查询反馈方法研究毕业论文
2020-04-04 10:53:50
摘 要
伴随着互联网的高速发展,人们接触的信息容量呈爆炸式高速增长,从信息源中筛选自己需要的信息也变得日益困难。在信息检索的时候,通常由用户在文本框中输入关键词,然后由搜索引擎根据倒排索引,从文档库中检索出相关文档并返回给用户。由于用户通常以数个简单短语的形式作为搜索关键词,往往不能完整准确的表达出用户的检索意图。
查询是用户搜索时表达其信息需求的基本方式,系统提示的相关词则是用户改善查询的有效工具,搜索引擎反馈的信息是用户能得到的最终信息。而这一过程,我们称之为查询和反馈,查询和反馈依靠的则是查询反馈模型,也叫做检索模型。
论文主要研究了几个传统的查询反馈模型,包括布尔模型、向量空间模型、概率模型和语言模型,学习了他们的数学原理,给出了他们的逻辑公式,总结了他们各自的特点,性能和不足。最后重点学习了基于语言模型的正负反馈模型,这个模型不同于以往只考虑相关反馈或者伪相关反馈的语言模型,它综合了正反馈和负反馈,正反馈用来扩大检索,负反馈用来减少不相关的反馈信息。
结果表明正负反馈语言模型的检索性能明显优于以往的查询反馈模型,是可以应用于现代网络检索的优秀的检索模型。
关键词:查询反馈;检索模型;相关反馈;伪相关反馈;正反馈;负反馈
Abstract
With the rapid development of the Internet, the information capacity of people is increasing rapidly. It is becoming more and more difficult to screen information from information sources. In information retrieval, the user usually inputs the key words in the text box, and then the search engine retrieves the relevant documents from the document library and returns to the user according to the inverted index. Because users usually use several simple phrases as search keywords, they often fail to express users' retrieval intention completely and accurately.
Query is the basic way to express the information needs of the user, and the Related words prompted by the system are the effective tools for the user to improve the query. The information that the search engine feedback is the final information that the user can get. This process is called query and feedback, and query and feedback rely on query feedback model, also called retrieval model.
This paper mainly studies several traditional query feedback models, including Boolean model, vector space model, probability model and language model, learn their mathematical principles, give their logical formulas, and summarize their respective characteristics, performance and shortcomings. Finally, the positive and negative feedback model based on the language model is studied. This model is different from the previous language model only considering the correlation feedback or pseudo correlation feedback. It combines positive feedback and negative feedback, positive feedback is used to enlarge the retrieval, and negative feedback is used to reduce the unrelated feedback information.
The results show that the retrieval performance of the positive and negative feedback language model is better than the previous query feedback model, and it is an excellent retrieval model which can be applied to modern network retrieval.
Key Words:Query feedback; retrieval model; relevance feedback; pseudo relevance feedback; positive feedback; negative feedback
目录
第1章:绪论 2
1.1概述 2
1.2国内外研究现状 2
1.3本文研究内容 4
第2章:常用检索模型分析 5
2.1布尔模型 5
2.2向量空间模型 6
2.3概率检索模型 7
2.4语言模型 10
第3章:正负反馈语言模型 12
3.1反馈的特性 12
3.2模型框架 13
3.3模型特点 14
第4章:实验结果与分析 15
4.1检索模型评价指标 15
4.2实验内容 16
4.3结果与分析 17
第5章:结论与展望 19
5.1结论 19
5.2未来展望 19
参考文献 20
致谢 21
第1章 绪论
查询反馈模型从它诞生到现在经历了基于集合论的阶段、基于线性代数的阶段、基于统计和概率的阶段。本文将对目前国内外流行的查询反馈模型进行分析,并找出一个可以最有效的反馈给用户他们想要的信息的模型。
1.1概述
用户搜索时,表达信息需求的过程叫查询。搜索引擎提交搜索结果的过程就叫做反馈。
搜索引擎的核心就是对搜索结果进行排序,而对搜索结果进行排序时有两个最重要的因素,他们分别是网页的内容和用户查询的相关性以及网页链接情况。网页链接情况是网页自身的,搜索引擎无法左右的因素,搜索引擎所能做的就是提高搜索结果的相关性。计算内容相关度的理论基础及核心组件就是查询反馈模型。
1.2国内外研究现状
信息的获取一直以来都是人们很重视的问题,而随着计算机网络的高速发展和普及,互联网已经成为人们获取信息的最主要的渠道。近年来,改进现有的查询反馈方法以满足用户日益增长的信息需求一直是国内外学者研究探讨的热点问题。
国外学者对查询反馈技术的研究一直很热衷,近年来的优秀研究成果更是如雨后春笋,层出不穷。
A Smith发表于《Electronic Library》的一篇名为《Information Retrieval: Implementing and Evaluating Search Engines》[1]的文章表明了信息检索技术是现代搜索引擎的基础,介绍了现代搜索技术的核心主题,包括算法、数据结构、索引、检索和评价。
S Roehling的《Cross-Language Information Retrieval》[2]介绍了跨语言信息检索(CLIR)的原理和流程,提出了跨语言技术的一些难点,并提供了解决思路。
约翰霍普金斯大学的Tim Finin1, James Mayfield等人发表了一篇名为《Information Retrieval and the Semantic Web》[3]的论文,他们使用基于Web的索引和检索技术,扩展信息检索系统的关键问题,处理语义Web语言中的注释,并且介绍了三个已经实施的原型系统,分别是OWLIR系统、Swangler系统、Swoogle系统。
N Dong、C Hauff等人的《WikiTranslate: Query Translation for Cross-Lingual Information Retrieval Using Only Wikipedia》[4]介绍了一个只使用维基百科获得跨语言信息检索查询翻译的系统,并命名为WiKiStLaSLAT,在这个系统中,查询被映射到维基百科概念,并且使用目标语言中的这些概念的相应翻译来创建最终查询。
K Macpherson的《An information processing model of undergraduate electronic database information retrieval》[5]描述了一个应用于终端设备电子数据库信息检索的信息处理模型,并通过实验证实了系统的可行性。
另一方面,国内的学者也紧跟脚步,对查询反馈的研究越来越深入,撰写了许多优秀的研究报告,其中佼佼者的研究成果甚至领先于国外的专家。
何燕学者的《基于用户反馈的查询扩展研究》[6]学习了传统的查询扩展技术,找出了他们的不足之处,引入了WordNet的概念,并与概念相似度的方法进行了结合,搭建了一个可供用户选择的查询扩展集合。
哈尔滨工业大学的陈建荣学者在前辈的基础上,发表了《基于用户反馈的智能查询扩展技术研究》[7],文中通过实验分析了大量查询扩展算法,并对他们进行了可融合分析、加权组合设计、参数调优等工作,并根据工作成果提出了基于文档重排序的混合查询扩展算法,该算法有效的提高了检索的准确率,而且适用于目前已有的大多数搜索引擎。
大连理工大学的马云龙学者发表了《查询理解与正负双向相关反馈技术研究》[8],为了解决权重的预测问题,他将其替换为了序列标注问题。为了解决查询意图分类的问题,以往的查询意图分类变化不够灵活,严重依赖人工标注,他将其替换为了一个经典分类问题和一个序列分类问题。
内蒙古大学的王俊义学者发表了一篇名为《正负相关反馈与查询扩展技术的研究》[9]的研究论文,他全面研究学习了正负反馈语言模型,介绍了这个模型的框架,提出了正负反馈的自动识别技术,并对模型参数进行了动态调整,还对多主体反馈等方面展开了细致的研究工作,成效显著。研究表明,正负反馈模型可以改进检索性能,并且在个性化检索中,该模型也完全适用。
查正军、郑晓菊合著的《多媒体信息检索中的查询与反馈技术》[10]针对多媒体信息检索的检索性能改进所面临的问题,即“语义鸿沟”和“意图空隙”的限制,进行了分析和讨论,并提出了一系列可以帮助系统对U进行查询的技术和反馈技术。准确理解用户意图。
厦门大学潘超《微博检索技术研究与实现》[11]从探索和创造的角度出发,在伪相关反馈的角度进行了扩展,提出了动态扩展方案,还在同义词的扩展查询角度提出了基于词向量方面的近义词查找方案。并且他还对检索模型进行了优化,采用了随机性差异框架。同时,他还对检索结果进行了再一次的优化,设计了集成学习排序算法,使相关性高但是排列的顺序比较靠后的文档能得到较高的序位,大大提高了用户的体验效果。
巩皓、杜军平等人的《基于本体和局部查询反馈的微博查询扩展算法》[12]又提出了一种全新的,针对微博检索的查询扩展算法,该算法的基础是本体和局部检索,首先要搭建好一个数据库,然后对原先的查询词进行填充,再对备用的填充词集进行筛选,最后经过迭代操作和二次检索得到反馈结果。
内蒙古大学的孙天培学者发表了《跨语言信息检索的查询消歧及查询扩展技术研究》[13],文中他做了大量的统计工作,提出了一个汉语和蒙古语的概率词典,用来对蒙汉语之间的查询项进行了消歧。同时他还对现有的查询反馈模型进行了分析,创造了一种改进的可以对检索的文档进行归类加权的权重计算算法,计算得分。
王元卓、刘大伟等人的《基于开放网络知识的信息检索与数据挖掘》[14]详细的列出了目前网络内容数据库的内容检索和模型应用的不足。
王曰芬、郑小昌等人的《面向网页信息筛选的可信度评估研究》[15]提出了一种可以评估网页内容真实度的评估方法,并创建了真实度评估指标体系。为了计算出指标的权重,采用多重分析法对网页内容进行筛选。这个方法可以估算出网页内容是否可靠。
1.3本文研究内容
本文从布尔模型、向量空间模型、概率模型和语言模型四个不同时间段的经典查询反馈模型入手,对它们进行了详细的研究,并介绍了它们各自的原理和特点。以此作为研究的展开工作,引出了对基于语言模型的正负反馈模型的研究学习。
基于语言模型的正负反馈模型是王俊义教授提出的一个非常完善的查询反馈模型,其检索性能较之传统的语言模型有很大的提高。通过深入的学习研究,本文对该模型的原理,特点,框架和一些参数都做了比较详细的介绍。
第2章 常用检索模型分析
2.1布尔模型
布尔模型基于集合论和布尔代数理论,简单而且实用,是最早的信息检索模型,目前仍然被各领域广泛应用。在布尔模型中,每一个搜索词都被替换为一个布尔表达式,通过替换后的布尔表达式,可以反应出用户想要得到的搜索结果应该具备的特点。
布尔模型的原理基于下列这些假设:
- 对于任何一篇文档,我们都可以用关键词的集合来表示。
- 检索可以用布尔表达式表示,即使用“与、或、非”的逻辑运算符来连接关键字。
- 这篇文章与查询词是否匹配的可以通过布尔表达式来判断。关键词满足布尔表达式,则匹配;关键词不满足布尔表达式,则不匹配。
例如,用户的查询是“A和(B或C)”。如果文档中有“A”,同时在“B”或“C”中有一个或两个,那么这篇文章是相关的,是满足用户检索要求的文章,否则这篇文章就是不相关的文章。
布尔模型的优点:
- 布尔模型很简单,非常容易理解,也很容易实现,并且有布尔代数理论和集合论的理论支持。
- 通过把布尔表达式复杂化,用户可以达到控制查询结果的目的。
- 用户经过一定的训练,可以自己书写布尔表达式。
布尔模型的缺点:
- 布尔模型有一个非常严重的缺点,他是严格二元相关的,意思就是说布尔模型中的文档,要么就是相关,要么就是完全不相关,不支持部分相关这种情况,这样就会导致太多或者太少的搜索结果被返回。
- 布尔模型很难对返回的结果进行排序。
- 布尔模型不会考虑关键词的权重,所有的关键词都会以相同的权重进行查询匹配。
2.2向量空间模型
向量空间模型是由Salton等人在上个世纪70年代开发出来的,之后便在非常有名的SMART文本检索系统中被成功应用。该模型用线性空间中的向量运算来反应对文章内容的分析,搜索结果和用户查询之间的匹配度则用线性空间中的向量相似度来代替,这个向量相似度是用查询词形象化之后的空间向量和文章关键词形象化之后的空间向量进行计算得出的。
与布尔模型相比,向量空间模型的最大改进在于它包含了部分匹配的搜索结果。向量空间模型把原文章的核心内容用一些计算出了权重的特征来代表。所有的文档在这个模型中都被表示成一个n维向量,这些n维特征最为普遍的就是单词,还可以是语段、词组等,每个特征都会进项相应的权重计算。
特征权重计算:
在向量空间模型中,相对应的权值会在文档和查询进行转换时赋予给每个特征(即单词),采用TF-IDF框架来计算他们的权值是该模型最常用的方法。
1.词频因子(TF)–局部(一个文档)
最能反映文档主题的,往往是反复出现在这个文档中的单词,因此单词出现的频率越高的话,相对应的它的权值也应该越高。计算权值的公式有很多种变体,其中最简单的方法就是直接利用词频数作为TF值。
Wtf=1 log(tf) (2.1)
公式2.1是词频公式的一种变体。为了平滑计算结果,所以加入了数字1,而为了抑制差异过大的情况出现,公式采用了log运算。
Wtf=a (1-a)*[ tf / Max( tf ) ] (2.2)
公式2.2是词频公式的另一种变体。其中a是用来做调节的因子,这也称作增强型规范化Tf。
2.逆文档频率因子(IDF)–全局(文档集合)
不同单词区分文档的能力是有差别的,这样做的目的就是衡量这个差别,映射了某个特征词在整个文章集合中的布局情况,IDF值随着囊括这个特征词的文章数目的加大而减小,这个特征词对不同文章的分辨能力决定于IDF值的大小,IDF值越小则分辨能力越弱,IDF值越大则区分能力越强。
计算IDF值的公式为:
IDF=log(N/n) (2.3)
其中N代表文章集合中一共有多少文章,n代表特征词一共在多少文章中出现过。
3.TF*IDF框架
Weight(word)=TF*IDF (2.4)
相似性计算:
向量空间模型中的匹配度用查询和文章之间的内容匹配度来替代,搜索结果是文章和查询的匹配度得分从高到低的排序,但是这两者实际上并不完全等同。
定义Cosine匹配度的计算如下: 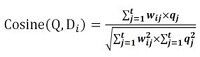 (2.5)
(2.5)
这个公式是定义计算用户查询Q和Di这两个不同元素的匹配度,分母部分是欧氏空间中两个特征向量的数值的相乘,作为对数量积计算结果的规范化(对长文档的削弱机制);分子部分是把查询的每个特征权重和文档的每个特征权重都进行相乘,并把乘积相加,这个求和的过程也叫做求两个向量的数量积。
向量空间模型的优点:
- 检索性能由于引用了术语权重的算法而得到了提高。
- 向量空间模型考虑了部分匹配,查询得到的结果更贴合用户的查询诉求。
- 结果文档可以根据对查询串的相关度来进行排序。
向量空间模型的缺点:
- 索引词之间被认为是相互独立的。
- 随着网页格式的多样化,网页信息的丰富化,这种查询方法查询出来的结果往往会与用户想要的反馈结果相去甚远。
- 容易产生很多无用信息。
2.3概率模型
课题毕业论文、开题报告、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。


