体,影响其购买决策的影响因素显著不同。同年,NING Lianju等[4]针对网上购物问题,从商品信息浏览偏好和在线评论的固有特性出发,注重于浏览数据和消费者评论的区间分布的统计分析,结果表明互联网上商品信息浏览时间分布是碎片式的并且可以通过胖尾效应来描述,且用户的浏览模式与信息的类型和信息的显示有关,这意味着图片的片段和标题的长度会影响点击率。2016年,学者夏萍[5]她用基于技术接受模型理论,对历年网络团购影响因素用回归分析定性研究,确定研究变量间内在联系。同年,陈华[6]从社交网络角度出发,构建S-O-R模型研究社交网络对消费者消费行为的影响,并运用结构方程模型进行实证分析。得出结论为社交网络中的正向情感能够促进消费者购买意愿。
本文采用熵值法、多项Logistic回归以及CHAID决策树对问卷设计数据和美食商户数据进行分析。迄今为止,熵理论已经得到了迅速的发展,理论逐渐成熟。国内外很多学者对熵理论进行研究,运用到各个学科领域。1856年,由物理学家鲁道夫克劳修斯(K.Clausius)首次提出;1870年,玻尔兹曼(L.Boltzmann)对熵理论进行微观拓展使其运用到分子运动和概率论上;1948年,克劳德.艾尔伍德.申农[7](Claude Elwood Shannon)在Bell System Technical Journal上发表的文章,在信息论中引进熵的概念,并给出计算信息熵的数学表达公式。随着信息熵的理论的日趋完善,熵渐渐渗透到生活的各个领域中。2000年,W. Steinborn和Y. Svirezhev[8]提出了基于熵增的农业生态系统可持续性的指标,在生态中心领域,过量熵随土地管理变化而变化。同时,熵值法在国内也得到迅速发展,早在1995年,顾吕耀和邱蔻华在决策分析中就定义了复熵的概念,之后,邱蔻华[9]用拓展熵来研究群组决策问题,使群组和个体决策系统得到优化。至2018年,叶雪强等[10]在单向预测模型的基础上,建立了熵值法组合预测模型,并用Markov链模型对其修正,增强了预测结果的可信度。熵值法在我国已有百年的发展史。
回归分析是确定两种或以上变量之间定性关系的统计方法,在诸多行业和领域的数据分析应用中具有广泛的作用。当被解释变量为分类变量且为三类以上时,一般采取多项Logistic回归模型,模型以公式和概率的形式表现,判别直观更加 ,便于一眼识别。多项回归模型广泛应用于高铁客运市场分析、藏文文本分类研究、医药学临床研究、高血压影响因素控制等诸多方面。
剩余内容已隐藏,请支付后下载全文,论文总字数:23818字
相关图片展示:

该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

