车辆重识别方法研究毕业论文
2020-03-30 12:15:56
摘 要
车辆重识别,是通过一个摄像头用目标车辆检索多台摄像机检测到的车辆,是作为刑事调查技术的视频调查应用程序中的一个重要问题。研究该问题有着非常重要的现实意义,同时也面临许多挑战。以前的方法主要集中在车辆分类、车型识别,不能识别具体车辆。另外,从监控视频中提取的图像质量较差,分辨率不高,并且还存在光照和视角的差异,给识别技术带来了诸多困难。
基于以上问题,本文主要研究了基于局部最大出现(LOMO)的特征提取和基于欧氏距离的距离度量的算法,围绕着这两个方面开展研究。在特征提取方面,为了解决光照与视角存在的问题,本文采用Retinex算法进行了图像增强,以及基于滑动窗口的方法上采用HSV直方图和SILTP直方图进行特征提取。在距离度量方面,本文采用传统的方式欧氏距离对样本之间进行相似度计算。
在Vi-Ri数据集的基础上进行了大量的实验,研究结果表明本文所采用的算法有较高的性能和准确性,提升了车辆重识别的效果。
关键词:车辆重识别;特征提取;距离度量;评价指标
Abstract
Vehicle Re-identification is an important issue in the video survey application as a criminal investigation technique by using a camera to retrieve vehicles detected by multiple cameras using the same vehicle. Studying this issue has very important practical significance, and it also faces many challenges. The previous method mainly focused on vehicle classification and could not identify specific vehicles. In addition, the quality of the image extracted from the surveillance video is poor, the resolution is not high, and there is also a difference in illumination and viewing angle, giving recognition technology has brought a lot of difficulties.
Based on the above problems, this paper mainly studies the feature extraction based on Local Maximum Occurrence (LOMO) and the distance metric algorithm using Euclidean Distance, and studies around these two aspects. In terms of feature extraction, focusing on illumination and viewing angle problems, image enhancement using the Retinex algorithm, and HSV histogram and SILTP histogram feature extraction based on the sliding window method. In terms of distance metrics, this paper uses the traditional way of Euclidean Distance to calculate the similarity between samples.
A large number of experiments were performed on the basis of the Vi-Ri data set. The research results show that the algorithm used in this paper has high performance and accuracy, and improves the effect of vehicle re-identification.
Key Words:Vehicle Re-identification;Feature Extraction;Distance Metric;Evaluation Index
目 录
摘 要 I
Abstract II
第1章 绪论 1
1.1 研究背景和意义 1
1.2 研究现状 1
1.2.1 国外研究现状 1
1.2.2 国内研究现状 2
1.3 主要内容 3
1.3.1 基本内容 3
1.3.2 组织结构 4
第2章 算法设计 5
2.1 特征提取算法 5
2.1.1 颜色特征提取算法 5
2.1.2 纹理特征提取算法 5
2.2 相似度算法 7
2.2.1 欧氏距离算法 7
2.3 评测算法 7
2.3.1 CMC评测算法 7
2.3.2 MAP测评算法 8
第3章 系统设计 9
3.1 需求分析 9
3.1.1 系统意义 9
3.1.2 功能分析 9
3.2 系统设计 11
3.2.1 流程分析 11
3.2.2 接口设计 14
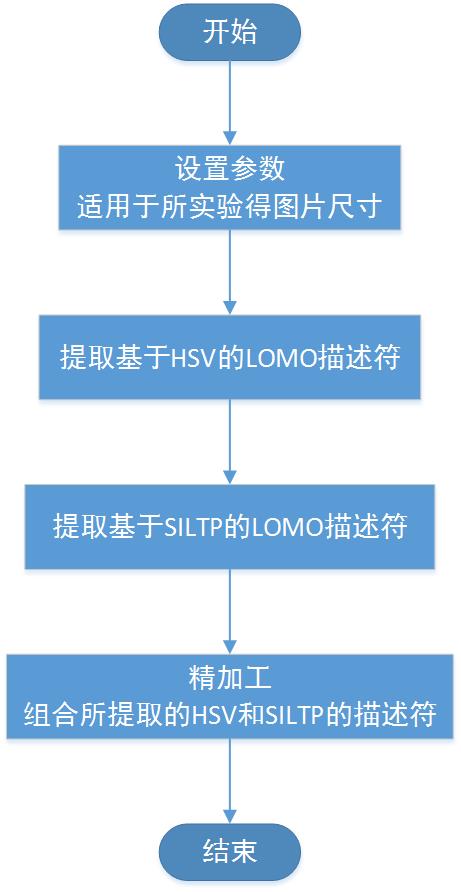
3.3 LOMO特征算法 15
3.3.1 算法描述 15
3.3.2 基于HSV的LOMO表示 16
3.3.3 基于SILTP的LOMO表示 16
第4章 实验测试与评测 18
4.1 实验测试 18
4.1.1 编程语言与开发环境 18
4.1.2 Ve-Ri数据集 18
4.1.3 系统测试 19
4.2 系统评测 21
4.2.1 CMC评测算法 21
4.2.2 MAP评测算法 23
第5章 总结与展望 25
5.1 工作总结与展望 25
参考文献 27
致 谢 29
第1章 绪论
1.1 研究背景和意义
汽车,公共汽车和卡车等汽车,已成为人类生活中不可或缺的一部分,也是重要的城市监控系统中的一类物体。计算机和多媒体视觉领域的许多研究人员都将重点放在与车辆相关的研究上,例如车辆检测等。而车辆重识别就是一个重要而又前沿的领域,以查询车辆作为输入,给定一个监控车辆图像,旨在搜索监控数据并找到由不同摄像头记录的相同车辆,可广泛应用于智能监控系统,智能交通和城市计算。通过无处不在的监控网络,它可以快速告诉用户车辆在城市的何时何地。
车辆重识别可以视为一个实例级别的对象搜索任务,这与传统的车辆检测,跟踪和分类问题不同。类似于近似重复图像检索,基于内容的视频搜索和对象实例搜索,车辆重识别将从城市监控视频中找到具有相同身份的车辆。在现实世界的实践中,人类可以以渐进的方式处理这项任务。例如,如果安全人员需要在具有大型视频监控网络的城市中找到嫌疑车辆,则可以初始使用诸如模型,类型和颜色的外观属性来找到类似的车辆并减少搜索领域。然后,他们可以通过匹配车牌来精确识别过滤车辆的目标,这可以减少巨大的工作量。与此同时,他们将搜索由近处到远处摄像机拍摄的视频以及从近处到远处的时间范围。
因此,车辆重识别,即在多个摄像头拍摄区域下用同一车辆自动检索目标的技术,逐渐受到许多研究者和科研机构的重视。本文课题车辆重识别将着重研究如何从不同的监控视频中提取出目标车辆的特征信息进行筛选最终确认。但是基于实际摄像生活中的复杂性和特殊性,车辆重识别问题仍然面临诸多的挑战,因此这项研究具用重大意义。
1.2 研究现状
1.2.1 国外研究现状
近几年以来,有许多的国外研究人员对基于图像的车辆识别技术相继提出了一系列新的研究成果。
2007年,Kazemi等人提出了应用3种不同的特征提取器来识别和分类5种车辆模型,其使用了快速傅里叶变换、离散Curvelet变换以及离散小波变换来提取车辆的特征,该系统在所有曲折波系数中使用0.1的车辆模型时的正确率较高,该提取器的性能较好[1]。
2008年,G.Fung等人提出了一种基于典型交通图像序列中车辆运动的车辆形状逼近方法,不是直接使用2D图像数据,而是以单目图像序列估计固有3D数据,采用了基于特征点的估计,得到车辆的高度轮廓和尺寸,从而对车辆进行识别,但由于其对于视频的精确度要求过高,并且容易漏掉车辆的轮廓信息,因此比较不容易应用到实际生活中来[2]。
2008年,Rahti等人提出了一种车辆识别新算法的系统,该识别系统基于图像Contourlet变换性能提取特征,实现从不同子带和各个方向上Contourlet系数矩阵的标准差,经过实验结果表明,系统在识别车辆模型中的正确率较高[3]。
2009年,D.R.Lim 等人提出了一种使用摄像头作为传感器识别移动车的汽车识别系统,其中使用了Gabor滤波器进行特征提取,该系统主要针对具有各种照明(日光和夜间)的各种类型的车辆进行,其虽然提高了实时性,但同时也降低了车辆识别的准确率[4]。
2009年,Zafar等人提出了一种新颖的Contourlet变换域中的局部特征检测方法,与先前提出的基于Contourlet的车辆MMR方法相比,该方法能够将分类率提高较多,其识别率显著增加[5]。
2010年,Iqbal等人在广泛的实验环境中评估了各种基于全局和局部特征的车辆图像在受控和非受控条件下拍摄时的强弱,引入了一个具有挑战性的数据库,结合Sobel与Sift算法对车型提取特征,其捕获的车辆图像的一级识别精度为65%,但提取的用于识别的车型特征维数较高,车型分类的正确率低,而且识别的车型种类少[6]。
2014年,Yin TIAN等人提出了一种使用多个传感器节点来完成车辆识别,该方法根据不同节点获得的一个车辆签名的匹配结果,确定车辆状态并校正签名分割,还得到了签名之间的相互关系,并通过这样的方式校正了时间偏移 通过最大似然估计融合校正后的签名,从而获得更准确的车辆签名,有较高的准确性[7]。
2017年,Xinchen Liu等人出了一种基于深度神经网络的预测车辆重新识别框架PROVID,不仅利用大规模视频监控中的多模态数据,如视觉特征,车牌,摄像机位置和上下文信息,还考虑了车辆重新识别的两个渐进过程:从粗到细的搜索特征域以及物理空间中的近距离搜索,采用VeRi数据集的大量实验证明了渐进式车辆重新识别框架的准确性和效率[8]。
1.2.2 国内研究现状
同时,这些年里,国内的一些研究人员也对基于视频图像的车辆识别技术有了一些初级阶段的研究,研究重点更主要集中在如何有效的提取车辆特征。
2009年,周爱军、杜宇人提出了一种基于Harris角点检测的识别方法,该方法利用率Harris角点检测方法得到车型的角点信息,但是由于噪声和阴影,使得得到的车型边缘信息不全面、边缘位置错位或产生变化,从而出现车型特征失效,使得车型识别准确率较低[9]。
2009年,秦克胜等人提出了利用图像局部匹配方法定位出目标车辆在图像中的位置,其对摄像机采集的图像进行去除背景的运算以获取车辆图像,主要用于车辆侧面的情况,其不足之处是受各种外界环境的干扰较大,存在提取特征不唯一或不完整情况,车型识别率低[10]。
2010年,马蓓、张乐等人提出了基于纹理特征的汽车车脸车型识别方法,通过基于灰度共生矩阵的纹理分析,得到纹理特征值,即待识别车型的纹理特征,将得到的纹理特征值作为目标车辆的特征量,其缺点是当图像分辨率发生变化时,计算得到的纹理特征会产生较大的误差,从而降低识别率,而且实时性较差[11]。
2010年,黄灿提出了一种自动检测和识别汽车类型的方法,首先用Adaboost的学习算法检测图片中是否有正面的汽车并得到车辆的头部区域,然后提取局部特征,对结果进行匹配分析,其缺点是车型识别的算法复杂,识别速度低,实时性不好[12]。
2012年,康维新等人提出了复合的图像匹配模型与识别方法,先应用Harris角点对车型初分类,再应用SIFT特征进行细分类,该方法与只利用SIFT特征进行识别的方法相比,在保证识别准确性基本不变的情况下,减少约2/3的处理时间,使得实时性得到较大改善[13]。
2013年,方文华等人提出了一个两阶段策略来实现现实监控视频中的车辆重新识别还提出了一种能够基于零件外观相似性和时空约束模型的相似性度量方法,其引入了时间-空间的关系,在真实世界的数据集上进行的定量和定性实验都验证了所提出的方法的有效性,但在相似性测量上采用简单的欧氏距离,准确性不高,若集中到度量学习,对车辆时空关系的深入分析也是关键[14]。
2014年,王亦民提出基于遮挡去除的块集合表示与匹配方法和基于特征投影矩阵的特征变换模型,分别从特征表示、特征变换和距离度量等三个方面开展研究,实验结果表明,基于k近邻局部距离度量技术能够明显提升距离函数的判别能力,最终重识别性能提升3-5%,其结果有较高的准确率[15]。
2017年,姚磊提出基于自适应间隔最近邻(AMNN)的距离度量学习算法和基于尺度渐变曲面(SDSF)的行人重识别方法,围绕"动态度量"和"多维度表达"两个核心思想展开研究,设计并实现了一个公开的重识别系统,实验分析表明有较高的识别率和准确率[16]。
1.3 主要内容
1.3.1 基本内容
基于实际生活,本系统着重研究如何在真实摄像视频下对车辆特征的提取,如何解决图像分辨率低下的问题,如何从不同监控中筛选出目标车辆等。
1)对于车辆特征提取,构建一个两步过程的渐进式车辆搜索框架:
在特征域中进行提取搜索,利用一些外观特征例如颜色、纹理等快速的过滤器,从而找到相同的车辆;
在物理世界中从近到远的搜索,将时间和位置视为车辆搜索的关键线索。
2)对于不同摄像头下的车辆特征变化,应用图像增强的思想。
3)将提取出来的特征在图片之间进行比较筛选,通过加权比较,特征匹配,从而确定目标车辆。
1.3.2 组织结构
本文共包括五个章节的内容,各章节内容概述如下:
第一章为绪论。首先介绍并论述了本文的研究背景和意义,然后剖析了车辆重识别领域国内外的研究现状,以及当前所面临的一些关键问题,最后介绍了本文的主要内容和工作。
第二章为设计方案。主要介绍了本文所采用的一些基础算法的原理和意义,包括特征提取中的颜色特征提取和纹理特征提取的算法,距离度量中的欧氏距离算法和评测算法。
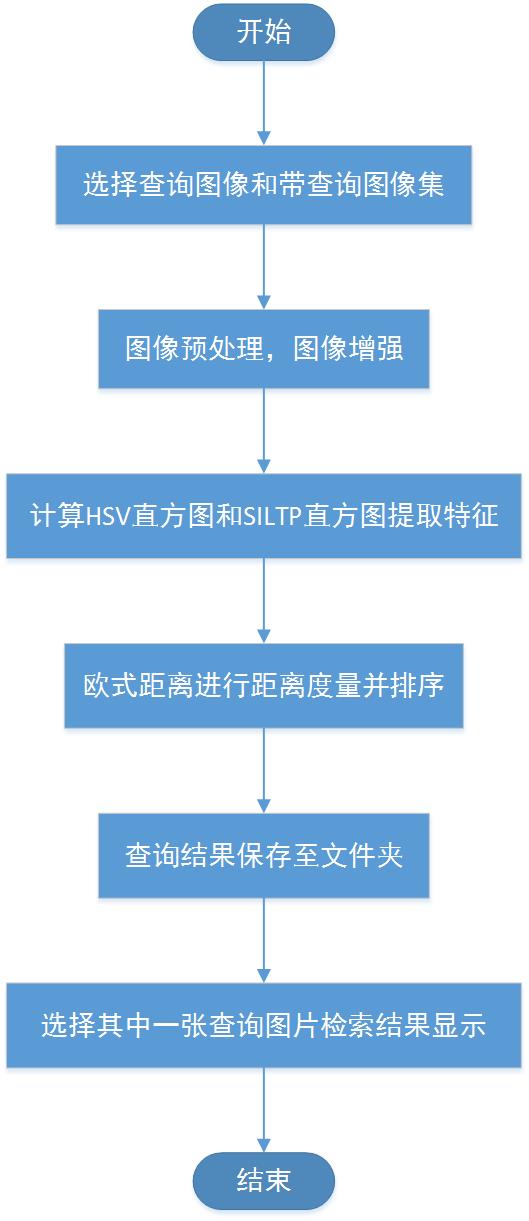
第三章为车辆重识别的系统设计。首先介绍了本文系统的需求分析,剖析了系统的意义和功能,接着介绍了系统的流程和接口,然后解释了系统所涉及的关键算法,最后说明了系统所用的编程语言和开发环境。
第四章为实验结果与测评。首先说明了实验所使用的数据集,然后详细叙述了实验的具体过程和最终得到的结果,最后对系统进行了测评。
第五章为总结与展望。首先对本文的工作进行了全面的总结,讲述了本文的研究成果,最后分析了本文研究工作的不足和有待改进的地方,以及对未来研究工作的展望。
第2章 算法设计
2.1 特征提取算法
2.1.1 颜色特征提取算法
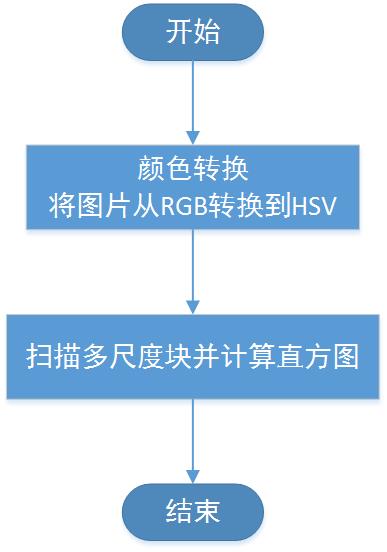
本系统主要采用HSV直方图来提取颜色特征。
RGB (Red、Green、Blue)颜色空间:一种色光表示模式,其中R、G、B三种颜色成分的取值范围是0-255,R、G、B均为255时就合成了白光,R、G、B均为0时就形成了黑色[17]。
HSV(Hue、Saturation、Value)颜色空间:一种面向视觉感知的颜色模型,反映了人眼对色彩的感知和鉴别能力,色调H表示从一个物体反射过来的或透过物体的光波长,即光的颜色,饱和度S表示颜色的深浅程度,亮度V表示人眼感觉到的光的明暗程度,与物体的反射率成正比[17]。
一幅图像中的RGB值(R,G,B)可以通过非线性转换到HSV空间值(H,S,V),将RGB颜色空间转换为HSV颜色空间,其转换公式如下:
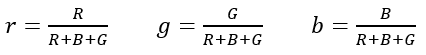 (2.1)
(2.1)
设,定义为:
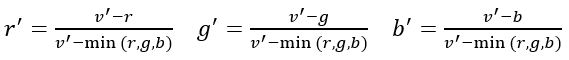
(2.2)
则,,
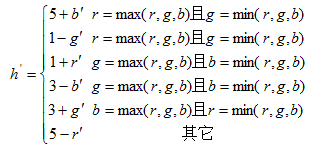
(2.3)
其中,
HSV直方图:根据图像中每个像素出现在色彩空间的概率统计而成的,计算颜色直方图需要将颜色空间划分为若干个小的颜色区间,每个区间成为直方图的一个柄(bin) [17]。
2.1.2 纹理特征提取算法
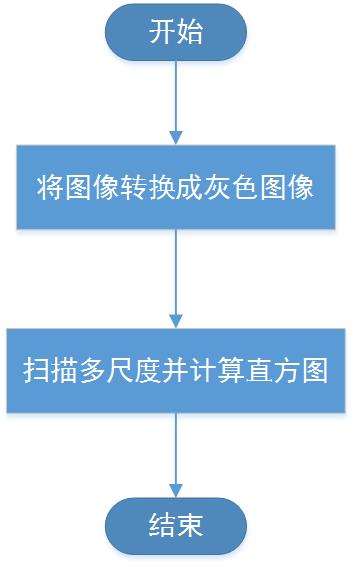
纹理特征提取有多种算法,从LBP到SILTP,本系统主要采用SILTP算法,在论文[18]中有详细介绍。
LBP纹理特征:用来描述图像局部纹理特征的算子。在3*3的窗口内,以窗口中心灰度值作为为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0[19]。
LBP旋转不变模式:不断旋转圆形邻域得到一系列初始定义的LBP值,取其最小值作为该邻域的LBP值[19]。
LBP等价模式:当某个LBP所对应的循环二进制数从0到1或从1到0最多有两次跳变时,该LBP所对应的二进制就称为一个等价模式类[19]。
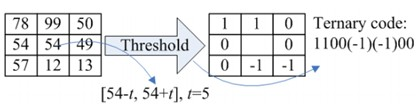
LTP纹理特征:使相对中心值变化在t范围内的邻域量化为0;比大于t的量化为1;比小于t的量化为-1,如图2.1所示[20]。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示:


课题毕业论文、开题报告、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。


