论文总字数:12599字
目 录
摘要3
1绪论5
1.1课题来源以及研究意义 5
1.2本文主要研究内容 5
2图像预处理7
2.1灰度化 7
2.2降噪 9
2.2.1噪声的产生及分类 9
2.2.2图像降噪9
2.3二值化 12
2.4字符切分 13
3文字识别13
3.1特征提取 13
3.2 SVM 14
3.2.1原理介绍 14
3.2.2训练模型 14
3.3 实验分析14
3.3.1实验准备 14
3.3.2训练集的预处理15
3.3.3特征提取16
3.3.4 SVM训练17
3.3.5模型测试17
4结语展望18
4.1结论18
4.2不足与展望 19
5参考文献20
6附录20
7致谢22
基于SVM实现并优化文字识别
董富强
,China
Abstract: In this paper, the existing character recognition technology has been studied and analyzed, and some related modules have been optimized and improved. In particular, the main route of this method is as follows: 1) preprocessing of static image and text; 2) optimization of gray and two value method; 3) image denoising; 4) based on image feature analysis and character region projection, the characters are refined and segmented. 5) extract the features of images, train them based on SVM and classify them, and compare them with character vectors. The experimental results show that the system has a good effect on the recognition of the static image characters (Chinese characters and Arabia numbers), and the processing speed has been improved, but the results are not very good to be further improved when the other characters are mixed.
Key words: Image Processing Feature Extraction Machine Learning SVM Text Recognition
1绪论
1.1课题来源以及研究意义
利用计算机技术进行字符识别是模式识别的一个重要分支,有着广泛的应用场景:阅读翻译各种文献、车牌识别、支票处理、发票汇总处理、商品识别等等。这些年以来,随着计算机技术的迅速发展,人工智能的火爆促使模式识别技术不断取得新的进展。
在这样的背景下,文字识别技术作为人机交互过程中的一个重要模块,也有了新的要求。主要体现在两个方面:一个方面是文字识别的准确率,现在比较流行的文字识别算法都有比较高的准确率,均在95%以上,进一步提升较为困难且意义不大;另一个方面是文字识别的效率,效率即速度,在大数据时代,每天产生的数据量是十分巨大的,处理如此大的数据量,耗费大量时间以及财力等,所以优化哪怕1%的处理速度都具有着划时代的重要意义!
1.2本文主要研究内容
本文研究了目前较为流行的文字识别技术,对文字识别的不同模块进行了相应整合,在图片预处理模块上进行了相应的优化,利用SVM训练机器,进行了相应的实验,验证了该方法的准确率与效率。
1.静态图像针对不同文字提取的处理流程:
- 人工文字:
人工添加的文字一般来说有以下几个特点,文字大小固定,色调单一并且相对于背景色更为鲜明,分布较为集中,排列方式一般为横向或纵向。图1为示例图片。针对以上几个特征来设计相应的方法。具体实现分为以下几个步骤:图片预处理,包括灰度化,二值化,图像分割等。实现基于二值化聚类的图像文字提取。

图1 人工文字
- 场景文字:
场景文字为图像自身携带的文字,出现位置、大小、颜色、字体都具有不确定性,难以检测并捕获。比如说图像中的路牌等。如图2所示。自然场景文本检测定位的方法主要可以分为三类:基于连通域的分析、基于边缘特征的分析、基于纹理特征的分析[1]。

图2 场景文字(路牌等)
2.图片预处理算法:
- 版面分析:
图像拆分成行,投影法,笔画等宽算法(swt)去除非笔迹部分。
- 拆分字符:
连通域分析或直方图投影。
3.文字识别流程:
静态图像文字识别总体上分为两个模块:图像的预处理和文字识别。
图像的预处理:主要是灰度化、降噪以及二值化后得到的待识别文字区域,而字符切分则是对得到的待识别文字区域进行切分,分隔成单个字符,方便识别。而在预处理的过程中,重点主要是处理时的时间优化以及处理过程中参数值的选取。
文字识别:分为两部分:首先是对字符进行特征提取,然后将提取的特征送入SVM进行学习,在进行一定量的学习后,将未知的图像对应的特征与已知的特征进行对比,相似度高于一定值时,从而实现文字识别。这部分主要在于特征的提取,如何选取特征并且在耗费资源较少的情况下保证文字识别的准确率是研究的重点。
流程如图3所示:
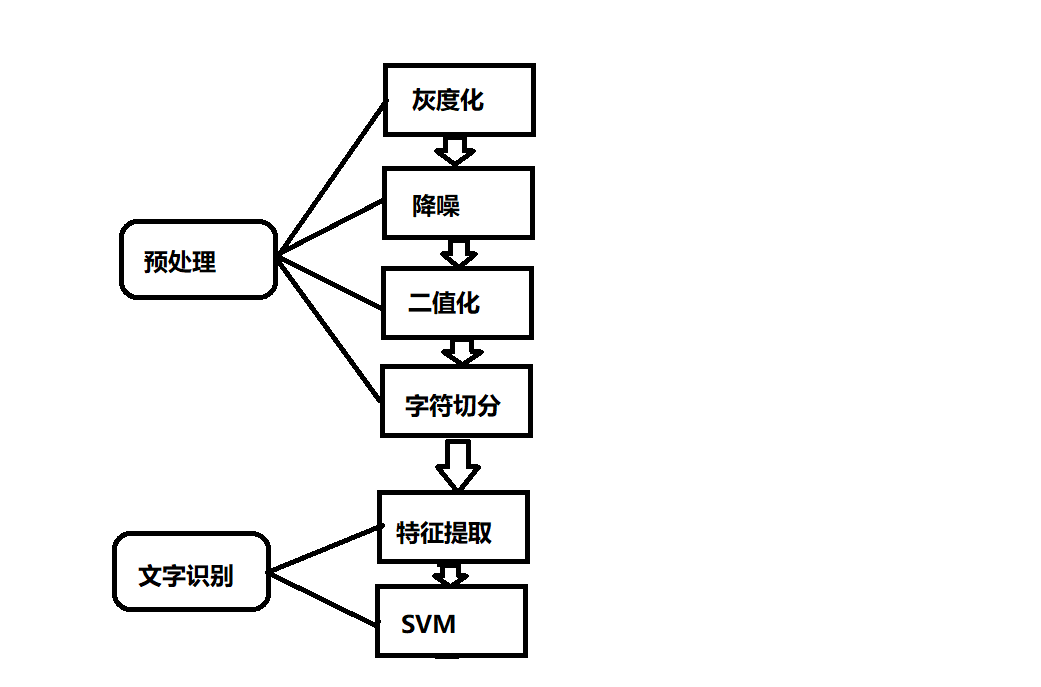
图3 文字识别流程图
2图像预处理
预处理:对未处理源图像进行操作以便后续进行特征提取、机器训练预处理的主要目的是减少图像中的无用信息以及噪声,并保持主要信息的完整性。一般有以下几个步骤:灰度化(如果是彩色图像)、降噪、二值化、字符切分以及归一化等等。
2.1灰度化
在一副彩色图像中,每个像素由三个分量表示,通常表示为RGB(red,green,blue)。通常,许多24位彩色图像存储为32位图像,而灰度化处理就是将一副彩色图像转化为灰度图像的过,具体方法是在RGB模型中,使彩色的red、green、blue三个分量值相等的过程,其中Red=Green=Blue的值叫灰度值[2]。因此,灰度图每个像素只需一个字节存放灰度值(又称强度值、亮度值),灰度范围为0-255,灰度值较大的为白点(灰度值为255表示白色),灰度值较小的为黑点(0表示黑色)。图像灰度化后便得到一副灰度图。
几种常见的灰度化方法:
1.分量法
将彩色图像中的三种分量的分量值单独取出来作为三个灰度图像的灰度值,根据实际应用场景需要选取合适的灰度图像[4]。
即
= = = (1)
2.最大值法
将彩色图像中的三种分量种亮度最大的分量值值作为灰度图的灰度值[5]。
即R=G=B=max(R,G,B)
f=max (2)
3.平均值法
将彩色图像中的RGB三种分量的分量值求平均,得到均值作为灰度值。
f= /3 (3)
4.加权平均法
依据实际需要,每种分量的重要性与其它的一些指标,将三种分量通过不同的权值比重做加权平均。根据多年实践发现,按以下比重对R、G、B三种分量进行加权平均能得出较优秀的灰度图像(MATLAB等软件也是采取的这种加权比重)。
f= 0.2989* R 0.5870* G 0.1140* B (4)
综合考虑,本文灰度化采用加权平均法对图像进行灰度化处理。
相应的程序也比较简单:
bool rgbToGray(unsigned char *src,unsigned char *dest,int width,int height)
{//src存储256个不同亮度值的RGB,dest存储灰度后的图像灰度值 width跟height表示图像大小
int r, g, b;
for (int i=0;ilt;width*height; i)
{
r = *src ; // 导入R
g = *src ; // 导入 G
b = *src ; // 导入 B
*dest = (r * 0.2989 g * 0.5870 b * 0.1140) ;//按照加权平均计算灰度后的值
}
return true;
}
计算灰度的方法已经确定,抛却方法不谈,待优化的只有计算过程。而优化转化速度最直接的方法便是将浮点数运算转换为整数计算(计算机存储的是二进制的数据,整数相比浮点数更为方便快捷)。比如我们可以将上式优化为
F=(300*R 587*G 114*B)/1000
对于计算机来讲,做大量除法运算也不是最为方便快捷的(计算机中除法实现与人类进行除法是相同的。通过不断找到合适的商跟余数),考虑到位运算(直接对存储在计算机中的二进制数据进行操作)可以代替除法运算并且更为方便快捷,这里采用位运算代替除法。
剩余内容已隐藏,请支付后下载全文,论文总字数:12599字
相关图片展示:




该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

