基于关联分析的电影评分标准研究毕业论文
2020-04-09 15:33:07
摘 要
随着现代信息与互联网技术的发展,电影行业也受到了较大的影响,网络电影评分正在改变人们观影的选择,同时也潜移默化的改变着整个电影行业的环境。目前的网络评分模式还是存在着一定的争议,评分的可信度受到质疑。本文通过关联分析对电影评分进行研究,找到电影评分与其他属性的相关性,并且提出对评分方法的改进建议。
研究方法是通过分析软件spss modeler,运用关联分析等分析方法,对电影评分进行关联性分析。主要的研究内容有:运用网络爬虫进行电影数据爬取,研究电影评分数据与其他数据的相关性,并且提出自己对与电影评分方法的改进建议。
本文通过关联分析等方法,得到了电影数据中评分与其他数据关联规律,找出了影响电影评分的部分因素。
关键词: 电影评分 网络爬虫 关联分析 spss modeler
Abstract
With the development of modern information and Internet technology, the film industry is also affected by the larger, network film score are change people viewing options, but also exert a subtle influence on changing the environment of the entire film industry. At present, there is still some controversy about the online rating model, and the credibility of the rating is questioned. This paper studies film rating through correlation analysis, finds out the correlation between film rating and other attributes, and puts forward some Suggestions to improve the scoring method.
The research method is to conduct correlation analysis on film score by analyzing software SPSS modeler and using correlation analysis and other analysis methods. The main research contents are as follows: using web crawler crawl movie data, study the relativity between film score data with other data, and put forward their Suggestions for improvement to the method of and film scores.
In this paper, by means of correlation analysis and other methods, the association rules between scores and other data in film data are obtained, and some factors influencing film scores are found out.
Keyword: movie ratings, web spider, association analysis, spss modeler
目 录
第1章 绪论 1
1.1 研究背景 1
1.2 研究目的与意义 1
1.3 研究内容与研究方法 2
1.3.1 研究思路 2
1.3.2 研究方法 2
1.3.3 技术路线 2
1.4 国内外研究现状 3
1.4.1国内研究现状 3
1.4.2国外研究现状 3
1.4.3研究现状归纳 3
1.5 本章小结 3
第2章 相关知识 5
2.1聚类分析 5
2.1.1聚类分析基本概念 5
2.1.2 K-Means聚类方法 5
2.2关联分析 5
2.2.1关联分析基本概念 5
2.2.2 Apriori算法 6
2.3回归分析 6
2.3.1回归分析基本概念 6
2.3.2回归分析的主要内容 6
2.3.3回归分析研究的主要问题 7
2.4本章小结 7
第3章 数据收集与预处理 8
3.1数据收集 8
3.2数据整理 8
3.3数据预处理 9
第4章 电影评分数据分析 11
4.1电影评分聚类 11
4.2电影评分影响因素关联分析 13
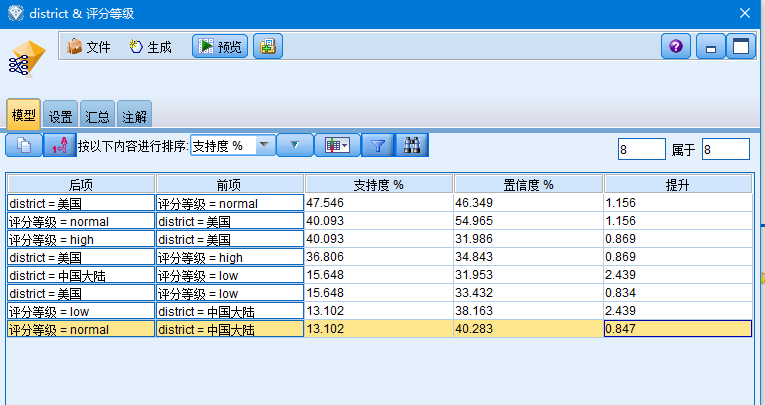
4.2.1 评分与制片国家关联 14
4.2.2 评分与语言关联 15
4.2.3 评分与电影类型关联 17
4.2.3 评分与上映时间关联 18
4.3电影评分影响因素回归分析 19
4.4 多因素分析 21
4.5 本章小结 22
第5章 思考与对策 23
5.1 引入变量 23
5.1.1热度值 23
5.1.2 评分结构 23
5.2 更改评分算法 23
第6章 总结与展望 24
附录 25
论文中实现爬虫的代码 25
getAllMovies.py 25
getDetails.py 26
参考文献 28
致 谢 29
第1章 绪论
- 研究背景
随着现代信息与互联网技术的发展,人们生活上受到了很大的冲击,在生活方式上都有很大的改变。从塞满各种卡的钱包,到一部手机走天下,这其中的跨度,也只是短短几年时间,人们的生活变得越来越便捷。在人民生活日益美好的今天,物质生活得到了极大丰富,但人民日益增长的美好生活的需要也对精神生活提出了更高的挑战。
看电影是一种比较大众的娱乐方式,电影行业也随着时代在不断发展进步,以满足人们对电影娱乐日益增长的需求。电影行业从露天广场走进了电影院,又从电影院走进了家家户户的电脑中。你不需要等待太长的时间,在空闲时打开电脑,点开一个网页,就可开始观看一部电影。
现代计算机技术的飞速发展,对电影行业又提出了新的挑战。原来的电影传播方式较为传统,通过报纸、电视等媒体进入大众的视野,各种电影评分网站的出现,无疑会对电影行业产生巨大的影响。在“互联网 ”时代,网络电影评分正在潜移默化地改变电影观众的观影取向[1]。许多人会选择在去电影院之前到各种电影评分网站上去了解电影的评分,通过评分来选择是看哪一部电影,这就对电影的票房产生了影响,所以网络电影评分对于电影行业来说是不可忽视的一个环节。
- 研究目的与意义
电影作为大众娱乐中较为受欢迎的娱乐方式,在娱乐行业发展的大潮下飞速成长,近年电影产业的爆发,使中国成长为仅次于北美市场的全球第二大电影市场,整个电影产业前进的同时,也让越来越多的民众愿意走进电影院。面对种类繁多的电影,如何选择一部合胃口的电影,成了每个观众需要面对的问题。事实上,由于电影行业的不平衡发展,导致出现了一系列的票房和口碑偏离的现象,即“烂片”大卖、大制作成“烂片”、佳作票房暴死等现象[2]。
电影行业在高速发展的同时,不出意料的受到了互联网的影响,在互联网上出现了大量影评网站,其中比较知名的就有豆瓣等网站,有专业的影评人对电影的评价,同时也允许网民在电影下的评论区进行评价打分。这种网络评分方式一定程度上影响了人们观影方式,越来越多的人会选择在网上看到热映电影信息后去浏览影评网站,选择观看评价较高的电影。
然而网络评分的可信程度受到一定的质疑,现行的网络评分方法大致都是根据用户评分取平均来展现的,这就导致评分受到一下几点的影响:1.用户评分样本太少,评分带有一定的个性;2.网站上存在“水军”恶意刷低分差评的的现象,导致评分缺少可信度[3]。建立一个更客观的评分方法可以更好的给用户推荐电影佳作,满足不同观影者的需求,同时也可以提升人民审美水平,净化电影观影环境。研究的目的分析出影响电影评分的因素,并且提出改善的建议,促进电影评分与电影品质口碑匹配。
- 研究内容与研究方法
- 研究思路
- 研究内容与研究方法
建立更加合理的电影评分机制的模型为目标,在借鉴国内外评价体系和研究现状的同时,建立新的电影评分模型,深入分析影响电影评分的因素,根据不同的影响因素设计权值,理清电影评分的设计模型对影响因素进行加权平均,并得出模拟结果,提出优化评分机制的建议,更好的完善网络评分机制,实现更加可信的电影评分机制。
- 研究方法
运用数据分析中的聚类分析和关联分析电影评分的影响因素,运用爬虫从网站收集电影相关数据,并通过spss modeler对电影进行聚类分析,将电影进行分类,并且对电影评分进行关联分析,找到影响评分的因素,最后对评分机制的改进方案提出建议,相关方法将在第二章中做介绍。
- 技术路线
研究现状、理论基础
研究背景、目的、意义
现行电影评分机制分析
电影聚类分析
评分影响因素关联分析
建议
图1-1 技术路线图
- 国内外研究现状
1.4.1国内研究现状
国内比较流行的评分网站分别是豆瓣、猫眼等。我国关于电影评分模型方向的研究较为空缺,主要是研究电影评分与电影票房的关联影响,对评分模型本身的研究较少,大都浅显的提到了评分机制的问题。如今豆瓣的评分体系主要是五分制,然后根据算法转化成10分制[4],根据豆瓣CEO在采访中表示豆瓣评分的主旨和原则是“尽力还原普通观影大众对一部电影的平均看法”。其他的网站的评分机制大致相似,根据人民日报刊登的《豆瓣、猫眼的专业评分面临信用危机,恶评伤害电影产业》[5],可以看出我国现行的电影评分机制是存在问题的。
豆瓣电影的评分大致可以根据五段百分比分布分为几类[6]:
- F型评分:5星评分占比较大,其他星级占比依次降低,低星级占比几乎可以忽略不计,总的分布呈现类似为英文字母“F”
- P型评分:评分集中在4-3星,并且5星占有一定比例,低星级占比较低
- E与b型评分:评分集中在2-3星,向两极递减
- L型评分:评分集中在1星,向高级递减
1.4.2国外研究现状
国外关于这方面的研究大多都集中在电影口碑方面,研究内容包括:电影的收入与电影评分的关联[7];通过分析电影留言板中的网络评价数据,来实现对电影票房的预测[8];通过媒体信息来对电影评分进行预测[9]等。针对电影评分,国外最老牌的电影评分社区IMDb的电影评分机制与其他网站大同小异,最终呈现出来采取贝叶斯算法的加权平均,针对大众评分受外部因素干扰的问题,还引进了专业评分[10]。
1.4.3研究现状归纳
国内外关于电影评分的研究主要是根据电影评分来进行对电影票房的预测以及对评分在上映前后一段时间的变化趋势研究。不足之处就是关于电影评分标准制定的研究比较少,没有一套关于评分标准的规范。本文设想通过研究电影评分与其他属性的相关性,对评分标准提出改进的建议。
- 本章小结
本章介绍了本文的研究背景、研究目的与意义、研究内容与方法、国内外研究现状等为研究电影评分模型的分析与建立所做的铺垫准备。通过本章的阐述,对于电影评分对于电影行业的影响有了更深入的了解,明确了本文的选题意义,对于研究方法以及研究内容进行了简要的介绍。通过技术路线更直观地了解全文的框架结构,通过国内外文献综述来了解该领域最新的研究成果为本文的后续研究提供理论基础。
第2章 相关知识
2.1聚类分析
2.1.1聚类分析基本概念
聚类分析是研究“物以类聚”问题的分析方法,将物理或抽象对象的集合分组为由类似的对象组成的多个类的分析过程。聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。聚类分析所使用方法的不同,常常会得到不同的结论。不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。
从实际应用的角度看,聚类分析是数据挖掘的主要任务之一。而且聚类能够作为一个独立的工具获得数据的分布状况,观察每一簇数据的特征,集中对特定的聚簇集合作进一步地分析。聚类分析还可以作为其他算法(如分类和定性归纳算法)的预处理步骤。
2.1.2 K-Means聚类方法
K-Means聚类也称快速聚类,得到的聚类结果,每个数据点都唯一属于一个类,而且聚类变量为数值型,并采用划分原理进行聚类[11]。为有效测度数据之间的差异程度,K-Means将收集到的具有p个变量的样本数据,看成p维空间上的点来定义某种距离。点与点之间的距离越小,说明他们差异越小,越有可能聚成一类,点之间的距离越大,说明差异越大,越有可能分属不同的类。
K-Means方法定义点与点之间的距离为欧式距离,数据点x与y之间的欧式距离是两个点的p个变量值之差的平方和和平方根,数学定义为[12]:
(2.1)
K-Means聚类算法采用划分方式实现聚类,具体过程是:1.指定聚类数目K;2.确定K个初始类中心点;3.根据最近原则进行聚类;4.重新选择K个类中心点;5.判断是否已经满足终止聚类的条件,如果没有就返回第3步,直到满足迭代终止条件。
2.2关联分析
2.2.1关联分析基本概念
关联分析的目的就是要寻找事物之间的联系和规律,发现他们之间的关联关系。事物之间的关联关系包括简单关联关系和序列关联关系。关联分析的主要技术是关联规则,最早由阿格拉瓦尔(Agrawal)、依米林斯基(Imielinski)、和斯瓦米(Swami)提出,主要用于研究超市顾客购买商品之间的规律,希望找到顾客经常同时购买的商品,进而合理摆放货架,方便顾客选取,该分析成为购物篮分析[13]。
简单关联规则的分析对象是事物,事物(T)通常由事物标志(TID)和项目集合(项集X)组成。简单关联规则的测度指标包括:
- 规则置信度,描述了包含项目X的事物中同时包含项目Y的概率,反映X出现的条件下Y出现的可能性,其数学表示为:
(2.2)
- 规则支持度,表示项目X和项目Y同时出现的概率,其数学表示为:
(2.3)
- 规则提升度,反映了项目X的出现对项目Y出现的影响程度,一般大于1才有意义,说明X对Y有促进作用,越大越好。其数学表示为:
(2.3)
2.2.2 Apriori算法
Apriori算法第一步是简单统计所有含一个元素的项集出现的频率,来决定最大的一维项目集,在第k步,分两个阶段,首先通过第(k-1)步中生成的最大项目集来生成候选项目集,然后搜索数据库计算候选项目集的支持度。
Modeler 采用的是对Apriori算法的改进算法。其特点是:
(1)只能处理分类型变量,无法处理数值型变量。
(2)数据可以按事务表方式存储,也可以按事实表方式存储。
(3)算法是为提高关联规则的产生效率而设计的。
2.3回归分析
2.3.1回归分析基本概念
回归分析(Regression Analysis)是一种统计学上对数据进行分析的方法, 主要是希望探讨数据之间是否有一种特定关系。线性回归分析是最常见的一种回归分析, 它用线性函数来对因变量及自变量进行建模(自变量和因变量都必须是连续型变量), 这种方式产生的模型称为线性模型。线性回归模型由于其运算速度快、直观性强以及参数易于确定等特点, 在实践中应用最为广泛,也是建立预测模型的重要手段之一。
2.3.2回归分析的主要内容
1.从一组数据出发,确定某些变量之间的定量关系,即建立数学模型并估计其中的未知参数,进行可信程度检验,一般用最小二乘法估计参数;
2.判断哪个(或哪些)自变量的影响是显著的,哪些是不显著的,将影响显著的选入模型,而提出影响不显著的,通常应用逐步回回、向前回归和向后回归等方法;
3.利用所求的关系式对某一生产过程进行预测或控制。
2.3.3回归分析研究的主要问题
1.确定Y与X之间的关系表达式(回归方程);
2.对求得的回归方程的可信度进行统计检验;
3.判断自变量X对因变量Y有误影响极其程度;
4.利用所得的回归方程进行变量的预测和控制。
2.4本章小结
本章介绍了聚类分析和关联分析以及回归分析三种分析方法的相关概念和基本理论知识,简要介绍了使用的相关算法,并叙述了其工作原理,为后续的分析内容打下基础。
第3章 数据收集与预处理
3.1数据收集
首先,要找到待收集的数据,我们选取在豆瓣网站上的电影详情页面运用网络爬虫的方法来收集网页上的电影数据。
图3-1 豆瓣电影详细页面
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示:



课题毕业论文、开题报告、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。


