基于深度学习实现手写体文本的识别毕业论文
2020-02-19 18:14:30
摘 要
深度学习是一种以人工神经网络为架构,对数据进行表征学习的算法,目前广泛应用于对复杂结构和大样本的高维数据的学习,包括图像识别、计算机视觉、自然语言处理和自动控制等领域。
本文针对手写体文本识别的问题,对文本图像处理和汉字识别进行算法设计与分析,并进行了相关的实验。
在汉字文本图像处理方面,利用Ostu法实现文本图像的二值化,使用基于空间域的中值滤波法实现文本图像的去噪,并提出了行分离算法,两次使用分离算法,最终实现了文本图像的单字分离。
汉字手写体的识别工作一直以来都是机器学习的热门问题。因为汉字的笔画更加复杂,相似字较多,而且由于每个人的书写风格和习惯都不相同,所以手写汉字识别相对于其他手写字母的识别来说更为困难。因此,本文采用基于LeNet5改进而来的卷积神经网络,对汉字数据集HWDB1.1的子集进行了训练和评估,最终手写体汉字识别的准确率可以达到85%,取得了良好的效果。
关键词:卷积神经网络;文本图处理;手写体汉字识别
Abstract
Deep learning is an algorithm based on artificial neural network to represent data learning. It is widely used in the study of high-dimensional data of complex structures and large samples, including image recognition, computer vision, natural language processing and automatic control. And other fields.
The thesis designs and analyzes the algorithm of text image processing and Chinese character recognition for the problem of handwritten text recognition and carries out related experiments.
In the aspect of Chinese character text image processing, this thesis uses the Ostu method to realize the binarization of text images, and uses the spatial domain-based median filtering method to realize the denoising of text images, and proposes a line separation algorithm, which uses two separate algorithms to achieve the final The word separation of the text image.
The recognition of Chinese handwriting has always been a hot issue in machine learning. Because the strokes of Chinese characters are more complicated, there are more similar words, and since each person's writing style and habits are different, handwritten Chinese character recognition is more difficult than the recognition of other handwritten letters. Therefore, this paper uses the convolutional neural network based on LeNet5 to train and evaluate the subset of Chinese character dataset HWDB1.1. Finally, the accuracy of handwritten Chinese character recognition can reach 85%, and good results are obtained.
Key Words:Convolutional neural network;Text graph processing;handwritten Chinese character recognition
目 录
第1章 绪论 1
1.1 论文研究的背景和意义 1
1.2 国内外研究现状 1
1.3 本文研究的主要内容 2
第2章 相关理论基础 3
2.1 深度学习的基本思想 3
2.2 深度学习的训练过程 3
2.3 TensorFlow机器学习框架 4
2.4 深度卷积神经网络 5
第3章 汉字文本图处理 8
3.1 彩色文本图的二值化 8
3.1.1灰度化 8
3.1.2 二值化 8
3.2 文本图的噪音消除 11
3.2.1 噪音分类 11
3.2.2 噪音模型 11
3.2.3 噪音消除算法 12
3.3 文本图的字分离 13
3.3.1 行分离算法 13
3.3.2 行分离实验 14
3.3.3 字分离实验 15
第4章 手写体汉字识别 16
4.1 数据准备与预处理 16
4.1.1 HWDB1.1数据集 16
4.1.2 测试数据的标准化与归一化 17
4.2 模型结构 18
4.3 实验结果与分析 18
第5章 总结与展望 20
5.1 主要工作和结论 20
5.2 今后待解决的问题 20
参考文献 22
致 谢 23
第1章 绪论
1.1 论文研究的背景和意义
深度学习是一种模拟人类大脑结构的方法,该方法是一系列算法,通过模拟人脑感知一组感官数据中重要部分的方式找到输入数据的层次表示。1943年,美国的逻辑学家沃尔特皮茨和神经科学家沃伦麦卡洛克提出了第一个神经网络的数学模型,他们在开创性著作“神经活动中内在的逻辑微积分”中发表了他们提出的数学和算法的组合,旨在模仿人类的思维过程。1950年,图灵在他的论文“计算机器和智能”中提出了这样一台甚至暗示遗传算法的机器。1998年,燕·勒存发表了论文“基于梯度的学习在文本识别中的应用”,这表明在深度学习领域再次取得了进展。在2011至2012年间,Alex Krizhevsky在LeNet5的基础上进行改进得到了AlexNet,成功启动了深度学习社区卷积神经网络的复兴[1]。在2014年,由伊恩古德菲尔领导的一个小组推出了生成性对抗网络。目前,深度学习已经在图像、语音和自然语言处理以及大数据特征提取等方面获得了广泛的应用。此外,深度学习在搜索领域也获得了广泛的关注。
字符识别是一种允许计算机识别诸如汉字之类的手写或印刷字符并将其更改为计算机可以使用的形式的过程。1933年,美国科学家汉德尔使用OCR技术实现了文字识别。而后在1945年,出现了第一个字符识别工具[2]。但是针对汉字的识别研究工作却迟迟没有进展,其主要原因是汉字相对于其他语言文字来说复杂很多。《康熙字典》收录了近5万个汉字,虽然近代精简了很多生僻的古文字,但是总数依然不是一个数量级的差距。国家标准GB2312-80规定了常用的汉字个数为6763个常用汉字,其中一类汉字3755个,二类汉字3008个。另外,汉字当中相似的字符特别多,而且由于每个人的书写风格和习惯都不相同,都会导致汉字较难分辨。
随着深度学习的发展,基于深度学习的汉字手写识别势必会成为手写汉字识别的新的突破口。目前,基于深度学习的手写汉字识别方法主要有:基于CNN的端到端的识别方法和结合领域知识的CNN识别方法以及基于RNN/LSTM的文本行识别方法[3][4][5]。相对于传统的手写汉字识别方法,它们都可以通过学习样本数据的特征实现自主提取测试数据的特征,而不需要人工提取[6]。虽然目前手写汉字识别已经取得了很大的进展,但是在手写汉字识别领域依然有很多值得研究的问题亟待解决。
1.2 国内外研究现状
根据输入数据的类型,手写汉字识别分为联机手写汉字识别和脱机手写汉字识别。联机手写汉字识别是书写者通过物理设备(如触摸屏)将笔画信息实时传输到计算机中,计算机通过记录和分析笔尖运动的轨迹以识别表达的语言信息,而脱机手写汉字识别是把摄像头或扫描仪等图像设备采集生成的文本图像输入计算机中。由于,脱机手写汉字识别相比于联机汉字手写识别,缺乏实时有效的动态信息,因此脱机手写汉字识别的难度更大,准确率更低。对于脱机手写汉字识别,首先需要对文本图像进行分割处理得到单字图像后才能进行汉字识别研究工作。最早被广泛应用的汉字分割方法是直方图投影法[7],这种划分不同字符的方法是通过直方图来寻找字符间的空白区域实现的。随后又相继提出了动态规划算法、直接投影法[8]等。这些方法根据特征可大致分为三类,一是基于结构分析的分割,二是以识别为基础分割策略,三是基于模糊理论的分割方法。[7]
对手写汉字的识别工作可追溯到上个世纪60年代,当时,美国IBM公司开始进行了对印刷体汉字的模式识别研究。1996年,Casey和Nag通过模板匹配的方法成功识别出了1000个印刷体汉字[9]。近代以来,为了促进手写汉字识别的学术研究和基准,中国科学院自动化研究所国家模式识别实验室组织了三次竞赛。随着时间的推移,竞争的结果显示出进步并涉及到许多不同的识别方法,其中一个压倒性的趋势是基于深度学习的方法逐渐主导了竞争。第一次竞赛,所有团队提交的系统都是传统方法。第二次竞赛中,来自瑞士的IDSIA团队提交了基于卷积神经网络的系统并在脱机手写汉字识别上获得了第一名。带三次竞赛中,获得联机手写汉字识别和脱机手写汉字识别的第一名使用的系统都是基于卷积神经网络的。
深度学习方法可以直接从原始数据中学习判别式表示,因此可以为很多模式识别的问题提供端到端的解决方案。手写汉字识别最重要的领域知识包括字符形状归一化和方向分解特征映射。字符识别方面,有着诸如非线性归一化[10]、双矩归一化[3]、伪二次归一化[4]和线密度投影插值[5]等许多有用的形状归一方法。方向分解特征映射方面,有通过将梯度或局部笔划分解到不同方向从而获得多个特征图。为了提高汉字手写识别的准确率,有学者通过将directMap和convNet相结合,能够在同一框架下实现联机和脱机的最先进性能。此外,由于嵌入式领域的特定知识,还可以消除数据增加和模型集合的需求,这使得模型对训练和评估的过程都十分高效且有效。
1.3 本文研究的主要内容
在实际应用中,一般都是提供手写的汉字文本图,从中提取文字信息并进行单字识别。手写汉字文本识别主要包括两个部分:一是对文本图的处理,实现文本的分割,二是单字识别。
对文本图的处理主要包括彩色图像的二值化、文本图的噪音消除和文本图的行分离以及字分离。单字识别主要包括3个阶段:预处理阶段、训练和测试阶段和最后的验证阶段。
本论文的的第二章主要介绍基于深度学习实现手写汉字识别所需要的理论基础知识,第三章主要介绍汉字文本图的处理过程,第四章主要介绍单字识别的方法。
第2章 相关理论基础
2.1 深度学习的基本思想
假设要构建一个包含n层的系统S,表示为I=gt;S1=gt;…=gt;Sn=gt;O,其中I为输入,O为输出。若输入的I与输出的O完全一致,那么说明输入I在经过这个n层的系统变化之后没有任何的信息损失,只是在系统的每一层中有着不同的表现形式。但这其实是不可能发生的,根据信息论中的信息逐层丢失的说法,如果信息a先后经过处理得到b和c,那么a和b之间的互信息会大于等于b和c之间的互信息。这就说明了信息在传递的过程中会存在丢失的情况,而不会出现增加的情况。
对深度学习来说,其实就是把上层的输出当做下一层的输入,然后在整个系统中传递信息。前面要求输出的O与输入的I完全一致,这显然是不可能实现的。那么可以在完美情况的基础上放松一下限制,使得输出的O与输入的I尽可能的一致而不需要完全一致,这样就可以实现深度学习的基本模型。深度学习的实质是通过构建深度学习模型来训练大量的数据从而获取数据的特征。也就是说,深度学习的最终目的是获得相关数据的整体和局部的特征。
2.2 深度学习的训练过程
由于深度学习模型是由多个隐含层共同组成的,那么在训练深度学习模型的时候,就需要考虑到如果同时训练这些隐含层可能会导致时间复杂度过高,如果逐层训练,可能会导致误差的积累,从而使得结果偏差很大等这些问题。
为了解决上述的问题,2006年,Hinton提出了用于构建随机神经元的多层网络的无监督学习方法,该方法分为两步,第一步是每次训练一层网络,第二步是调优[6],使得自下而上的“识别”连接将输入转换为连续隐藏层中的表示和自上而下的“生成”连接从上一层中的表示重建下一层中的表示尽可能的相一致。具体方法如下:
首先构建整个深度学习模型,对每一层都单独训练,当训练完所有的隐含层后,再使用Wake-Sleep算法对模型中的参数进行微调。
Wake-Sleep算法的具体描述如下:
(1)Wake阶段:认知过程,使用识别权重自下而上驱动单元,在第一层隐藏层中产生输入向量的表示,在第二隐藏层中表示该表示,依此类推。
(2)Sleep阶段:生成过程,使用生成权重自上而下驱动网络中的所有单元,从最顶层的隐藏层开始,一直向下到输入单元。
深度学习的具体训练过程如下:
(1)自下而上的非监督学习:
首先使用数据集对模型的第一层进行训练,由于受限于模型的capacity,第一层会学习到数据本身的结构特征。相比于输入来说,第一层得到的数据形式表示特征的能力更强。然后将第一层的输出作为第二层的输入在此进行训练,以此类推,直到将所有层都训练完成,最终得到每个层的参数。
(2)自上而下的监督学习:
在得到第一步各层参数的基础上,再对整个模型各个层的参数进行调优,从而达到尽可能好的训练结果。
2.3 TensorFlow机器学习框架
TensorFlow是一个端到端的开源机器学习平台。在TensorFlow中,使用tensor表示数据,通过variable维护状态,使用graph来表示计算任务,graph中的节点被称之为op,在被称之为Session的context中执行图,如果想要为某一个操作赋值或者从中获取数据,那么可以使用feed或者fetch。
TensorFlow程序一般包含一个构建图的过程和一个执行图的过程。在构建图的过程中, graph中的节点的执行步骤会被描述成一个图,在执行图的过程中, 使用Session来执行图中的节点。构建图的第一步是创建源op,源op不需要任何的输入,例如常量。源op的输出被传递给其他op做运算。完成图的构建之后,才能开始执行图。执行图的第一步是创建一个Session的对象,如果没有对创建的对象进行任何的参数说明,那么Session将会执行默认图。在具体的实现上,为了充分利用计算机中可用的计算资源,TensorFlow 将定义图形的过程转换成了分布式执行。一般来说,编码人员不需要手动指定使用何种计算资源,TensorFlow会自动检测计算机中可用的计算资源。如果TensorFlow检测到计算机中存在空闲的GPU,那么就会优先使用这个GPU来执行上述的操作过程。当然,若计算机上的GPU不止一个, 那么TensorFlow不会使用其他的GPU,只会使用这一个GPU。如果想让TensorFlow使用其他的GPU, 必须明确将图中的节点op分配给它们计算。TensorFlow程序中的所有数据都使用tensor这个张量来表示, 在整个计算图中, 所有的操作之间传递的数据都是tensor。
TensorFlow使用SavedModel文件包来保存训练好的模型,还可以使用TensorBoard可视化来查看训练和评估的accuracy和loss值得变化过程以及所构建的数据流图,从而更加直观的了解整个训练和评估的过程。
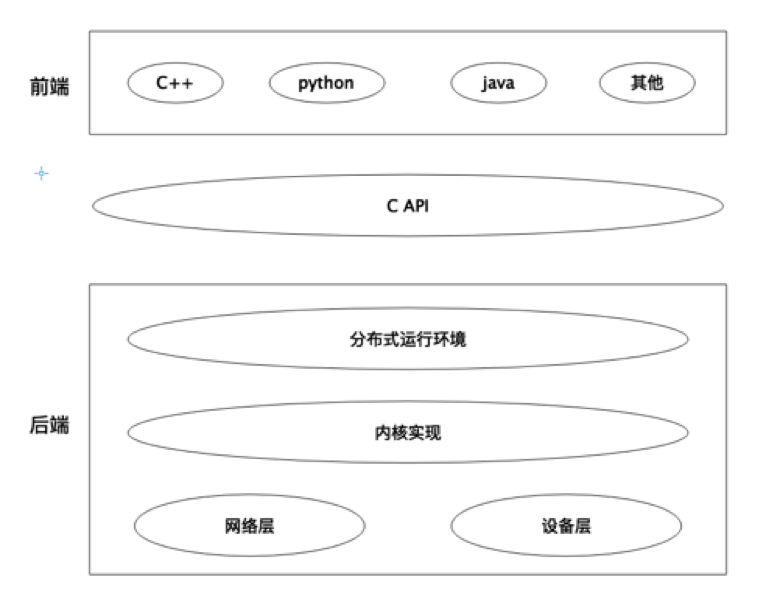
图2.1 TensorFlow 系统框架
由图2.1可知,TensorFlow的基本架构可以分为前端和后端。前端是基于支持多语言的编程环境,通过调用系统API来访问后端的编程模型。后端提供运行环境,由分布式运行环境、内核、网络层和设备层组成。[13]
2.4 深度卷积神经网络
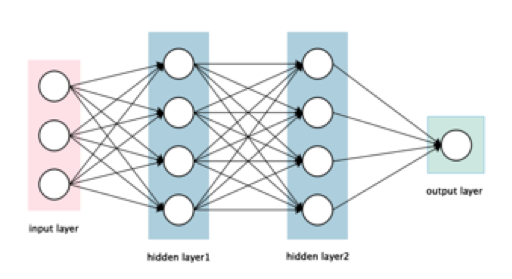
图2.2 简单神经网络结构图
深度卷积神经网络主要是由输入层、隐含层和输出层组成[6],其中隐含层包含卷积层、池化层、激励层和全连接层。
(1)输入层:深度卷积网络可直接将图片作为网络的输入,通过训练提取特征,但是为了获得更好的效果,通常需要将图片进行预处理。常见的数据预处理方式有以下几种:
均值化处理:对于给定数据的每个特征减去该特征的均值(将数据集的数据中心化到0)。
归一化操作:在均值化的基础上再除以该特征的方差(将数据集各个维度的幅度归一化到同样的范围内)。
PCA降维:将高维数据集投影到低维的坐标轴上,并要求投影后的数据集具有最大的方差(去除了特征之间的相关性,用于获取低频信息)。
白化:在PCA的基础上,对转换后的数据每个特征轴上的幅度进行归一化(用于获取高频信息)。
(2)卷积层:通过卷积运算实质是对输入进行另一种表示,若将卷积层视为黑盒子,那么可以将输出看作是输入的其他表现形式。
局部感知:对于给定的一张图片,人眼会习惯性地先关注那些重要的点,然后再到全局。局部感知就是将整个图片细分为多个有局部重叠的小窗口,然后通过滑窗的方式进行图像的局部特征识别。这也就是说每个神经元只与上一层的部分神经元相连接,只感知局部。之所以可以使用局部感知,是因为研究发现越接近的像素点之间的关联性就越强,反之则越弱。因此我们可以选择先进行局部感知,然后在全连接层将这些局部信息综合起来得到全局信息这样的方式。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示:







课题毕业论文、开题报告、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。


