自然场景图像文本定位和语种分类方法研究毕业论文
2020-02-23 18:22:25
摘 要
场景图像文本定位和语种分类是对自然场景图像中的文本区域进行定位,并且预测定位的文本所属语种的过程,属于计算机视觉和模式识别的一个分支。近年来,网络的快速发展使得图像的获取变得越来越方便。因此,如何准确、高效的定位和识别图像中所包含的高层次语义信息,对于充分发挥智能设备处理大数据方面的优势,使其像人一样快速、准确的识别图像中存在的文本内容有着重要意义。然而,由于目标文本和背景图像的不可预知性以及场景文本会受到不可控的光照条件等因素的影响,当前的技术仍面临很大的挑战。
本文主要从场景文本图像的定位和语种分类两个方面进行研究,主要工作和成果如下:
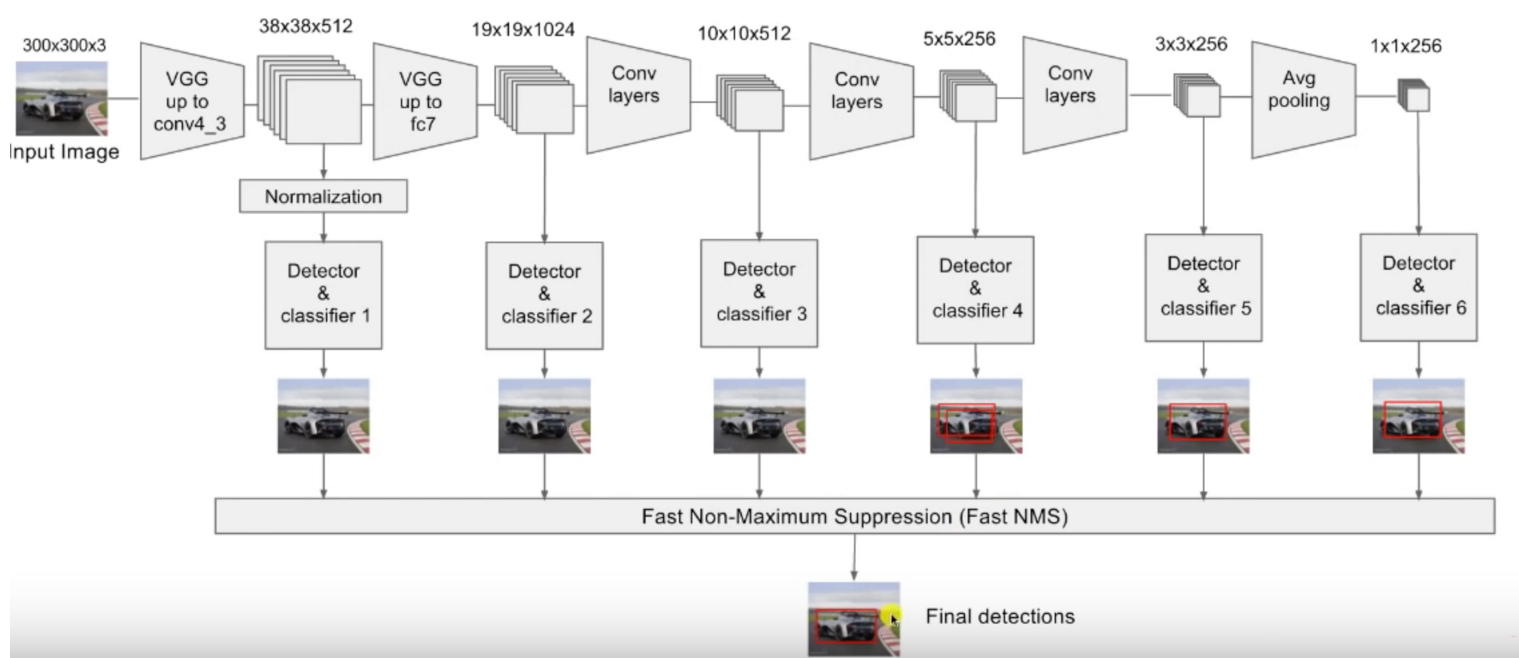
在场景文本定位过程中,构建了一个端到端可训练的适应不同字体、大小和方位的文本区域的深卷积神经网络模型。通过卷积神经网络提取图像特征,设计了一个基于SSD的文本对象检测器,用于区分文本对象和背景区域。
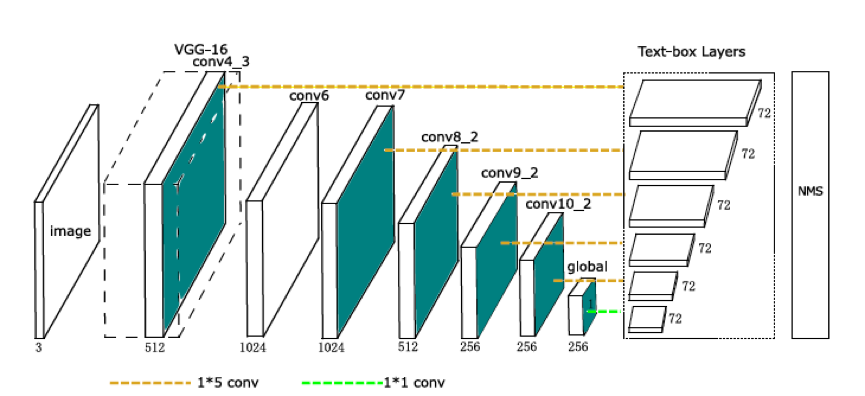
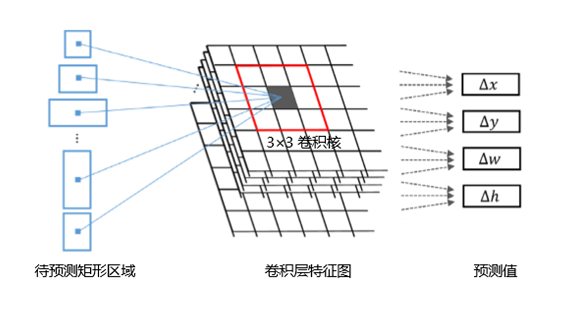
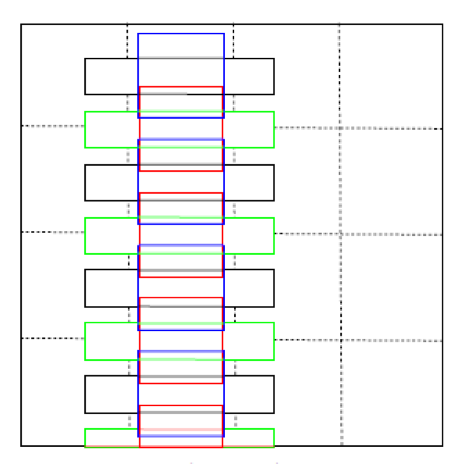
针对场景文本一般具有很大的宽高比问题,本实验将滤波器的尺寸由3×3修改为1×5。另外,在测试图片输入过程中,采用多尺寸输入来解决当前基于滑动窗口的文本定位方法在单尺寸输入时不能准确完成定位任务的问题。最后经过一个额外的非最大值抑制(non maximum suppression ,NMS)过程,得到最终的定位结果。将不同的滤波器应用于多个映射图中,可以在多个尺度上对目标文本进行检测,因此,对于相对低分辨率的输入也能实现较高精度的检测。
针对当前字符文本定位大多还只能够识别数字和英文字符的问题,本文基于Caffe 网络,构建了一种多种语言识别模型。可以对汉语、日语、韩语、英语、德语、俄语、西班牙语、拉丁语等八种语言进行识别,实验结果表明:该模型可以较好的完成场景文本图像中的文本区域定位和识别任务。
关键词;自然场景图像;文本定位;语种分类;卷积神经网络
Abstract
Text localization and language classification in scene image is a process of locating text areas and predicting what kinds of language they belong to in the natural scene images, which is a branch of computer vision and pattern recognition. In recent years, the high-speed development of the Internet has made it more and more convenient to acquire images. Therefore, how to locate and identify the high-level semantic information contained in the image in an accurate and efficient way is of great significance to makes it as fast and accurate as humans and give full play to the advantages of intelligent device in handling big data. However, due to the unpredictability of target text and background images and the influence of uncontrollable lighting conditions on scene text, the current technology is still facing great challenges.
This paper mainly studies the text location and language classification in the scene text images, and the main work and the results are as follows:
Firstly, in the scene text location process, an end-to-end deep neural network model that can adapt to different fonts, sizes, and orientations is constructed. Using convolutional neural networks to learn the characteristics of image features, an SSD-based text object detector was designed to distinguish between text objects and background regions.
Secondly, the size of the filter is changed from 3 3 to 1 5 in this experiment for the problem of wide/high ratio of scene text. In addition, in the process of testing a picture input, a multi-dimensional input is adopted to solve the problem that the positioning task is not accurately completed in a single-size input based on a text positioning method based on a sliding window. Finally, through an additional process of non-maximum suppression (NMS), the final positioning results are obtained. By applying different filters to multiple mapping graphs, the target text can be detected on multiple scales. Therefore, relatively low-resolution input can also be detected with high precision.
Finally, to solve the problem that most of the current character text localization can only recognize Numbers and English characters, we proposed a new kind of Caffe network. This model can work for multiple languages (eight kinds of languages ,such as Chinese, Japanese, Korean, English, German, Russian, Spanish and Latin), In ICDAR2017 (conference on document analysis and recognition) of MLT - Task1: Text Localization competition ,The recall rate reached 44.21% and the accuracy was 31.49%. The result shows that the model can complete the task of text location and language classification in scene text images well.
Key Words:Natural scene image ; Text detection ; Language classification; CNN
目 录
第 1 章 绪论 1
1.1 研究背景及意义 1
1.2国内外现状分析 2
1.3研究内容及目标 4
1.3.1研究内容 4
1.3.2研究目标 5
1.4技术路线 5
1.5结构安排 6
第 2 章 基于SSD的文本定位方法 7
2.1网络结构设计 7
2.2损失函数设计 9
2.3多比例输入 9
2.4非最大值抑制 9
2.5网络训练 10
2.6实验结果和分析 10
2.7本章小结 12
第 3 章 基于Caffe的多语种分类算法实现 13
3.1网络结构设计 13
3.2实验数据集 15
3.3多语种分类模型 16
3.4实验结果和分析 17
3.5本章小结 18
第 4 章 总结与展望 19
4.1本文工作总结 19
4.2未来工作展望 20
致 谢 21
参考文献 22
绪论
1.1 研究背景及意义
图像是人们认知环境最基本也最主要的信息来源。近年来,随着具备拍照或摄像功能的电子设备如智能手机、数码相机和监控摄像设备等的大规模应用和普及,图像的获取变得越来越方便。与文本和音频相比,图片具有直观、形式多样以及信息含量大等优势,因此图片正逐渐成为互联网信息传递的主流方式。场景文本图像中包含丰富的色彩、轮廓、结构等信息,也有丰富的文本信息,比如在道路标志,车牌以及产品的外包装中等。这些文本信息内涵丰富,既是对自然场景的重要补充,同时也是描述和理解场景内容、在更高层次认知影像的关键线索。但由于目标文本和背景图像的不可预知性以及场景文本会受到不可控的光照条件等因素的影响,当前的技术仍不能高效准确的提取图片中文本信息。因此,对自然场景图像的检测技术进行研究,尤其是针对不同的语种的场景文本进行定位有着重要的理论和现实意义。
从图像内容分析出发,分为感知内容和语义内容两类,其中,感知内容包含图像的颜色、灰度、形状、边缘等基于人类视觉心理学感知特征,而语义内容是对图像所隐含的类别、用途以及相互关系的描述。在文字和其他物体并存的场景,人们最先关注的往往都是场景中的文本信息,这些文本信息能更直观地反映图像内容,相较于其他元素更容易被提取和理解,而且很多文字的描述可以直接使用,用来实现于各种基于关键词的图像、视频内容检索和分析。因此,图像文本的研究获得了国内外学术界和大量IT工业届巨头的广泛关注。
场景文本图像中包含丰富的纹理、形状、轮廓等底层信息。读取场景文本有助于实现许多有用的应用程序。除此之外,自然场景还蕴含简洁、明确的语义信息。比如道路标志,车牌,书籍和物品包装袋上,这些文本信息内涵丰富,是对自然场景表现的重要补充,同时也是描述和理解场景内容、在更高层次认知影像的关键线索。尽管和传统的光学字符识别(Optical Character Recognition,OCR)[1],和FRCN(faster-rcnn)相似,但由于在图像获取过程中,受到不均匀光照、背景反射、运动模糊,噪声干扰等影响,实际获取的场景图像是复杂多变的。因为目标文本的不可预见性,以及各种复杂的背景纹理干扰,直接利用现有的 OCR 技术处理,识别精度低,对应用环境变化的适应性差。此外,在自然场景文本图像中,存在很大一部分的非文本区域,通过 OCR 进行排除,也会极大的影响识别速度。用传统OCR识别技术进行文本定位遇到了阻碍,因此,需要用新的方法来进行新的研究。
与一般对象检测不同,场景文本往往处于复杂的环境中,所以其定位面临一系列的困难和挑战,主要包括如:1.场景文本会以不同的尺寸、大小、字体和颜色出现[2],也可能在自然图像中存在倾斜或整体转动[3]的情况,甚至一个单词既可以拆开作为两个字符也可以合起来作为一个字符,如“好”,可以拆分为“女子”等,这些不确定因素很难通过一种方法来进行定位操作。2.自然场景文本经常会受到不同光照、阴影等条件的影响,这无疑会增加文本定位和识别的困难。3.场景文本区域会存在被其他物体遮挡的情况,以至会有不连续不完整的文本出现,这也会增加定位的难度。
自然场景文本图像识别主要是利用机器学习与模式识别技术,使计算机等智能设备能够像人一样快速、准确的识别自然界中普遍存在的文字,充分发挥计算机在处理海量数据方面的优势。现阶段,人们在不断的尝试各种基于场景文本提取的研究,如阿里支付宝的“扫福”活动,ETC车牌识别系统[4]以及未来的物联网都要进行场景文本的提取。因此,对自然场景的检测技术进行研究,尤其是针对不同的语种的场景文本识别有着重要的理论和现实意义。
1.2国内外现状分析
自然场景文本识别在计算机视觉领域具有不可限量的研究价值和应用前景,吸引了许多专家学者及国内外各大高校、研究院所的目光[5]。近年来,计算机视觉等领域的众多科研机构(如斯坦福大学、牛津大学、中国科学院自动化研究所、华中科技大学、北京科技大学等)和大量 IT 工业界巨头(如阿里巴巴、腾讯、百度、Google、Microsoft、Amazon 等)都在不断的对自然场景文本识别技术进行研究与攻关。
特别是近年来文档分析与识别国际会议(ICDAR)[6],国际计算机视觉与模式识别会议(CVPR),国际计算机视觉大会(ICCV),欧洲计算机视觉国际会议(ECCV)等顶级国际会议的举办更是将这一领域的权值不断提升。
就目前而言,国内外学者在该领域研究上投入了大量的时间和精力,催生出众多优秀的研究成果,在场景文本定位的发展过程中,目前的定位方法大致可以概括为两大类:基于连通域分析的方法[7][8]和基于滑动窗口(区域)[9]的方法。
1.2.1基于连通域的文本定位方法
基于连通域的文字定位算法是将整个图像的文本区域作为一个整体进行检测。主要想法基于大部分文本区域的像素具有一致的特性,比如颜色一致性和文本式样相似性,然后利用一些基于笔画宽带、长宽比、占空比的几何特征对非文字连通域进行排除,最后通过一系列启发式的规则将字符连通域组合成文本行。
笔画带宽变换( Stroke Width Transform ,SWT)[7]和最大极值稳定(Maximally Stable Extremal Regions,MSER)[8]是传统的文本定位方法中最为经典的方法。前者根据文字笔画宽带近似相等的特性提取字符连通域,后者利用字符笔画区域内灰度稳定特性提取图像中最大稳定极值区域作为候选文字。由于这两种方法能够提取复杂背景中不同尺度、方向和语言的文字,一系列基于这两种方法的文本检测方法相续被提出。基于连通区域的算法不会涉及太多的窗口,所以定位速度相对较快。但对于一些难以提取的如断裂和遮挡区域,则显得比较无力。
在ICDAR2011竞赛中,MSER算法可以将大多数文字区域从场景文本图像中提取出来,但同时也会提取到较多的非文字区域。尽管MSER算法可以解决大部分通常的文字,但对于一些异常情况如对于断裂和不完整文字的字符识别等,基于连通域的分析方式就会大打折扣。如在ICDAR2013的Text-location竞赛中,大部分基于MSER的算法无法对光照,模糊条件下的文本进行连通域的提取。此外,由于这种方法仅仅利用连通区域的特性,对每一个区域进行验证依赖于文本区域的尺寸和长宽比,而自然界中的文本没有固定的模式,因此会导致一些其他因素如栏杆和窗户,会被误认为是字符的情况出现。针对这些自然界中存在的普遍情况,提出对应的MSER改进办法,是当前传统方法需要着重考虑的问题。
近年来,随着深度神经网络在物体识别领域取得的巨大成功,尤其是其具有非常高的提取文字特征的性能,被广泛应用于自然场景文本检测中。人们通过将基于连通区域方法提取的候选文本区域输入深度神经网络进行文本和非文本的分类,极大的提高了文本定位的准确率。Huang 等人通过训练强大的卷积神经网络(Convolutional Neural Network, CNN)分类器有效排除非文本的最大极值稳定区域[10],从而极大程度上减少了误检率。基于先进的深度学习模型能够更有效提取和表达物体的高级特征,目前大量的研究学者们直接利用这些模型在像素级上进行文字和非文字的分类。例如,具有代表性的全卷积神经网络模型(Fully Convolutional Network,FCN)[11] 通过对场景文本图像多层次的卷积操作来预测图像中每个像素点属于文本的概率,进而直接提取整个文本区域。基于深度神经网络直接提取文本连通域的文本定位方法转换为语义分割问题,并直接作用于整个图像,提取高层特征进行分类,减少了后续处理的步骤。与传统的基于连通域的定位算法相比较,更加快速和准确。
1.2.2基于区域的文本定位方法
基于区域的文本定位方法,又叫做基于滑动窗口的文本定位方法,是通过多个尺度的扫描窗口策略和训练好的分类器来进行检测区域中文本和非文本的分类。
这种基于区域的定位方法主要通过多尺度的滑动窗口进行穷举查找,适用于标注-训练-定位的架构。但是为了不漏掉图片中的文本区域,基于滑动窗口的方法需要定义很多不同规模的窗口来适应图片中存在的不同字体,然后定义窗口的尺度和步长,利用不同的分类方法对窗口内的图像进行分析。检测的性能会受到训练和测试参数的较大影响。受计算机运算速率的影响,基于区域的文本定位方法在之前很长一段时间都存在有效率低下的问题。主要是因为滑动窗口需要在多尺度的图片输入下才能获得较好的结果,所以需要相当大的计算量。而且,在多尺度检测之后,通常还需要经过一个额外的非最大值抑制过程将多尺度的检测结果进行筛选才能得到最终结果。
Wang 等人[12]提取滑窗区域的梯度直方图特征(Histogram of Oriented Gradient,HoG)并通过随机森林分类器来提取文本区域。Wang 等人将滑动窗口区域大小设置为统一大小之后送入 CNN 分类器进行分类来获得文本区域。这种传统的利用穷尽搜索方式在每个滑动窗口中提取区域特征的方法十分耗时,低效。基于深度神经网络的目标候选区域回归方法通过一次扫描整体图像,在候选区域共享卷积特征进而分类的方法能够更加高效、精准的定位文本区域。例如,zhong 等人[13]设计了一个基于深度神经网络VGG-16的初始候选区域生成网络(inception region proposal network)对一系列固定的先验区域进行分类和回归操作以获得文本候选区域,然后提取候选文本区域在网络特征图中对应的区域并进行池化处理归一化大小后通过全链接层进行文本概率估计以及文本区域坐标回归。Liao 等人[14][15]提出的文本框(TextBoxes)提取方法采用 28 层的卷积神经网络,在多个卷积层中对预先设定的一系列区域进行文本和非文本分类以及文本区域坐标推测。Gupta 等人采用基于网格回归的 YOLO 网络来定位图像中的文本[16]。这类搭载深度神经网络的基于区域的文本定位方法采用回归模型,输入为整个图像,而输出则为图像中整个文本行或单词的方位,能更为便捷的实现端到端的场景文本识别。
近年来,随着机器学习和图像处理设备的不断发展,计算机视觉领域和模式识别取得了突破性的发展,许多相关任务(比如目标分类,曲径文本检测[17],轨迹检测等),相较于传统方法,基于CNN的滑动窗口定位算法效率得到了大幅度提高。但是在更高的水平上,图像处理遇到了新的瓶颈。要想取得新的突破,一个重要的方向就是尝试把视觉感受与其它模态的数据处理如内容识别结合起来[18][19]。近几年来,计算机视觉和模式识别[20]领域的文献增长速度十分惊人,说明场景文本定位和识别技术已经引起了国内外众多研究者的兴趣,计算机高精度,高效率处理图像信息的时代一定会到来。同时,我们也应认识到现在仍存在一些缺陷和不足,主要体现在:1,如何准确定位不同语言的自然场景文本;2,大部分的识别系统仅仅针对于英文字符,对不同的语言不具有普适性和鲁棒性。
1.3研究目标及内容
1.3.1研究目标
自然场景文本识别的目的是通过机器学习与模式识别技术,使计算机、智能移动设备等能够像人一样快速、准确的识别自然界中普遍存在的文字。本项目针对现有的自然场景文本识别方法对任意方向和不同语言适应性差的问题,拟构建一套基于方位回归及语言分类的多任务一体化的端到端场景文本定位模型,来应对自然场景文本不同方向和不同语言的文本定位和分类任务。主要研究目标为通过一个模型来定位不同语言的文本区域并同时进行语种分类。
1.3.2研究内容
(1)研究场景文本定位过程中,构建于同一卷积神经网络之上适应不同字体、大小和方位的文本区域的方位回归和语言预测一体化网络的设计方法,以及其损失函数结构组成。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示:



课题毕业论文、开题报告、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。


