基于caffe深度学习框架的目标检测研究毕业论文
2020-04-04 10:53:07
摘 要
目标检测是计算机视觉领域一个重要且热门的研究课题,拥有着非常广泛的应用场景,是其他计算机视觉应用的基础。因此如何高效准确的利用计算机从图像或者视频中定位和识别出待检测的实体是一项具有重用意义的工作。
本文从传统目标检测方法出发,以人脸检测为例,讨论了传统基于Haar特征和Adaboost分类器的人脸检测算法,并利用OpenCV库实现了对图片和摄像头中视频流的人脸检测程序。在此基础上延伸到基于深度学习的目标检测方法,本文对R-CNN方法做了详细的介绍,并介绍了在此基础上改进的Fast R-CNN和Faster R-CNN,并对三种方法的进行对比给出各自的优缺点。利用Caffe深度学习框架,训练了识别人手写数字图片的网络模型,并能准确识别出手写数字图片中的数字。同时,根据Faster R-CNN提出这段论文,本文也以Caffe框架为基础实现了该方法,能准确高效地标出图片中的实体,并识别其所属类别。在实验结果大多数以命令行给出的情况下,我利用Caffe框架和flask框架实现了一个给图像分类的Web Demo,页面界面简洁美观,识别效果准确且高效。
本文在于对目标检测领域所用的一些方法进行了总结,并且都予以了实现,这让我在之后对该领域的研究打下了坚实的基础。
关键词:目标检测;图像处理;深度学习;R-CNN;Caffe
Abstract
Object detection is an important and popular research topic in the field of computer vision. It has a very wide range of application scenarios and is the basis of other computer vision applications. Therefore, how to efficiently and accurately use a computer to locate and identify an entity to be detected from an image or a video is a task of reusable significance.
This paper starts with the traditional object detection method and uses face detection as an example. It discusses traditional face detection algorithms based on Haar features and Adaboost classifiers, and uses OpenCV library to implement face detection program for video streams and pictures. Based on this, it extends to the target detection method based on deep learning. This paper introduces the R-CNN method in detail and introduces the improved Fast R-CNN and Faster R-CNN based on this method. The comparisons give their respective advantages and disadvantages. Using Caffe's deep learning framework, a network model for identifying hand-written digital pictures was trained, and the numbers in hand-written digital pictures can be accurately identified. At the same time, according to the article proposed by Faster R-CNN, this paper also implements the method based on the Caffe framework, which can accurately and efficiently mark the entities in the image and identify its category. In the case that most experimental results are given in the command line, I implemented a Web Demo for image classification using the Caffe framework and the flask framework. The interface of the page is simple and beautiful, and the recognition effect is accurate and efficient.
This article is a summary of some of the methods used in the field of object detection, and both have been implemented, which allows me to lay a solid foundation for future research in this field.
Key Words: Object Detection;Image Processing;Deep Learning;R-CNN;Caffe
目 录
第1章 绪论 1
1.1. 研究背景 1
1.2. 国内外研究现状 2
1.3. 研究的目的和意义 3
1.4. 课题的研究内容 3
第2章 传统目标检测方法介绍 4
2.1. 传统的目标检测算法 4
2.2. Viola-Jones人脸检测算法 4
2.2.1. 特征提取 4
2.2.2. AdaBoost分类 5
第3章 基于深度学习的目标检测方法 7
3.1. 用R-CNN进行目标检测 7
3.2. Fast R-CNN 8
3.3. Faster R-CNN 9
3.4. 深度学习目标检测方法总结 10
第4章 目标检测方法的实现 12
4.1. 传统目标检测方法 12
4.2. 基于深度学习的目标检测方法 13
4.2.1. Caffe深度学习框架 13
4.2.2. 利用Caffe框架做Faster R-CNN 16
4.2.3. 利用caffe搭建图像识别Web应用 17
4.3. 传统方法和深度学习方法对比 18
第5章 结论 20
5.1. 总结 20
5.2. 展望 20
参考文献 21
致谢 22
附录 22
绪论
本章主要从研究背景、研究目的、研究意义、国内外研究现状、课题研究内容及预期目标几个方面进行相关的阐述。
研究背景
计算机视觉是指利用计算机等机器代替人眼对图像或视频中的目标进行识别、跟踪和测量的过程,旨在试图建立能够从图像或其他数据中获取目标“信息”的人工智能系统。计算机视觉在于指导计算机像人类一样认识世界,认识物体。在计算机视觉中目标检测、跟踪、识别是最基本的任务,尤其又以检测最为重要和基础。对图像中物体的识别和检测是计算机视觉中的前置任务,也是其他应用的基础,例如在智慧城市、机器人、无人驾驶等多种应用场景。因此图像的目标检测有着非常重大的意义,如果能够高效的利用计算机对图像进行目标检测、识别,这将是人工智能时代到来的基础,就像对于人而言,这是人类的眼睛,只有先认识世界才能理解之后物体间复杂的关系。
目标检测是计算机视觉领域中一个基础性的研究课题,需要从图像中定位目标,并准确判断每个目标的具体类别,同时给出每个目标的边界框。但由于拍摄图像时的视角、亮度、遮挡等多种因素可能引起目标发生形变,因此在这种复杂的背景环境因素下的目标检测成为一个具有挑战性的任务。
传统目标检测方法主要分为窗口滑动、特征提取、特征分类等几个步骤。这类方法是在预处理之后的图像上,滑动一个固定大小的窗口,利用特定的算法对候选区进行特征提取,再使用分类算法对候选区进行分类,判定候选区的图像是否包含了目标及其类别。但是,这类传统的目标检测方法使用的特征,目标检测的准确度不能令人满意,而且设计的特征具有很强的针对性,难以将一种特征应用在多种目标检测上。
从2012年起,Hinton所带领的深度学习小组在ImageNet比赛中,其准确率要远远高于其他使用传统方法做目标检测的参赛团队,引起了图像识别领域的轰动,也正是由此深度学习的热潮正式开启。随着深度学习的发展,利用深度神经网络从大量数据中自动地学习特征,这种方法学习的特征更加丰富,表达能力更强。研究者发现在用卷积神经网络对图像进行检测和提取特征时,往往能获得较好的特征,且整个过程自动完成。在检测时,因为神经网络将特征的提取、选择和检测融合到一个模型中,通过训练增强了特征的区分性,从而得到了较好的结果。因此,基于卷积神经网络(CNN)的目标检测得到了广泛的关注,成为当前计算机视觉领域的研究热点之一。
国内外研究现状
目标检测与识别是计算机视觉领域中一个基础性的研究课题,一直是计算机视觉领域的研究热点。针对特定类别的目标检测,例如人脸等,检测技术已经较为成熟。Viola和Jones于2004年提出的Viola-Jones检测器就是一种人脸检测框架,它极大的提高了人脸检测的速度和准确率。其三个核心步骤:Haar-like特征、Adaboost分类器和Cascade级联分类器。Dalal在2005年提出的方向梯度直方图(HOG)特征结合SVM分类器的方法在行人图像检测中效果较好。随后不断有研究人员对这类目标检测的方法进行改进提高。2008年,Felzenszwalb提出了DPM目标检测算法,是HOG的扩展,是一个非常成功的目标检测算法,连续获得VOC(Visual Object Class)2007年至2009年的检测冠军。目前已成为众多分类器、人体姿态和行为分类的重要部分。
在人们使用深度学习方法于图像目标检测上前,需要借助这类算法以提取较好区分的特征,再结合SVM等分类器对特征进行分类和识别。然而这类算法无论是在时间还是在准确率上都存在着瓶颈,在ImageNet数据集上的错误率在26%以上,且常年难以取得突破。在2006年,机器学习领域泰斗、神经网络之父Hinton提出了深层网络训练中梯度消失问题的解决方案,从此开启了深度学习的浪潮。2012年,Hinton团队首次参加ImageNet图像识别比赛,通过构建的CNN网络AlexNet一举多的冠军,且比第二名(SVM方法)的效果要好很多。也正是由于这个比赛,卷积神经网络吸引了众多研究者的注意。此时CNN已经能比较好的识别出图像中的物体,对图像进行分类,而目标检测的的最终目标识别出图像中主要实体的位置再区分其类别。于是Ross Girshick提出了R-CNN(Regions CNNs),是将CNN方法应用到目标检测问题上的一个里程碑。R-CNN通过Selective Search的方法生成Region Proposal候选区域,再借助CNN良好的特征提取和分类性能,最终使用SVM分类器对提取到的特征进行分类。 R-CNN取得了较好的检测准确率,但是效率却比较低,在2015年R-CNN的作者Ross Girshick提出了Fast R-CNN,只需要一次原始图像的CNN前向计算,并将CNN、分类和边界线性回归的训练融合到一个单独的网络中。Fast R-CNN仍存在这生成用于测试的潜在bouding box集合的方法速度非常慢,Ross Girshick团队再次提出了Faster R-CNN的方法,使得region proposal非常高效。至此,以上方法已经可以利用CNN特征快速定位图像中不同的目标的bounding boxes,那么如何提取像素级的目标实例而不仅仅是给定bounding boxes。在2017年Kaiming He和他的团队提出了Mask R-CNN架构,能够 精确到像素级别对图像分割并对图像中的物体进行分类。
经过众多研究人员的日以继夜的研究,提出了种种优秀的目标检测的方法,2016年ILSVRC的图像识别错误率已经达到约2.9%,甚至低于人类肉眼识别的错误率(5.1%),可见目标检测的研究在近些年取得了非常重大的突破。未来的计算机视觉的重点在于图像内容的理解,这对于机器视觉领域的研究又是一重要的难题。
研究的目的和意义
本次研究的目的在于,熟悉深度神经网络结构,总结图像目标检测方法的发展过程,总结多种目标检测算法的具体方法,对比目前常用的多种目标检测方法的效果。本文是对目标检测领域方法的总结和综述。同时利用openCV库和Caffe框架,分别实现传统目标检测方法和基于深度学习方法的Faster R-CNN。
课题的研究内容
课题主要研究内容如下:
- 讨论传统目标检测方法,以人脸检测为例,深入分析基于Haar特征和Adaboost分类器的人脸检测Viola-Jones算法。
- 理解基于深度学习的目标检测方法,讨论R-CNN,Fast R-CNN,Faster R-CNN这一系列基于深度学习的目标检测方法,分别比较其思想,以及改进的地方和优缺点。
- 利用OpenCV库实现了对图像和实时电脑摄像头视频流的目标检测方法。
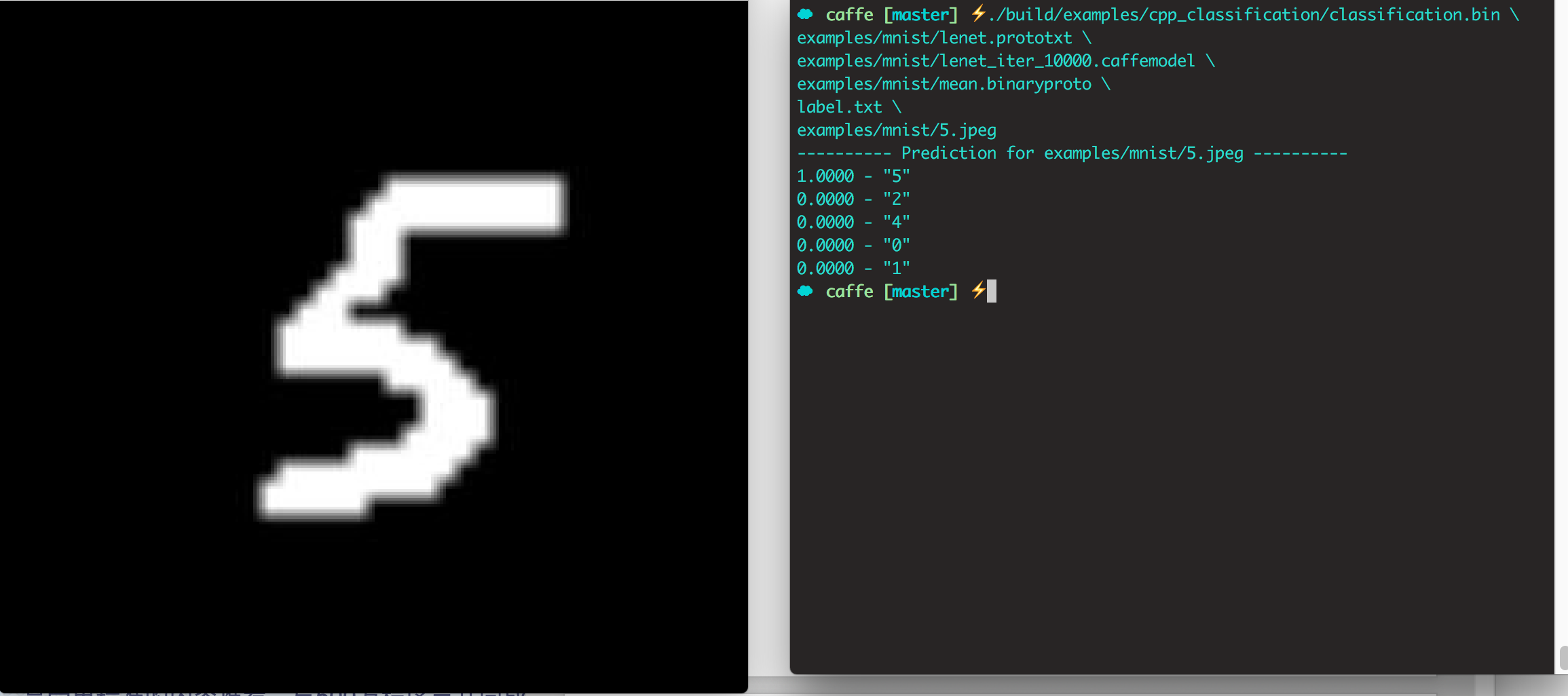
- 熟悉使用Caffe库,利用MNIST数据集训练识别人手写数字图片的模型,给定一张手写数字的图片,模型能准确的识别出图片中的数字。
- 根据论文,基于Caffe框架实现Faster R-CNN方法,能准确的从图片中识别出实体,并使用方框标注出来。
- 基于Caffe框架和flask框架,实现一个能对图片分类的Web Demo,可以选择上传图片或者粘贴URL来对图片进行分类。
传统目标检测方法介绍
本章首先以人脸识别为例对传统目标检测方法进行介绍,并使用openCV库提供的接口实现人脸和眼睛等特定物体的识别程序。
传统的目标检测算法
在计算机视觉领域,物体检测是一个非常热门的研究方向。物体检测对于人眼来说并不困难,人类能根据图像中不同的颜色、纹理、边缘模块很容易定位出目标物体,但对于计算机而言,图像存储的形式是RGB像素矩阵,很难从像素矩阵中直接得到物体的具体类别并定位出其位置,再加上物体的姿态、光照和复杂的背景灯影响因素,这些都使得物体检测变得十分困难。
传统的检测算法里面通常包括三个部分,检测窗口的选择、特征的设计、分类器的设计。在2001年,Paul viola和Michael Jones共同提出了Viola-Jones人脸检测算法,基于Haar特征和Adaboost分类器的检测方法在当时的学术界引发了非常大的轰动,检测的性能达到了当时较高的水平。直至2012年应用深度学习于图像目标检测前,目标检测领域的研究工作大多都是在对这三个部分进行优化。下面我将以Viola-Jones人脸检测算法为例子,介绍传统目标检测方法。
Viola-Jones人脸检测算法
在计算机视觉领域,人脸检测是目标检测中一个非常热门的课题,也受到了大量的关注。在人脸检测中,这是非常经典的算法,提高了当时人脸检测的速度和准确率。下面就将较为详细的介绍。
特征提取
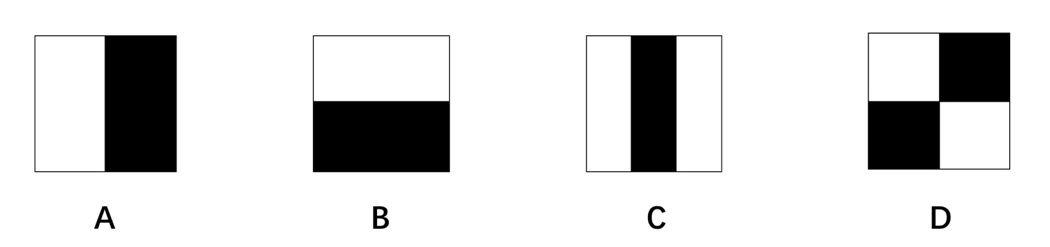 对于人脸的图像来说,会有一些共同的特征,例如眼睛区域会较其他区域相对较暗,鼻子区域会比周围的脸颊要亮一些,人正脸图像,五官的相对位置是有规律可以发觉的。因此这个算法根据这些共有的特征设计了Haar特征,分为边缘特征、线性特征、中心特征和对角线特征,组合成特征模板,如图2.1所示的这四种特征。特征模板内有白色和黑色两种矩形,模板的特征值为白色矩形像素和减去黑色矩形的像素和。这类特征值能够反映图像的灰度变化的情况。这种矩形特征能描述一些人脸部的部分特征。通过改变特征模板的大小和位置,会在图像子窗口中穷举出大量的特征。大量的特征值重复计算会消耗大量的时间,利用积分图来可以快速计算这些大量的特征,只遍历一次图像就可以求出图像中所有区域像素。对于图像中任何一点,该点的积分图像值等于位于该点左上角的所有像素之和。
对于人脸的图像来说,会有一些共同的特征,例如眼睛区域会较其他区域相对较暗,鼻子区域会比周围的脸颊要亮一些,人正脸图像,五官的相对位置是有规律可以发觉的。因此这个算法根据这些共有的特征设计了Haar特征,分为边缘特征、线性特征、中心特征和对角线特征,组合成特征模板,如图2.1所示的这四种特征。特征模板内有白色和黑色两种矩形,模板的特征值为白色矩形像素和减去黑色矩形的像素和。这类特征值能够反映图像的灰度变化的情况。这种矩形特征能描述一些人脸部的部分特征。通过改变特征模板的大小和位置,会在图像子窗口中穷举出大量的特征。大量的特征值重复计算会消耗大量的时间,利用积分图来可以快速计算这些大量的特征,只遍历一次图像就可以求出图像中所有区域像素。对于图像中任何一点,该点的积分图像值等于位于该点左上角的所有像素之和。
图2.1 四种人脸的Haar特征表示图
积分图像的思想是对一张图像计算所有点到左上角的矩形区域的像素和,并保存于一个数组中。当需要计算某个矩形区域的像素和时,可以利用索引直接读得像素和,大大加快了计算矩形区域中的像素和的效率。
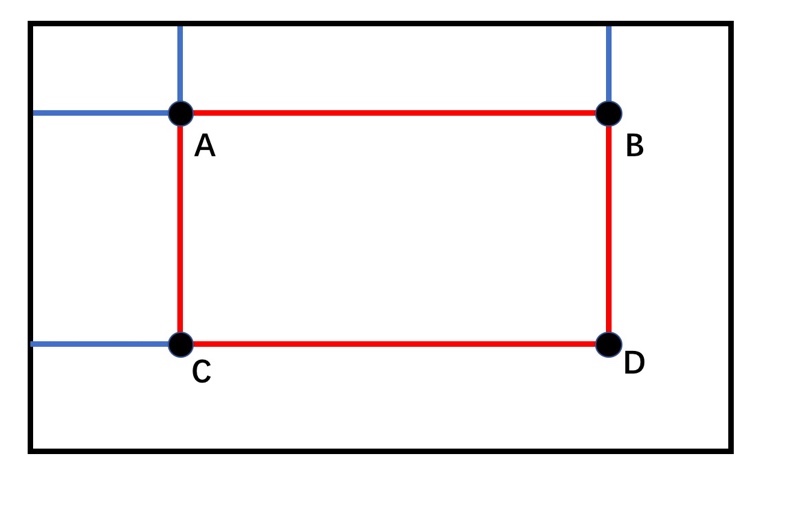 为了计算矩形ABCD的像素和,利用积分图像可以表示如下:
为了计算矩形ABCD的像素和,利用积分图像可以表示如下:
图2.2 图片矩形区域示意图
可以根据积分图像快速的计算举行特征,但是矩形的位置和大小是随机变化可以产生远远超出图像本身维度数量的矩形特征,这些特征不可能全都用,因此要对特征做选择。
AdaBoost分类
对于积分图像的产生的大量的矩形特征,我们不可能将所有的特征都用上,因此Viola-Jones算法采用AdaBoost分类器来挑选特征。Adaboost算法是一种迭代的方法,其思想是针对不同的训练集训练同一个弱分类器,再讲训练得到的弱分类器组合成一个最终的强分类器。如公式2.3所示,就是一个“强”分类器,而就是“弱”分类器。而其实就是一个简单的阈值函数,如公式2.4所示。
是图像的每一个特征,是阈值,和系数都由训练的时候确定。训练算法过程如下所示:
给定一组N个训练样本,如果是人脸图像,则,否则。 |
|
|
Viola-Jones算法中有设计了层级分类器来加快矩形区域特征的分类,即用多层分类器来过滤大部分特征,只有前一层的矩形特征是有可能检测目标的特征才会进入下一层的分类器中。
基于深度学习的目标检测方法
用R-CNN进行目标检测
R-CNN(Regions with CNN features)是Ross Girshick团队在2013年提出的算法,其主要思想分为三个部分,第一部分是产生候选区域,第二个部分是对每个候选区域使用CNN提取长度固定的特征,第三个部分是使用一组特定类别的SVM进行分类。
首先,对于一张输入图像,使用选择性搜索(Selective Search)提取大约2000个区域。选择性搜索算法是使用一些特定的图像分割算法对图像进行分割,再根据图像一些固有的特征如颜色、尺寸、纹理和空间交叠等对分割得到的结果进行归并,再提出所有可能的候选区域。选择性搜索的算法流程如下。
|
|
|
获得候选区域之后,使用CNN对得到的候选区域图像进行特征提取。CNN(Convolutional Neural Networks)卷积神经网络是人工神经网络的一种,由大量神经元相互连接而成,每个神经元接受线性组合的输入,每个神经元加上非线性的激活函数,进行非线性变换后输出。卷积神经网络的层级网络一般包含了数据输入层、卷积计算层、激励层、池化层、全连接层。R-CNN方法使用的网络结构是AlexNet网络,下面将以该网络为例,详细介绍卷积神经网络的网络结构。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示:

课题毕业论文、开题报告、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。


