论文总字数:16462字
目 录
1 绪论 1
1.1 研究背景和研究意义 1
1.1.1 数据挖掘的应用前景 1
1.1.2 电子商务的发展现状 1
1.2 数据挖掘方法在电商领域客户细分的应用 1
2 方法介绍 2
2.1 研究目标的提出 2
2.2 K-means聚类分析 2
2.3 RFM模型 3
2.3.1 RFM模型介绍 3
2.3.2 RFM模型的应用 3
2.3.3 基于RFM模型的层次聚类 4
2.4 改进的RFM模型(RFML模型)介绍 4
3 实例分析 5
3.1 总体思路 5
3.2 数据收集 5
3.2.1 指标选择 5
3.2.2 数据预处理 5
3.3 客户划分 6
3.3.1 K-means聚类及基于RFM模型的层次聚类 6
3.3.2 RFML模型的应用 8
4 营销策略建议 10
参考文献 11
致谢 12
基于改进RFM模型的电子商务客户细分
钱新月
,China
Abstract:This paper introduces the basic concept of data mining and its application in the field of electronic commerce, focusing on the application of RFM and its improved model in e-commerce customer segmentation. Using the K-means clustering method, three types of indicators for customer segmentation were determined: the latest consumption, the frequency of consumption, and the amount of consumption. And according to three kinds of indexes, we cluster the e-business customers.
Then, optimize the current mainstream clustering algorithm: K-means, introduce the customer loyalty index, and then obtain the optimized RFML model. Subsequently, the e-commerce customers were subdivided into three categories, namely ordinary, important maintenance and development customers. For each type of customer's consumer demand and preferences, put forward a personalized marketing strategy.
Key words:Data mining; e-commerce; RFM model; K-means clustering analysis
1绪论
1.1 研究背景和研究意义
1.1.1 数据挖掘的应用前景
数据挖掘,亦可谓数据库知识发现,它是指从数据源中探寻有效的模式或知识的过程[1]。数据挖掘跨越了多个学科,且交融了多个范畴的实践和技术,如机器学习、统计、人工智能、信息检索等[2]。它是基于大量,带有噪声、非完全随机性应用数据,通过各种算法获取知识的过程[3]。 它能够借助于各种分析工具,在规模化数据中,获取模型和数据之间的对应关系,进一步可以经过分析实现预测,找寻数据间关联,是解决数据爆炸而信息匮乏的有效途径[4]。
近些年,市场竞争日益激烈,数据挖掘的重要性也开始日益突出,通过这些技术,可以针对相关的历史数据展开分析,进而为相关人员提供决策支持[5]。
1.1.2电子商务的发展现状
上世纪九十年代之后,科技的发展进入蓬勃发展期,网络用户在全球范围之内,也开始呈现出爆发式增长。尤其是互联网,其普及速度显然更快。在这一背景下,一种新型的商务运作模式开始出现,这也就是所以的电子商务模式。根据相关数据,在1998年之后,在全球范围之内,电子商务就有了极为快速的发展,几乎每九个月它的交易额就会提高一倍。由于网上访问一个电子商务网站几乎无需任何花费,许多在线商家经历着大量的访问量。例如,根据数据显示,就在2000年12月,亚马逊网站上就有大约2100万的访问者,而维多利亚的秘密品牌偶尔会经历巨大的流量高峰,每秒多达1000个访问者。新世纪,无疑是信息爆炸的年代,信息数据已经开始成为一种宝贵的资源。电子商务的出现,也是时代发展的必然结果,更是商业发展的必然之选。
1.2数据挖掘方法在电商领域客户细分的应用
数据挖掘是近年来研究的热点课题,已有众多学者投身于数据挖掘的研究,并取得了引人注目的成绩。在国内,学者俞驰在研究中,利用数据挖掘技术,对客户获取给予了系统研究,并构建了相应的获取系数模型,同时根据用户在网络上访问网站的轨迹分类信息,并结合相关阶段的客户,给出了差异性的数据挖掘方案[6]。在软件实现方面,学者谢佳斌也开始借助于模拟数据,通过 以及R等软件,对关联规则进行了研究,从而探究了该规则在购物车的应用情况,进而提出相应的带有辅助意义的营销策略[7]。学者徐翔斌等则借助于优化之后的RFM模型,对电商客户种类进行细分,并结合已有指标,增入一个总利润属性,进而完成RFP模型的构建。然后使用K-均值方法对电商客户进行了聚类分析,从而得出相关营销策略[8]。
以及R等软件,对关联规则进行了研究,从而探究了该规则在购物车的应用情况,进而提出相应的带有辅助意义的营销策略[7]。学者徐翔斌等则借助于优化之后的RFM模型,对电商客户种类进行细分,并结合已有指标,增入一个总利润属性,进而完成RFP模型的构建。然后使用K-均值方法对电商客户进行了聚类分析,从而得出相关营销策略[8]。
国外在电商领域的相关研究较多,大多认为买家的购物决策是基于动态的选择。例如,MOE Wendy W等提出了一种转换行为模型,即将商店访问转换为购买,即根据观察到的访问和购买历史预测每个客户的采购概率[9]。他们提供了一个个人层次的概率模型,它允许消费者在非常灵活的情况下具有异质性,允许参观在采购过程中扮演非常不同的角色。
总体来说,相关论文的研究更多面向于电子商务领域的数据挖掘以及顾客行为的预测和RFM模型本身,本文着重将介绍如何使用RFM模型实现客户的分类,以及如何改进RFM模型,将模型应用到实践中去,这样就能更好的实现精准式营销,相关的成本也会得到很好的节约。
2方法介绍
2.1研究目标的提出
在商业竞争日益激烈的大环境下,企业斩获新客户成本日益提升,因此,维系老客户的忠诚度就显得极为重要。在营销实践中,发展一个新用户的花费往往是维持一个老用户花费的5到10倍,所以,就必须要做好老客户维护工作。
对客户忠诚度带来影响的因素具有多元化,比如用户的偏好,营销模式等。但除去商家自身之外,其他因素都是不可控的。在这种情况下,作为商家,就需要对和客户有关的数据展开分析,找出影响客户忠诚度的因素。
所谓的聚类分析,就是对大规模数据集,按照相关的一致性原则,将其细分成诸多种类,进而让同属一类的数据,具有较为显著的一致性。而不同类的数据,却只有很小的相似性。当前,聚类算法相对较多,主要分属两大阵营,也就是结构和分散性这两种。它们当中的一些算法,在具体运算之前,还需要对分类个数进行明确,这些分类个数一般是从输入数据集产生的。
2.2K-means聚类分析
在社会经济研究中,“物以类聚”问题用聚类方法细分客户的行为特征,聚类分析是根据测量或表观相似性将数据组织成合理分组(簇)的技术和算法的研究[10]。该算法能结合相关的样本数据,根据数据特征,在没有明确分组标准的前提之下,结合相关的亲疏程度,完成自动化的分组。K-means聚类方法根据数据间的差异程度定义“亲疏程度”,通常会引入一个距离参数,对数据类之间的不同进行度量。
K-means算法:它将空间设置成k个中心,然后将与之相近的数据纳为同一个类别。由于K-means方法处理的聚类变量均为数值型,因此它把点和点之间的距离定义为欧氏距离(Euclidean distance),数据点x与y之间的欧式距离的数学定义为:
- EUCLID(
 ,
, )=
)=
上式中, 对应的为点
对应的为点 中的第
中的第 个
个 ;
; 则为点
则为点 的
的
 [11]。
[11]。
其算法过程如下: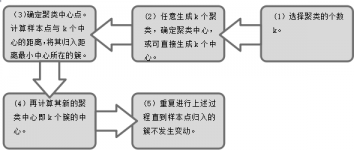
剩余内容已隐藏,请支付后下载全文,论文总字数:16462字
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

