半监督学习算法研究毕业论文
2020-04-09 13:59:21
摘 要
时至今日,随着信息技术的迅猛发展,利用计算语言收集有效信息的情况越来越多,人们运用机器语言的地方也就越来越多,收集无标记的样本已经相当容易,而获取有标记的样本因为人力物力的原因则相对困难,机器语言学习领域的三大主要的领域:监督、非监督、半监督,半监督学习能对所有类型的自然样本数据,搭配适当的函数,综合利用再具体分类充分利用未标记样本改善学习性能,对实际情况合理地应对改善,因而,半监督学习依然成为机器学习中的热门。
为了可以有效地解决存在隐含变量问题而提供优化方法,本文想到一种数据添加的经典算法,也就是EM算法。 本文目标对象为半监督学习中的EM算法,希望对其进行简单的研究,通过其历史、现状与趋势,了解其发展,阐述其合理性,实用性和可靠性,并且根据算法建立GMM下的Kmeans模型,撰写聚类程序,通过其凹凸变换可以靠谱地找到“最优的收敛值”,观察其在MATLAB上仿真结果,展示在此半监督学习方法下所达到的分类效果,最后得出半监督学习对人类学习发展有着巨大重要性的结论。
当前各类的科学研究以及实际的现状在于应用方面得到巨大的进步,相对而言数据的采集处理等等相关工作量也就越来越大,经容易出现数据缺失、数据错误的的问题,运作工程中,合理地利用好EM算法,可以直接对数据进行附加标签的从而对原始数据进行改善与选择,促进各类学科的研究发展。而随着理论的发展,EM算法己经不仅仅局限于处理数据缺失的问题,人们用它处理的问题日益广泛,对它的学习也就变得尤为重要。
关键词:无标记; EM;数据缺失;稳定;优化
Abstract
In recent years, with the rapid development of information technology, more and more effective information is collected by the use of computational language, and more and more people use machine language. It is quite easy to collect unlabeled samples, and the acquisition of labeled samples is relatively difficult because of human resources. Machine linguistics is relatively difficult. There are three major fields in the study field: Supervision, unsupervised and semi supervised. Semi supervised learning can match all types of natural sample data with appropriate functions, and make full use of unmarked samples to improve learning performance by using the re specific classification. It's hot for machine learning.
In order to effectively solve the problem of hidden variables and provide optimization methods, this paper thinks of a classical algorithm of data addition, that is, EM algorithm. In this paper, the target object is EM algorithm in semi supervised learning. We hope to do a simple research on it. Through its history, current situation and trend, it understands its development, expounds its rationality, practicability and reliability, and establishes the Kmeans model under the GMM algorithm according to the algorithm, and writes the clustering program, and can be found by its concave and convex transformation. "Optimal convergence value", the simulation results on MATLAB are observed to show the classification results under the semi supervised learning method. Finally, the conclusion that semi supervised learning is of great importance to the development of human learning is concluded.
At present, all kinds of scientific research and actual situation lie in the great progress in the application, and the relative workload of data acquisition and processing is getting bigger and bigger. The problem of missing data and error of data is easy to appear. In the operation project, the EM algorithm can be used properly, and the data can be attached directly to the data. Tagging is used to improve and select raw data and promote research and development of various disciplines. With the development of the theory, the EM algorithm is not only limited to the problem of data loss. People use it to deal with more and more problems, and it becomes particularly important to its learning.
Key Words: unmarked ;EM ;data missing ;stability optimization
目录
摘要 I
第1章 绪论 1
1.1研究背景及意义 1
1.2研究现状 2
1.3研究主要内容 3
第2章 半监督学习极其算法的认识 5
2.1半监督学习的内容 5
2.2半监督学习与其他机器学习 5
2.2.1无监督学习 5
2.2.2有监督学习 7
2.2.3三种机器学习的对比与联系 7
2.3EM算法与其他半监督算法 8
2.4小结 9
第3章 方案的选择 10
3.1方案前的几个数学要点 10
3.1.1举个例子 10
3.1.2几个数学要点 10
3.1.3算法流程 11
3.2方案的对比 14
3.2.1 基于自训练的EM算法 14
3.2.2 GMM下Kmeans聚类先行的EM算法 16
3.2.3 基于增量式EM文本分类算法 17
3.3小结-最终选择 20
第4章 仿真设计 22
4.1选用仿真软件介绍 22
4.2功能介绍及结果 23
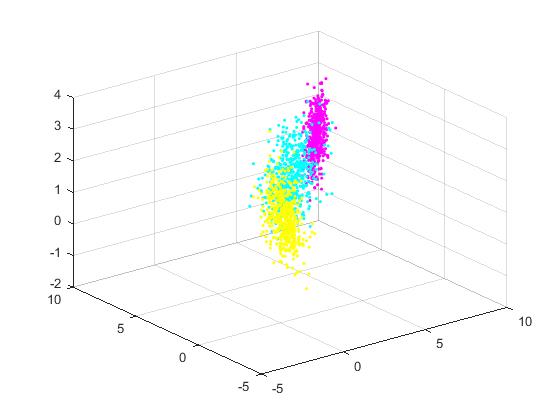
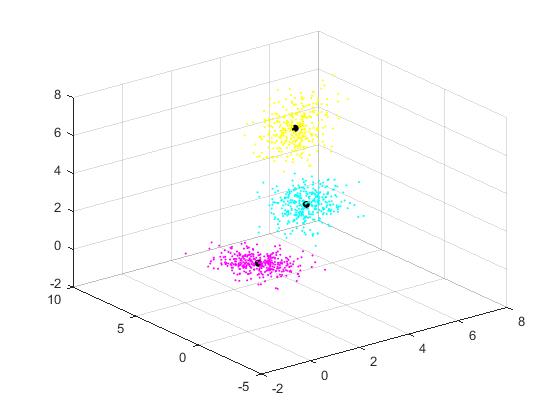
4.2.1生成高斯模型 23
4.2.2 EM解决GMM 26
4.3小结 32
第5章 总结与展望 34
5.1总结 34
5.2展望 35
致谢 38
附录 39
绪论
1.1研究背景及意义
上世纪70年代末,是人们对半监督学习最早的有载认识。人类意识到了未标记数据的价值,并且建立许多例如生成式学习的新模式。发展相对较晚的半监督学习,早些年或许是困于当时的机算计学习技术处理未标记对象较为困难。然而随着统筹领域的不断变化,原本的困难--收集大量未标记样本已变得相对容易,而相对的获取大量有标记的样本则变得困难,传统的机器学习也要求大量样本基底进行学习,这对人类学习来说可能是需要消耗巨大的人力物力,反而是种狭隘。半监督学习,通过训练得到学习,再根据‘经验’,综合利用未标记样本与有标记样本,寻找优势结果。其学习过程大致例下:
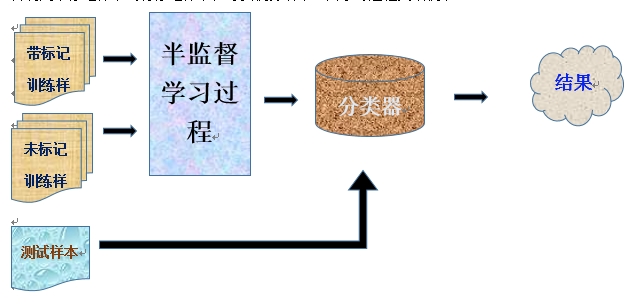
图1.1 半监督学习过程示例
很显然,半监督学习作为此类问题的一种优化方法,逐渐成为被广泛研究的热点对象。现如今,在语音识别、文本分类与结构预测等等数据调理方面,半监督学习有着不俗的表现,相信只要有足够多的开发,那么半监督学习在这些领域上的研究也就能够更加心应手。
1.2研究现状
现如今,半监督学习方法已经达到巨大的进步,应用范围也极其广泛。学者不断拓展半监督学习的应用范围,同时也在不断地结合其他数学方法以达到精益求精的效果。半监督学习方法已经不是简简单单地应用基本的三大假设。
在方法创新上,当前的半监督学习方法,很多都只关注如何平衡利用无标记样本和有标记样本,却忽视了如何在这些样本上构造能够真实反映样本之间相似关系的图,随着样本维度的增多,噪声特征和冗余特征也被大量引入的问题,很多常用的距离度量并不能较好地刻画样本之间的相似性关系。因此,如何在高维样本上构造关系,是半监督学习方法在高维数据上有效性的关键,这也是其它基于图的学习方法成败的关键。以提高半监督学习的精度为目标,以度量学习和集成学习为基本手段,对基于图的半监督维数约减、半监督分类和半监督多标记分类展开深入研究,提出了一些构图方案,并把它们结合到基于图的半监督学习中,提出了基于图的高维度半监督学习法。
在应用领域上,人们提出基于多学习器协同训练模型的人体行为识别方法。采用了基于分类器成员委员会的标记近邻置信度计算公式来评估未标记样本的置信度,选取一定比例置信度较高的未标记样本加入到已标记的训练样本集并更新学习器来提升模型的泛化能力.为了评估算法的有效性,采用混合特征来表征人体行为,从而可以快速完成识别过程.实验结果表明,所提出的基于半监督学习的行为识别系统可以有效地辨识视频中的人体动作. 从而可以快速完成识别过程.实验结果表明,所提出的基于半监督学习的行为识别系统可以有效地辨识视频中的人体动作。
在国外,同样研究出针对不平衡剪接位点数据集的集成半监督学习法。这一研究使用半监督分类器的集合,特别是自训练和共训练分类器,预测基因组中剪接位点的问题。对生物学的发展提供了一大助力。
当今世界还有很多基于半监督学习,或者基于EM算法的研究成果,不论是人脸识别和空间分析的半监督学习算法,或者是网络任务属性分析半监督学习等等都展示了半监督学习算法正在日新月异地发展中。
但在半监督学习迅猛发展至今,仍有其弊端其尚待改进:
i利用未标记样本得到的训练,有时并不能提升泛化能力,而是相反的不良效果。
ii其学习场合为模型假设不符合真实场景以及两类样本(有标记与无标记)分布差别较大时,将会导致性能下降。
iii随着训练进行,运作过程中自然产生的噪音会不断积累从而干扰到我们的学习结果。
除了弊端的现状,我们还发现,以往的半监督学习研究基本上的注意力都放在分类问题,而回归问题则相对少人问津。在分类问题日趋进益的现今,如果能相对地去关注一下回归问题,那么对半监督学习来说将是不错的发展。
1.3研究主要内容
本次设计内容为对半监督学习方法的研究,通过对半监督算法的学习,简历合理的模型进一步验证了解半监督学习,体会半监督学习在现今机器语言带给人的便利。
(1) 根据选定的课题,即半监督学习研究,查阅搜集相关的资料与书籍,对半监督学习涉及的学习方法进行了解,选择几个较为典型的案列做分析,总结所存在的利弊,寻找适合本次设计的方案。
(2) 理解掌握本设计课题中所搜集到的,确定算法,分析其进行方式。
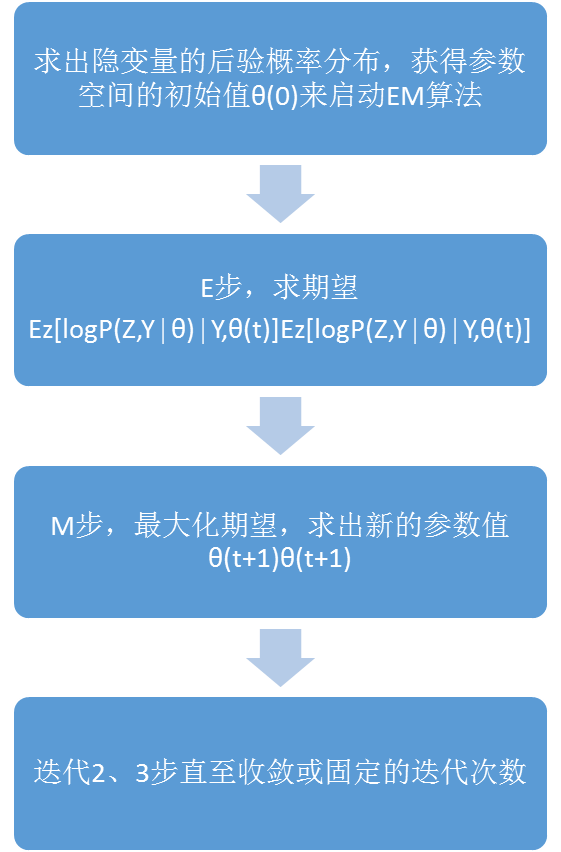
①分析算法运行方式:通过交替迭代E-step与M-step这两个步骤,逐步改进样本性质,增大似然概率数值,最后收敛于于一个极值点,使得模型的参数逐渐逼近真实参数
②本课题采用技术论证、方案比较的方法进行设计,从而得出符合设计目标的方案。
③学习、模拟程序,并进行仿真。
④对本课题设计成果进行总结评价。
第1章-第2章:本次课题选择此算法的背景、研究目的,以及算法内容、应用领域等等的介绍。
第3章-第5章:根据所选的算法进行程序撰写,仿真。
第6章:对本次设计的总体反思与总结
通过比较论证,充分体现本设计方案的合理性,验证半监督学习的优越性,最终实现预期目标,实现半监督算法的简单学习。
半监督学习极其算法的认识
2.1半监督学习的内容
半监督学习是利用数据分布上的模型,如果建立学习器对未标签样本进行标签。
形式化描写叙述为:给定一个来自某未知分布的样本集S=L∪U, 当中L 是已标记样本集L={(x1,y1),(x2,y2), … ,(x︱L︱ ,y︱U︱)}, U是一个未标记样本集U={x'1,x'2,…,x'|U|},希望得到函数f:X → Y能够准确地对样本x预測其标签y,这个函数可能是參数的,可能是非參数的,也可能是非数值。当中, x与x'均为d 维向量, yi∈Y 为样本xi的标签, ︱L︱ 和︱U︱分别为L 和U 的大小, 即所包括的样本数。半监督学习就是在样本集S 上寻找最优的学习器。怎样综合利用已标签例子和未标签例子,是半监督学习须要解决的问题。
半监督学习问题从样本的角度而言是利用少量标注样本和大量未标注样本进行机器学习。从概率学习角度可理解为研究怎样利用训练样本的输入边缘概率 P( x )和条件输出概率P ( y | x )的联系设计具有良好性能的分类器。这样的联系的存在是建立在某些如果的基础上的。即聚类假设(cluster assumption)和流形假设(maniford assumption)。
2.2半监督学习与其他机器学习
2.2.1无监督学习
无监督学习,简单的说就是样本没有标签的进行分类,我们有一些问题,但是不知道答案,我们要做的无监督学习就是按照个体的性质自动地分成很多组,每组的问题是具有类似性质的(比如身高在某个分布区间的会聚集在一组,体重分布在某一区间的会聚集在一组,兴趣........)。所有样本只有特征向量没有各自的标记,但是可以发现这些样本呈现出聚群的结构,本质是一个相似性质的会聚集在一起。把这些没有标记的样本分成一个一个组合,就是聚类(Clustering)。比如报纸上的新闻,报社每天会搜集大量的新闻,然后把它们全部聚类,再自动分成数十个不同的组(比如政治、军事、文化......),只一点,每个组内新闻都具有相似的性质。
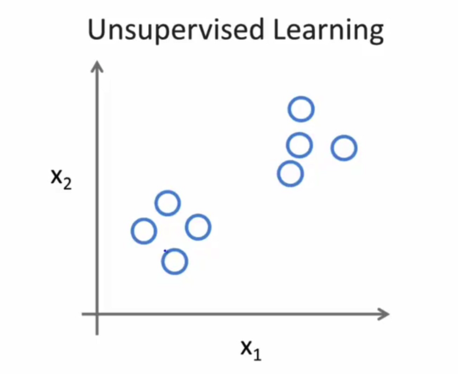
图2.1 无监督学习示例(分类前)
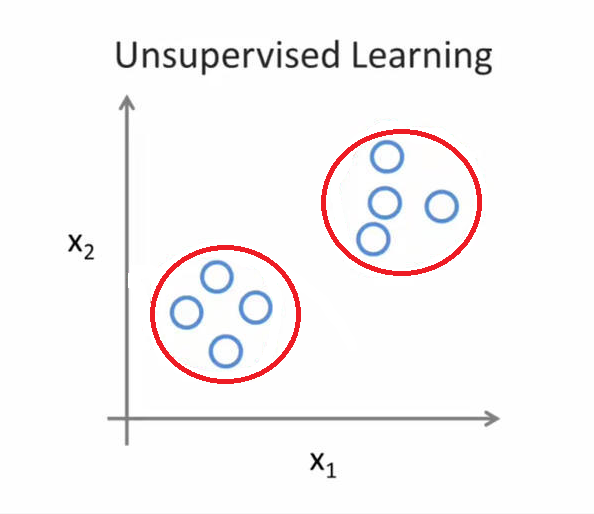
图2.2 无监督学习示例(分类后)
对于这样的分类方式,往往我们目的只在于要把东西进行分类,却不关心他的内容到底具体是什么。
2.2.2有监督学习
有监督学习就是某些已知特性作为训练,建立学习器,再利用这个学习器去预测或者说筛选待训练数据。所有的牙刷配对着他们对应的牙膏,有监督学习就是掌握这些已经知有牙膏的牙刷,学习完成就具备了牙刷对应牙膏的理念,这就是学习的成果。往后如果面对一个素未蒙面的没有牙膏的牙刷的时候,就可以运用所学的知识,或者说经验,反复推敲、琢磨从而得出相应的答案,给牙刷挤上牙膏。一个样本集,对于每一个单一的牙膏根据它的牙刷的学习得出牙膏的输出值,那么就是有监督学习。简相比而言,对牙膏和牙刷而言,有监督学习和无监督学习区别在于,有监督多了可以表示这个牙膏牙刷之间对应关系的点。
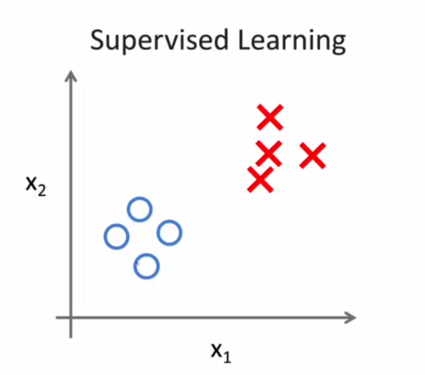
图2.3 有监督学习示例
2.2.3三种机器学习的对比与联系
笼统的说,我们把有标签标记的学习称为有监督学习,而没有标签代表样本性质的学习称为无监督学习。那么半监督呢,实际研究中的例子里,往往很多时候都不只是单纯的有标记或者单纯没标记,分类的目的很多时候考虑的情况也往往不会是不计内容或者需要太过清楚的条条框框,这时候,我们便考虑可以针对处理一部分有标记,一部分没标记的半监督学习方法,既至于过分的松,又不至于过分的紧。对于半监督,有两种极端的情况,一种即是当样例集合等于有标记的样例集合的时候,我们可以把半监督转化为有监督学习方式;而如果样例集合等于无标记的样例集合的时候,相同的,我们可以转化为无监督的学习方式。
半监督更像是介于两者之间的权衡者。
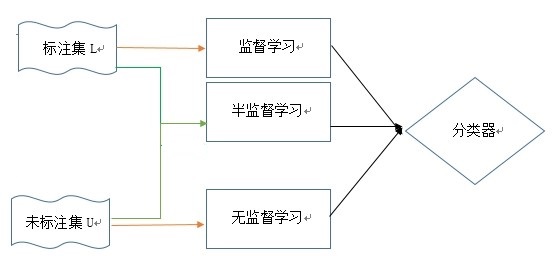
图2.4 机器学习示例
2.3EM算法与其他半监督算法
多视角算法:多视角算法多出现于数据分裂的样本集中,一般情况下,1个数据点表征1个特性,若出现一对多的映射,则每个初值点可看成两个映射对象的集合,然后进行协同训练。
转导SVM:通俗点讲就是归纳-演绎的方法,先从特殊到一般,这个特殊是人类根据已有的采集信息进行评定出来的规则,再从一般到特殊,也就与其他半监督学习法类似,掌握规则之后我们就可以用来处理问题。但是在转导模式中,我们进行直接中间一般总结推理,越过了推理中的不适应部分。
基于图的算法:基于图的算法现今是用的最为普遍的算法,基于图正则化框架,直接或间接地应用流形假设。具体过程是,建立一个图模,图中包含两种结点对应了不同的示例,相似度用边来表示,最后,使用决策函数在图上的光滑性作为正则化项来优化目标函数(须自行定义)求取最优模型参数。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示:


课题毕业论文、开题报告、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。


