C语言子集编译系统的设计与实现毕业论文
2020-04-04 10:49:04
摘 要
编译原理作为计算机专业的一门必修课程,学习编译原理能够了解高级语言向低级语言翻译转化的过程与本质,从而进一步提升程序设计能力。因此,本文的研究目的是开发一个能够实现全套编译过程包括词法分析,语法分析,语义分析,目标文件生成,链接生成可执行文件的编译系统,在设计系统与编码的过程中加深对编译汇编链接这个过程的理解。
本系统选定的高级语言为C语言的子集,实现C语言中的部分功能。选用C语言进行编码, Visual Studio 2017作为开发工具,采用GitHub for Visual Studio 作为版本管理迭代工具。主要工作为:设计编译系统所选定的源程序语言文法,建立相关文法系统;在文法系统设计基础上,确定系统模块结构,并对各个功能所需要的数据结构进行设计与编码实现;最后,对系统所实现的功能进行测试,测试系统功能实现与运行的相关情况。
本文实现的C语言子集编译系统能够对合法源程序进行编译,编译过程中进行词法的染色,语法结构的缩进,生成COFF中间文件,最终链接生成EXE可执行文件。另外,对于存在错误的源程序,能够对其中存在错误的行进行定位并提示出错信息,方便进行Debug。
关键词:编译系统;C语言子集;链接器
Abstract
Compilation principle is a compulsory course for computer majors. Learning compiling principles can understand the process and essence of translation from high-level language to low-level language, thus further enhancing program design capabilities. Therefore, the purpose of this paper is to develop a compilation system that can implement a full set of compilation processes including lexical analysis, syntax analysis, semantic analysis, object file generation, and link generation of executable files. And it can deepen the understanding of the process of compiling assembly links during the design of systems and coding.
The high-level language selected by this system is a subset of the C language and implements some of the functions in the C language. The C language was used for coding. Visual Studio 2017 was used as a development tool and GitHub for Visual Studio was used as a version management iteration tool. The main tasks are: designing the source program language grammar selected by the compilation system and establishing the related grammar system; determining the system module structure based on the grammar system design, and designing and coding the data structure required for each function; finally, Test the functions implemented by the system and test the system function to achieve the relevant conditions of operation.
The C language subset compilation system implemented in this paper can compile legitimate source programs, lexical coloring during compilation, indentation of grammatical structures, generation of COFF intermediate files, and finally link generation of EXE executable files. In addition, if there is an error in the source program, it is possible to locate the error line and give an error message to facilitate debug.
Key Words: compilation system; C language subset; linker
目 录
摘 要 I
Abstract II
第1章 绪论 1
1.1 研究目的及意义 1
1.2 国内外研究现状 1
1.3 论文主要内容与章节安排 2
第2章 文法设计 4
2.1 文法相关分类 4
2.2 文法表示形式 5
2.3 字符集 6
2.4 词法定义 6
2.4.1 关键字 6
2.4.2 标识符 6
2.4.3 整数常量 7
2.4.4 字符常量 7
2.4.5 字符串常量 7
2.4.6 运算符以及分隔符 7
2.5 语法定义 7
2.5.1 外部定义 7
2.5.2 语句 9
2.5.3 表达式 12
第3章 词法分析设计与实现 15
3.1 目的及实现方式 15
3.1.1 任务要求 15
3.1.2 实现方式 15
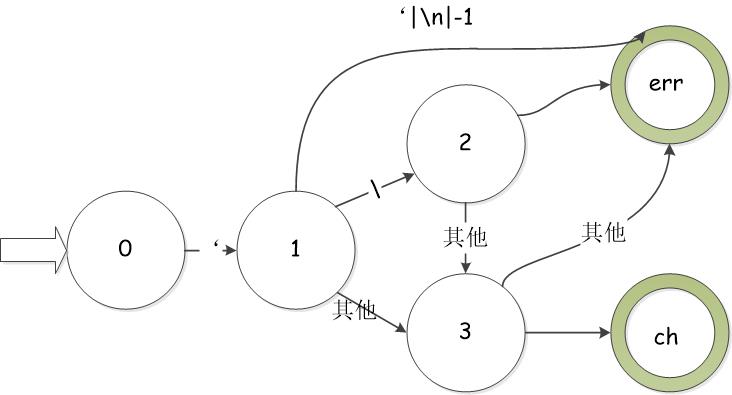
3.2 有穷自动机 16
3.3 相关数据结构与算法 19
3.3.1 数据结构定义 19
3.3.2 算法 21
3.4 结果与测试 21
第4章 语法分析设计与实现 23
4.1 目的及实现方式 23
4.1.1 任务要求 23
4.1.2 实现方式 23
4.2 语法描述 24
4.2.1 外部定义 24
4.2.2 语句 28
4.2.3 表达式 30
4.3 文法转换方法 34
4.4 结果与测试 36
第5章 语义分析设计与实现 37
5.1 目的及实现方式 37
5.1.1 任务要求 37
5.1.2 实现方式 37
5.2 符号表 38
5.2.1 数据结构定义 38
5.2.2 符号表初始化及销毁 39
5.3 x86机器语言 40
5.3.1 数据结构定义 40
5.3.2 相关指令机器码 40
5.4 COFF目标文件 42
5.5 生成文件分析 44
第6章 链接器的实现 46
6.1 目的及其实现方式 46
6.1.1 任务要求 46
6.1.2 实现方式 46
6.2静态链接方式实现实例 47
6.2.1 代码节 47
6.2.2 数据节 48
6.2.3 导入节 49
6.3 成果展示 50
第7章 功能测试 51
7.1 表达式测试 51
7.2 语句测试 52
7.3 结构体测试 54
7.4 函数参数传递测试 55
7.5 出错处理 56
7.5.1 标识符未定义 56
7.5.2 界符错误 56
7.5.3 函数参数匹配错误 57
7.5.4 跳转错误 58
7.5.5 标识符重定义 58
7.5.6 注释错误 58
第8章 总结与展望 60
8.1 总结 60
8.2 展望 60
参考文献 61
致 谢 62
绪论
1.1 研究目的及意义
随着信息化时代的到来,IT行业的热度与日俱增。信息产业就业工资水平大幅领先于其他专业的工资水平,而由于市场的需求很大,该专业的就业难度相较于其他专业的就业难度也小很多,而随着近年来就业形势的日渐严峻,诸多考生在报考大学填报志愿的时候都会考虑到这些因素,从而造成了近年来计算机专业非常火热的情况,而各个高校也随之增设了专业学科来满足市场的需求。
然而,各个高校开设的计算机类专业的教学水平良莠不济,计算机科学与技术专业中编译原理这门课程是作为专业必修的课程赫然列于培养计划中的,然而几年来随着计算机专业的火热,一些学校的培养方向发生了许多的改变,例如为了保证本科生毕业后的工作能力开设了许多面向市场的相关课程,教授相关技术,而忽视本专业的诸如操作系统,编译原理等课程,而学生在此风潮下也逐渐失去了对这些计算机科学的底层知识寻根问底,求知溯源的兴趣。
再反观目前在中国四处开办的IT培训班,打着几个月包教包会签署工作协议的旗号培养面向市场的程序员来和科班出身的计算机专业学生竞争,而仔细浏览其培养方案不难发现这些培训班只针对某一门语言如Java,python对学员进行培训,通过手把手带项目来教授学员相关知识,而对计算机专业的数据结构,算法等知识闭口不谈。
诚然,在如此浮躁的市场下,无论是在本科院校内学习的科班生,抑或是在培训班中半路出家的非科班生,都在努力迎合着市场的“需要”,而对这门学科,这个专业经典的原理及知识置若罔闻。而本文就针对本科阶段所学习的编译原理知识,并结合一门自己相对比较熟悉的语言的子集,设计其对应的文法系统,进而设计其编译系统,自己动手了解高级语言在编译时的原理和更深层次的相关细节,加深自己对这一块知识的理解。
1.2 国内外研究现状
如果研究编译器的历史,可以知道,最开始传统编译器被构造为一系列的翻译程序,每个翻译程序读取输入文件和产生一个输出文件。这最初是必要的,因为某种特定语言的源程序由于其特性,一般不适合记忆。为了避免过度的阅读开销,并编写中间文件,所以希望减少翻译的次数[1]。而到了现代编译器,众所周知的GNU公社最初在1987年3月22日发布了GCC的第一个测试版本,由于当时的开源协议并不完善,GNU公社最终决定其首个项目主攻编译器。尽管GCC最初是一个基于现有的编译器经过编码人员拓展开发使其能够支持C语言的编译器,但在GCC的发展过程中,越来越多的开源工作者的加入令这个项目愈发壮大,直到发展到今天,GCC支持的语言早就不仅限于C语言一种,而GCC也从原本专门为C语言开发的编译器变成了一款能够编译多种语言的复合型编译器。当然,如今的GCC借助于它的特性,具有了交叉编译器的功能,即在一个平台下编译另一个平台的代码[2]。
编译领域在最近的发展有如下几个方面:首先,随着复杂程度较高的程序设计语言的出现,编译器近年来都内嵌与各种流行的IDE已经成为大势所趋,为了提供给编码人员更加舒畅的编码体验,编译器会针对各个IDE所提供的功能做特定的算法优化,对程序中信息的解读能力更加智能化,并能提出更加人性化的修改意见[3]。另一方面,尽管编译器的算法在近年来都在不断地被优化改进,但其核心的构造设计方法依然与前辈们的方法一致,这也使得这一门学科成为本专业的核心课程。
目前国外对编译器的研究方向主要集中在提高编译效率和编译安全两块。早期的编译器在单核处理器上运行,随着处理器的体系结构的变迁,单核处理器早已淡出人们的视野,目前流行的英特尔酷睿处理器都是动辄4核的多核处理器,如何在多核cpu上利用并行结构提高编译器的运算效率挖掘潜能成为了一个研究的方向。另一方面,随着近年来信息安全的重要性与日俱增,一些恶意代码具备能够插入到软件的能力,如何在程序编译的环节中拦截这些恶意代码,保护计算机的安全也成为了一个问题。而在国内,并行编译技术也是目前编译领域研究的重点。
上文提到的GCC项目作为目前被最为广泛使用的编译器,其所实现的一些功能也对如何设计一个编译系统的相关功能有启发性意义。
1.3 论文主要内容与章节安排
本文以“C语言子集的编译系统”为研究对象,按照编译系统执行的顺序流程,以文法系统设计,词法分析,语法分析,语义分析,链接生成,测试为相关主线,对“C语言子集的编译系统”的设计与实现过程进行阐述。本文分8个章节对研究内容及其实现的过程进行介绍,具体内容安排如下。
第1章 绪论部分主要是针对课题的研究目的及其研究意义进行相关的阐述与说明,另一方面,也对目前国内外的研究现状进行分析。
第2章 文法设计部分主要是针对本编译系统拟采用的源程序语言C语言的相关子集的文法进行设计和说明。
第3章 词法分析设计与实现部分主要进行词法分析所使用的相关数据结构以及算法进行分析,并给予实现。
第4章 语法分析设计与实现在第2第3章的基础上对第2章中定义的文法进行改进,使之能够符合语法分析所需要,并解释了语法分析的方法。
第5章 语义分析设计与实现部分结合语义分析中构建的符号表以及目标文件中使用的x86机器语言对语义分析的过程进行解释说明。
第6章 链接器的实现部分分析了PE文件的结构,结合实例着重解释了关于导入节重定位的相关细节。
第7章 功能测试结合实现的功能分别给出测试用例和相应的输出结果。
第8章 总结与展望总结了本系统实现的相应功能以及存在的不足。
第2章 文法设计
本章将对C语言子集编译系统选用的源语言——C语言的子集范围进行界定并给出相应的文法的设计与定义。
2.1 文法相关分类
1956年,乔姆斯基建立了形式语言的相关描述,并将文法分成4类,按照其表示能力的强弱分为0型文法,1型文法,2型文法,3型文法,按照这四种文法的定义存在依次递进的限制强度。而这样就产生了一个另程序语言设计者困扰的矛盾,0型文法的描述能力最强,但其约束能力却非常弱,0型文法作为这4种文法中限制最少的,不仅能够递归也能够枚举。但作为程序语言的设计者来说,需要制定程序语言的相应规范,也就是上文中所说的约束,很显然,0型文法的约束条件无法达到所需要的目标,但是,选择3型文法也并不尽如人意。作为4种文法中约束最强的文法,其对语言的表述能力却是最弱的,3型文法又称作正则文法,其背后也意指其描述能力与正则表达式的描述能力相当。而正则表达式甚至无法表述上下文无关文法。
既然此处提到了上下文无关文法,那便存在上下文相关文法,这两种文法中都提到了“上下文”。“上下文”可以理解为在利用一个文法的产生式进行推导的时候,若是在推导处的前后已经存在推导出的部分结果,那么这些已经确定被接收的推导结果就是上下文。而与此对应的,上下文无关文法即是,只要某个产生式中规定了的产生规则,不管用这个非终结符前后已经推导产生的结果是什么,都能够利用这个产生式继续推导,那么这样的文法称之为上下文无关文法。
而上下文相关文法在利用产生式进行推导时则需要考虑这个非终结符的前后是否有相应的限制,否则不能使用该产生式进行推导。
在此能够利用日常生活中所使用的自然语言构造一个简单的文法来解释这个问题。

图 2.1 一个简单的上下文无关文法
如图2.1所示是一个简单的上下文无关文法,文法中给出了四个产生式,用自然语言则可以理解为是一个句子的主谓宾部分,对应S、V、O三个非终结符,而这三个非终结符又有各自的产生式,利用这四条产生式共能推导出16句句子,如“人吃饭”;“天下雨”;“人吃肉”;“天下雪”;“天下饭”;“天吃肉”;“人下雪”等等,可以发现,这些句子中有一些句子尽管是按照规定的语法推导出来,但是其语义却是荒谬而错误的,但是上下文无关文法却无法检查这种错误。

图2.2 一个简单的上下文相关文法
如图2.2所示是一个对应上文所示的上下文无关文法构造的上下文相关文法,通过对产生式左部的上下文加以约束,这个文法共6条产生式的句子被减少到只有“人吃饭”;“人吃肉”;“天下雨”;“天下雪”四句句子,语义上都是合理而正确的。
C语言是一个上下文相关的语言,其表现在其复杂的语义规定上,普遍存在的误解是将程序语言设计中的错误都认为是语法的错误,这个说法中的语法事实上包括了C语言中复杂的语义约束(例如变量必须先定义后使用),而在讨论编译系统设计的时候应该将两者划分开。
尽管按照上文的分析正则文法的表达能力并不令人满意,但作为大多数程序设计语言的文法定义语言,其在构造难度上相对于其他几类文法要更加容易,因其产生式左部永远只有一个非终结符所以其结构也更加明晰。而由于其表达能力不足所产生的问题则留到第5章语义分析模块中讨论实现。
2.2 文法表示形式
文法的表示形式一般使用BNF(巴克斯范式),EBNF(拓展的巴克斯范式),RE(正则表达式)来表示。综合上面三种经典的被广为使用的文法表示形式,现在规定本文所设计的文法的表示形式如表2.1所示:
表2.1 文法表示形式规定
元符号 | 含义 |
::= | 定义为,推导为 |
| | 或 |
{} | 含0次在内任意多次 |
[] | 含0次和1次 |
() | 括号内看成一项 |
lt;gt; | 非终结符 |
"" | 终结符 |
2.3 字符集
定义:
‘A’ | ‘B’ | ‘C’ | ‘D’ | ‘E’ | ‘F’ | ‘G’ | ‘H’ | ‘I’ | ‘J’ | ‘K’ | ‘L’ | ‘M’ | ‘N’ | ‘O’ | ‘P’ | ‘Q’ | ‘R’ | ‘S’ | ‘T’ | ‘U’ | ‘V’ | ‘W’ | ‘X’ | ‘Y’ | ‘Z’ | ‘a’ | ‘b’ | ‘c’ | ‘d’ | ‘e’ | ‘f’ | ‘g’ | ‘h’ | ‘i’ | ‘j’ | ‘k’ | ‘l’ | ‘m’ | ‘n’ | ‘o’ | ‘p’ | ‘q’ | ‘r’ | ‘s’ | ‘t’ | ‘u’ | ‘v’ | ‘w’ | ‘x’ | ‘y’ | ‘z’
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示:
课题毕业论文、开题报告、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。


