基于IO行为的page cache预取策略研究与设计毕业论文
2020-04-04 10:50:03
摘 要
近几年来,随着计算机和网络的普及发展,人们生活水平的不断提高,安卓手机上允许同时安装多种办公、娱乐应用程序成为一种趋势。这可能产生过多的IO请求,导致前台应用的IO请求得不到及时执行,从而严重影响用户的使用体验,不能够体验到前台运行程序的流畅性。
扩大运行内存、从单核处理器发展为多核处理器等解决方法都是通过提升硬件来解决卡顿的问题,虽有效果但成本较高。本文则总结前人研究工作,从软件方面提出了解决该问题的方案:在现有的Page Cache层简单的利用空间局部性进行预读的基础上,加入利用访问数据之间的逻辑性进行的预取。主要的工作内容如下。
本文首先分析了Linux4.10.1版本内核的预读算法和预读逻辑,并介绍了用C 语言模拟预读的实现和测试过程。
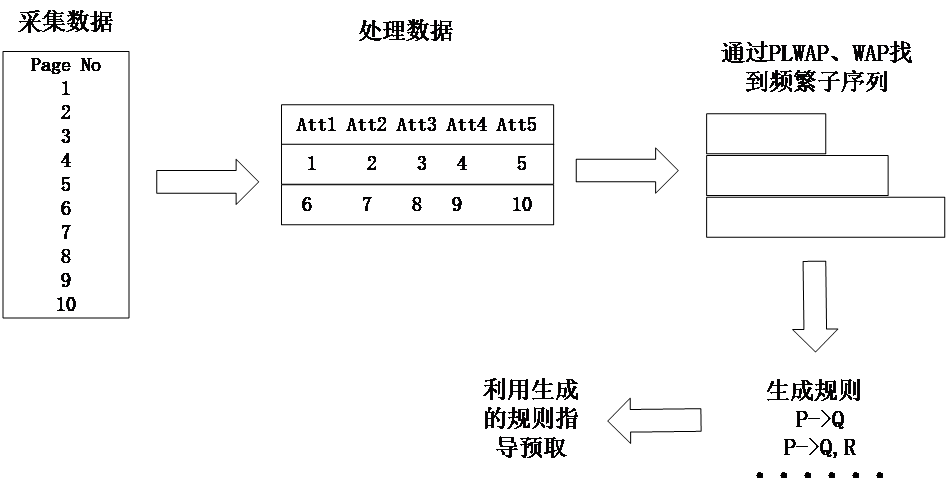
其次,本文分析了四种经典的数据挖掘算法Apriori,FP Tree,WAP和PLWAP。比较选出了最适合本文的两种算法PLWAP和WAP,并使用这两种算法挖掘出频繁序列,进而生成访问规则。然后在模拟的预读之后加入访问规则指导的预取,以提高IO在Page Cache中的命中率,从而优化IO访问开销,高效利用Page Cache空间。
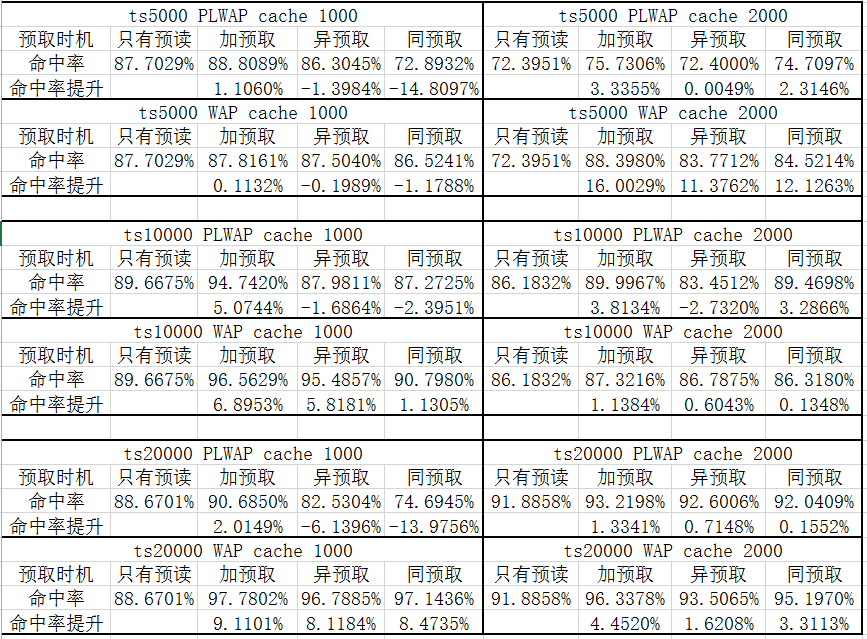
最后,通过实验测试了在使用两种算法生成的访问规则下,仅进行预读、在同步预读后加入预取、在异步预读后加入预取、在同步和异步预读之后均加入预取这四种情况下的缓存命中率。实验结果表明,在同步和异步预读之后均加入预取的命中率提升较多。此外,在PLWAP规则下大约提升1.1060%—5.0744%,在WAP规则下大约提升0.1132%—16.0029%,即WAP规则下命中率的提升普遍比PLWAP规则下的提升多。因此得出结论,使用WAP挖掘得到的规则指导预取,预取时机选择两种预读触发后均进行预取,此方案下IO在Page Cache中的命中率较高。
关键词:Page Cache;预取策略;数据挖掘算法
Abstract
In recent years, with the popularization of computers and networks, people's living standards have been continuously improved. It has become a trend for Android phones to allow simultaneous installation of multiple office and entertainment applications. This may generate too many IO requests, leading to the IO requests of the foreground application not being executed in time, which will seriously affect the user experience, and cannot experience the fluency of the foreground running program.
The solution to expanding memory and developing from single-core processors to multi-core processors is to solve slow transition problems by upgrading hardware, effective but the cost is higher. This paper summarizes the research work of predecessors and proposes a solution to the problem from the software side: In the existing Page Cache layer, based on the simple use of spatial locality for read-ahead, using logical of accessing data to prefetch is added. The main work is as follows.
The paper first analyzes the read-ahead algorithm and read-ahead logic of the Linux 4.10.1 kernel, and introduces the implementation and testing process of using C language to simulate read-ahead.
Then, this paper analyzes four classical data mining algorithms Apriori, FP Tree, WAP and PLWAP. The two algorithms PLWAP and WAP that are most suitable for this paper are selected and used to mine frequent sequences and generate access rules. Then add the prefetch of access rule guidance after the simulated read-ahead to improve the hit ratio of IO in the Page Cache, thereby optimizing the IO access overhead and making efficient use of the Page Cache space.
Finally, the hit rate are tested through experiments that under the two access rules generated by the two algorithms, only read-ahead, prefetching after synchronous read-ahead, prefetching after asynchronous read-ahead, and prefetching after both types read-ahead are used. Experimental results show that the pre-fetch hit rate increases more after both synchronous and asynchronous read-ahead. In addition, under the PLWAP rule, the increase is approximately 1.1060%-5.0744%, and increases approximately 0.1132% to 16.0029% under the WAP rules. In addition, the increase in the hit rate under the WAP rule is generally higher than that under the PLWAP rule. Therefore, it is concluded that the rules obtained by WAP mining are used to guide prefetching. Prefetch timing is prefetch after both read-ahead triggers. Under this scenario, the hit rate of IO in Page Cache is higher.
Key Words:Page Cache; prefetch policy; data mining algorithms
目 录
摘 要 I
Abstract II
第1章 绪论 1
1.1 研究背景及意义 1
1.2 国内外研究现状 2
1.3 本文研究内容 2
1.4 本文结构 3
第2章 模拟Linux预读设计与实现 4
2.1 Linux预读架构 4
2.1.1 小顺序IO的预读架构 4
2.1.2 大顺序IO的预读架构 6
2.1.3 随机IO的预读架构 7
2.2 预读设计与实现 9
2.2.1 重要参数说明 10
2.2.2 Linux整体预读架构设计 11
2.2.3 顺序IO预读的实现 13
2.2.4 异步预读的多线程处理 14
2.2.5 随机IO预读的实现 15
2.3 本章小结 16
第3章 Page Cache预取设计与实现 17
3.1 数据挖掘算法 17
3.1.1 Apriori算法 17
3.1.2 FP Tree算法 18
3.1.3 WAP算法 18
3.1.4 PLWAP算法 20
3.1.5 算法比较 22
3.2 基于数据挖掘算法的Page Cache预取设计与实现 22
3.3 本章小结 24
第4章 实验及数据分析 25
4.1实验结果 25
4.2 实验结果分析 28
4.3 本章小结 28
第5章 总结与展望 29
5.1 全文总结 29
5.2 未来工作展望 29
参考文献 30
致 谢 32
第1章 绪论
1.1 研究背景及意义
磁盘IO性能的发展远没有CPU计算速度和内存性能发展的迅速,这一直是计算机系统的一个主要瓶颈。尽管现如今磁盘的容量增大了很多,但是磁盘访问速度和传输速度却发展的很慢,跟不上CPU计算速度的发展,如图1.1所示。
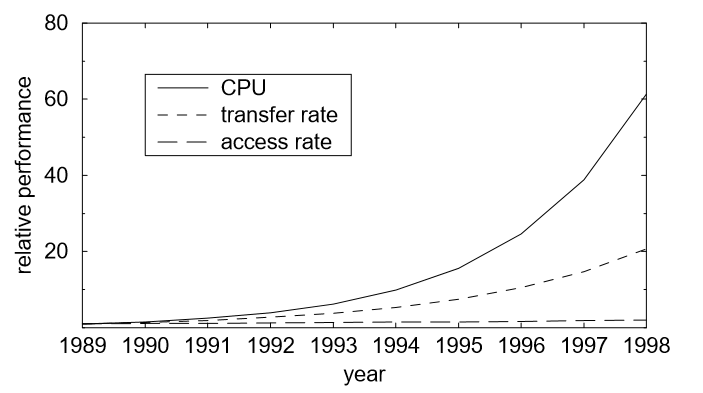
图1.1 CPU速度与磁盘传输率和访问速度的差异
从图1.1可以看出如果在IO中如果需要访问磁盘的话,磁盘传输率和访问速度会严重降低CPU的性能,更何况用户可能会在安卓手机中同时访问多个应用程序,例如直播玩游戏的同时还放着音乐,或者在几个应用程序之间来回切换,这当然会增加许多IO请求。如果每次CPU处理IO请求时都需要从磁盘中读取数据的话会降低CPU处理速度,导致IO请求堆积,进而造成卡顿,严重影响用户的使用体验。
于是有很多在硬件方面改善CPU与磁盘IO性能差异的研究。现如今硬件的性能已经较好,足以使Android系统流畅,但还是能听到周围人说自己的手机卡顿。因此仅升级硬件,清理内存是不够的,本文要做的是解决磁盘IO与CPU之间持续扩大的性能差距。为了弥补在CPU(数据请求者)和磁盘(数据提供者)IO之间的差异,在两者之间设置了缓存以避免太多的IO。因为缓存很昂贵,因此缓存中保存的数据只是整个磁盘数据集中的子集。应用程序请求数据时先在缓存(Page Cache层)中查找,如果请求的数据可以在缓存中命中的话,就节省了访问磁盘的时间。因此,为了获得最大性能,明智的管理缓存是很重要的。读缓存管理的基石是将最近访问的数据保存在缓存中,期望这样的数据将会在不久后再次访问。只有当需求页面访问时才将数据放置在缓存中[1][1]。另外,比较有竞争力的方法是访问缓存中被预测不久后被访问的数据(预取)[1]。
现今,Linux自身的预读就属于这样的优化手段之一。但是这些预读都是根据文件的逻辑地址和响应的预读窗口来决定预读的数据的,很可能预读到不准确的数据。
本文了解到,数据访问之间都是有逻辑关联的[2],被访问的文件之中的模式提供了可以精确预测即将到来的文件访问的信息[3]。为了提高预读的准确度,本文基于此进行了数据挖掘,利用形成的数据访问规则进行预取。
1.2 国内外研究现状
国内外的解决由CPU与磁盘IO持续扩大的性能差距导致的手机使用不流畅的研究状况如下。
1. Android2.3加入了进程管理,开发支持一键清理内存的工具以解决手机使用不流畅的问题,Android4.1-4.4进行了“黄油计划”,同时由于硬件更迭的越来越快,处理器只用了一年多的时间完成了从单核到多核的升级。这是从硬件方面解决手机使用不流畅的问题。
2. 在2002年的2.5内核的开发过程当中,Andrew Morton在将文件预读的根本框架引入了VFS层,以统一支持各个文件系统,然而这个改动不能很好的支持随机读的情形。但是现今应用程序的请求大多是随机请求序列[4]。
3. 大约2004年,Steven Pratt等人对预读算法进行了进一步完善,使得内核可以更好的处理随机读的情况。这是在软件方面改善CPU与磁盘IO性能差距前进的一大步[4]。
4. 2008年,吴峰光重写了内核的文件预读部分,改良了其算法框架和数据结构,实现了对更多读取模式的支持,这些改进被收录到Linux Kernel 2.6.23及其后续版本中[4]。
虽然预读方面已经取得了很好的成就,但是预读相当于根据数据的逻辑存放位置进行的简单的预取,利用的是数据访问的空间局部性,很可能会因为不正确的预读造成缓存污染。
国内外在预取应用方面也有不少研究成果。
1. 使用对应的数据挖掘算法和相应的数据集挖掘出用户访问网页的习惯,然后将预测的网页预取到缓存中以改进互联网访问延迟,减少网页的响应时间[5]-[6]。
2. 在用户移动过程中使用预取改善由于带宽的限制导致的数据访问延迟问题[7]。
3. 使用预取使得汽车数字导航地图加载的更加流畅快速[8]。
1.3 本文研究内容
通过研究国内外现状本文了解到在网页访问等领域可以利用数据挖掘算法挖掘出用户访问网页的习惯,进而提前将预测的网页放入缓存中以减少网页响应时间的工作,并且都取得了不错的成绩。那么同样,可以利用数据挖掘算法挖掘出IO请求之间的联系,形成相应的访问规则,然后根据规则提前将预测的数据放入缓存。原理上来说,只要规则足够准确,就可以提高IO在缓存中的命中率。而本文选取的PLWAP和WAP算法可以根据用户设置的最小支持度挖掘出用户频繁访问的序列。本文对挖掘出来的频繁序列生成了访问规则。
由于修改内核有一定的难度,因此本文计划阅读Linux4.10.1版本内核的预读算法,了解其预读逻辑,并用C 进行模拟实现,多次调试确保模拟的准确性。然后选取数据集,用选取的两种数据挖掘算法生成对应的访问规则。生成规则之后将预取加在模拟的预读程序中,为了方便起见可以将预取的触发放入预读的触发之后,但是需要测试哪一种预读之后触发预取效率更高,或者是触发两种预读后均触发预取。测试两种规则下,在不同的时机下加入预取的命中率以及不加入预取的命中率,并对实现结果进行分析。
1.4 本文结构
本文一共分为五个章节。下面介绍具体的章节安排。
第一章是绪论部分,主要介绍本文的研究背景及意义,国内外研究现状,本文主要研究内容和结构。
第二章介绍Linux预读本身的预读架构,通过仔细研究内核源码确定Linux预读处理顺序IO和随机IO的逻辑,对其进行实现,测试程序的正确性之后加入预取部分的处理。
第三章介绍Page Cache预取方案的设计与实现,通过比较本文了解到的现有的四种数据挖掘算法Apriori,FP Tree,WAP和PLWAP各自的优缺点,以及这些算法对本题的适用性,确定了使用基于WAP和PLWAP算法挖掘出来的频繁序列形成访问规则进行预取。将预取的部分集成到第二章的预读中进行测试。
第四章进行实验测试使用不同的访问规则,在Page Cache的预读加入预取后对命中率的影响,并对结果进行分析得出对命中率提升最高的访问规则和预取的触发时机。
第五章对全文进行总结,指出本文研究的不足之处,展望未来的工作。
第2章 模拟Linux预读设计与实现
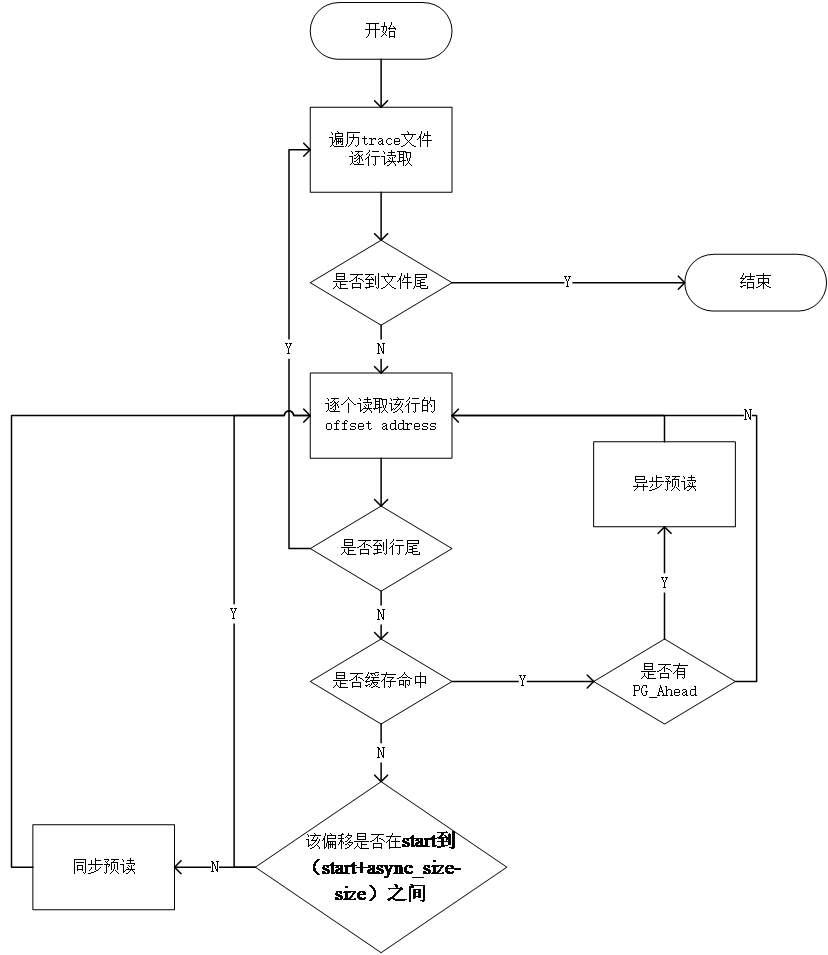
由于本文应该是将预取加入到Linux内核中进行测试,且修改内核有一定的难度,因此本文决定模拟Linux内核原本的预读,测试无逻辑错误后加入Page Cache预取的部分。
2.1 Linux预读架构
Linux系统中的预读有两种,分别是异步预读和同步预读。触发预读的时候内核会为每次预读计算一个预读窗口:RA(start,size,async_size),其中start代表此次读取在文件中的起始位置,size代表此次一共读取的数据大小,async_size代表此次需要预读的数据大小。
2.1.1 小顺序IO的预读架构
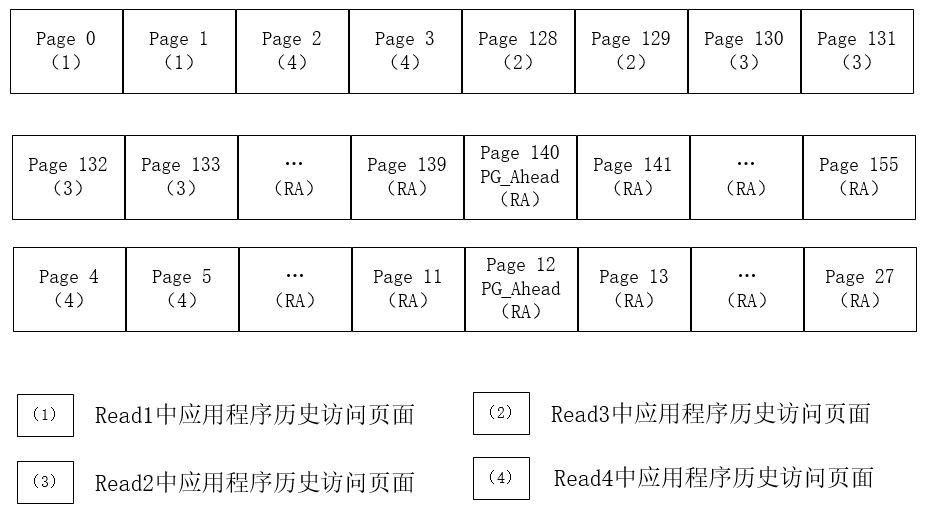
用例子对Linux小顺序IO的预读架构进行说明:假设对一个文件进行三次顺序读,第一次读(read1)读取4K的数据,这相当于page cache中的一个page;第二次读(read2)读取8K的数据;第三次读(read3)读取16K的数据[9]。应用程序三次请求读取文件的过程如下所述。
- Read1——从文件开始读取一个page。
在内核进行读流程处理的时候,会先查找该偏移量对应的页面是否在Page Cache中命中。显而易见,首次读的话会导致缓存未命中,进而触发一次同步预读。且由于是缓存未命中,应用程序需要等待内核将对应的页面读入缓存之后才能返回。
经过相应的同步预读操作,计算形成的预读窗口为(0,4,3)。即此次内核一共读取4个page,从文件的start=0处开始读取,其中page0是应用程序请求的内容,page1-page3是内核预读的内容。然后根据获得的预读窗口调用ra_submit提交本次读请求。

图2.1 Read1形成的读窗口
在page cache中形成的读窗口如图2.1所示,其中PG_Ahead是触发异步预读的标志,内核预读进来的第一个页面会被打上这个标记。预读结束后,应用程序请求的页面page0已被放入缓存,直接从该page中拷贝出内容返回即可。
- Read2——接着Read1继续从文件中读取两个page。
接下来应用程序要访问page1和page2这两个页面。由于第一次的预读,导致这两个页面已经存在于缓存中,可供应用程序直接拷贝然后返回,而不需要等待从磁盘中读取数据。但是注意,page1被标记为了PG_Ahead,这个标记会触发一次异步预读。此时应用程序得到了自己请求的数据,因此不会受到异步预读的影响,只要后台慢慢从磁盘中读数据到缓存中即可。
本次预读的窗口(4,8,8)可以根据相应的异步预读操作和前一次的预读窗口计算得出。如图2.2所示,此次读操作一共读取8个page,从文件的start=4处开始读取,这8个page都是内核预读的内容,同样,预读进来的第一个page会被标记为PG_Ahead。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示:

课题毕业论文、开题报告、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。


