基于卷积神经网络的脑部MR图像分割毕业论文
2020-04-10 16:57:51
摘 要
本文介绍了一种基于卷积神经网络的脑部MR图像分割方法。这种方法的核心是基于区块的卷积神经网络模型,这个模型包括了三个部分分别是预处理部分、神经网络训练与预测部分以及结果可视化部分。为了得到最好的分割性能,本文设计了四种不同的神经网络结构,并对它们进行了对比,最终得到一种最佳的网络结构,即区块大小为18*18的卷积神经网络,该网络有4层卷积层,没有池化层。该网络的总体准确率为94.97%,脑脊液的相似性系数为79.99%,脑灰质的相似性系数为93.68%,脑白质的相似性系数为95.26%,最后我们也将人工分割和本文算法分割的切片进行了对比,发现两者的分割结果基本相似。相比传统方法而言,本文采用的方法具有自动学习的特点,无需人工寻找特征点,同时神经网络具有鲁棒性,抗噪声能力较强,同时随着深度学习的不断发展,基于卷积神经网络的分割方法准确率也非常高。
关键词:卷积神经网网络;脑部MRI;图像分割
Abstract
This article introduces a segmentation method of brain MRI based on convolutional neural network. The core of this method is a patch-based convolutional neural network model. This model includes three parts: the preprocessing, the neural network architecture and visualization. In order to get the best segmentation performance, this article designs four different neural network architecture and compares them to obtain the best network structure which is a convolutional neural network with patch-size of 18*18. This network has 4 layers of convolutional layers and no pooling layer. The overall accuracy rate of the network is 94.97% while the dice ratio of cerebrospinal fluid, gray matter and white matter are 79.99%, 93.68%, 95.26%. Finally, we also compare the result of artificial segmentation with the result of algorithm segmentation. We found that the result of both segmentation method is very close. Compared to the traditional method, the method used in this article can learn features automatically. At the same time, the neural network is robust and cannot be affected by noise. With the development of deep learning, the accuracy of the segmentation method based on CNN will be increasingly high.
Keywords: CNN;brain MRI;image segmentation
目录
摘要 I
Abstract II
第1章 绪论 1
1.1脑部MR图像特点 1
1.2脑部MR图像的分割目的和意义 1
1.3本文的结构 2
第2章 脑部MR图像分割 3
2.1图像分割的定义 3
2.2图像分割的评价方法 3
2.3脑部MR图像分割的主要算法 4
2.3.1 FCM 4
2.3.2高斯混合向量 4
2.3.3区域生长算法 5
2.3.4动态控制模型 5
2.3.5 LVQ 5
2.3.6 SOM 6
2.3.7基于深度学习的方法 6
第3章 基于卷积神经网络的脑部MR图像分割方法 8
3.1系统流程图 8
3.2数据预处理 9
3.2.1数据集 9
3.2.2数据导入和数据裁剪 9
3.2.3数据归一化和零均值 10
3.3卷积神经网络分层结构 11
3.3.1卷积层 11
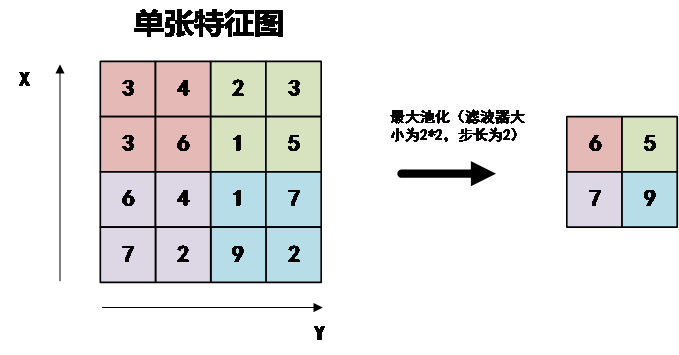
3.3.2池化层 12
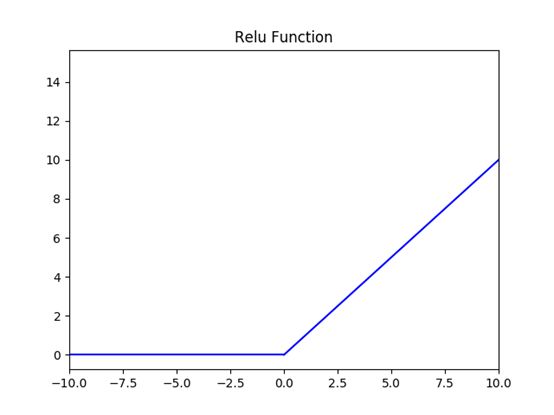
3.3.3激活函数 12
3.3.4 softmax分类器 14
3.3.5 Dropout 15
3.4卷积神经网络总体结构 15
3.5训练参数设置 17
3.6结果可视化 18
3.7小结 19
第4章 测试与结果分析 20
4.1测试环境 20
4.2不同区块大小的卷积神经网络对比 20
4.3Batch Normalization的性能 25
第5章 总结与展望 27
参考文献 28
致谢 30
第1章 绪论
在实际研究和临床检测中需要对脑部进行扫描,而核磁共振图像(MRI)在这一方面是最常用的方法。图像分割一直是医学图像分析中十分重要的部分,在很多临床应用中,它往往是最开始也是尤为关键的一步。在对脑部 MRI分析时,图像分割经常用于脑部解剖结构的测量和可视化,同时它也 可以用于分析脑部的病变情况、划分病理区域、辅助手术规划以及由影像引导的自动干预。 在过去的二三十年里,已经有很多方法被提出用于脑部 MRI的分割,它们有着不同的准确率以及复杂度,很多甚至已经开始被广泛使用于临床实践中。 在本文中我们采用的是最近十分流行的卷积神经网络对脑部MRI进行分割,这种方式具有自主学习的能力,同时具有较好的鲁棒性。
1.1脑部MR图像特点
核磁共振图像是一种用于放射学的医学影像技术,它可以形成解剖图,同时可以观测健康和患有疾病的人的生理变化。MRI扫描仪通过强磁场、电场梯度以及无线电波来生成身体器官的扫描图像。与其他的医学影像技术相比,MRI具有较高的组织对比分辨力,能根据软组织的生理特征把它们区分开,而且对人体而言是一种无损检测。
理想的脑部MR图像应该是分段常量图像,因为理想状态下的同一种脑组织无论在哪个位置对于核磁共振序列都应该有相同的反应,同时不同的脑组织之间的灰度值相差很大,这两个特点为脑部MR图像的分割带来了极大的便利。但是由于个体之间的差异较大、MR成像不可避免的会产生较大的噪声以及不同的容积效应的影响,也给脑部MR图像分割带来了一定的挑战。
脑部是人类的中枢神经系统,有着强大的功能和复杂的结构,从脑部解剖图来看,大脑被分为了很多脑组织,分割的目的就是要将这些脑组织分割出来,在本文中我们重点研究的是脑白质脑灰质以及脑脊液这三个部分。脑部MRI主要有三种加权项,分别是T1加权像、T2加权像以及质子密度加权像。
1.2脑部MR图像的分割目的和意义
医学图像分割一般由人工分割或者由计算机进行自动分割,人工分割主要依托于人类对于医学图像的先验知识,虽然人工分类的准确性目前仍然是最高的,但是由于医学图像往往是三维图像,导致数据集往往很大,因此人工分割是一种耗费时间和精力的工程,特别是对大批量数据进行处理时,然而,随着计算机的发展,大量模型以及算法都在医学图像分割上有着优良的表现,其中不乏一些较为经典的办法,也有基于最近几年很流行的深度学习的算法。
除此之外,脑部MR图像分割就是把脑部组织如脑白质、脑灰质、脑脊液等组织从脑部MR图像中分割出来,由于大脑的结构与这些组织之间有着密切的关系,所以对这些组织进行分割在对颅脑进行定量形态学的分析方法上是极为重要。同时脑部MR图像分割对于脑结构的可视化和定量研究也有很重要的作用,是研究人脑的功能以及不同病理条件的先决条件。
1.3本文的结构
本文主要介绍了基于卷积神经网络的脑部MR图像分割算法,并对其进行了验证与讨论。本文一共由五个部分组成:
第一章为绪论部分,简单介绍了脑部MR图像的特点以及脑部MR图像分割的目的和意义。
第二章首先介绍了图像分割的基本概念和方法,然后系统的介绍了当前主流的医学图像分割方法,同时对每种方法进行了讨论和评价。
第三章首先介绍了卷积神经网络的概念和特点,介绍了本文采用的卷积神经网络结构,并对该结构进行分析。
第四章主要展示了利用卷积神经网络进行脑部MR图像分割的结果,并对预测结果进行可视化与分析。
第五章对全文的工作进行了总结,并在现有工作的基础上提出了改进意见。
第2章 脑部MR图像分割
2.1图像分割的定义
图像分割就是将图像按照需求划分成我们感兴趣的、各具特性的区域的过程,被分为相同的一类的区域往往有相同的某种特征。这些特征可以是图像的灰度、颜色、纹理、边缘以及事先定义的相关规则等,它们可以包含一个或者多个区域。
我们可以从集合概念来理解图像分割的定义:假设集合R代表整个图像的像素,这个图像的分割就是将集合R划分为若干满足以下条件的非空子集。
- 对于所有的i和j,,有;
- 对于,有;
- 对,有
- 对,是连通的区域。
上述条件(1)表示分割后的所有的子区域的并集是图像中的所有像素,即每一个像素都被划分为事先预定的某一类中。条件(2)表示划分出的各个子区域应该是相互独立的,即图像中的每一个像素只能分为事先预定的某一类,而不能同时被分成两类或者多类。条件(3)表示分割之后属于同一类的像素点应该具有某种相同的特性。条件(4)表示分割之后属于不同类的像素点之间应该具有某种不同的特性。条件(5)表示同一个子区域内的像素点应该是连通的。
2.2图像分割的评价方法
到目前为止,还没有一种能够适应所有图像、所有任务的分割方法,各种算法往往都有很强的针对性。因此,对分割算法的性能进行定量评价在实际应用中显得尤为重要。对图像分割算法进行评价需要有一套评价标准,即评价指数。在图像分割领域中有很多种评价方法,在本文中主要用到的两种评价方法分别是分割准确率和相似性系数。分割准确率是最基本的图像分割评价方法,它的主要标准是某一类的分割正确的数量占这一类总数的比例,这种方法能够粗略的得知分割结果的好坏,如果精确度过低往往代表着分割算法还有待改进。除了分割精确度以外,相似性系数也是医学图像分割领域经常使用的一种评价方法[1]。我们假设A和B代表了人工分割和算法分割的同一类像素点的集合,则相似性系数可以定义为:
(2.1)
这里代表了人工分割的某一类的像素点的集合,代表了算法分割中某一类像素点的集合,表示了算法分割中与人工分割结果相同的像素点的集合。这种评价标准比分割准确度更为可靠,因为它不仅涵盖了算法分割的结果还包含了人工分割的结果。相似性系数的大小在[0,1]中,相似性系数越高,分割的准确率也就越高。
2.3脑部MR图像分割的主要算法
2.3.1 FCM
FCM[2]是由Bezdek提出的基于最小目标函数的一种聚类方法:
(2.2)
这里q代表了聚类的模糊程度,u是数据的模糊成员,用来聚类中心点,d表示数据和聚类中心j,之间的距离,u有如下的定义条件:
(2.3)
这个成员函数和每个聚类的中心定义如下:
(2.4)
(2.5)
FCM通过持续更新成员函数和聚类中心来优化目标函数,知道每一次与上一次之间的优化值超过一个阈值。FCM被广泛应用于医学图像处理[3]。
2.3.2高斯混合向量
高斯混合模型[4]是利用概率密度来推测每一类的分布,j类的高斯混合模型有如下的概率密度:
(2.6)
这里L是高斯分量的数目,x 是输入数据、是高斯分量l的最大概率,是高斯分量l的概率密度函数,它可以表示为:
(2.7)
这里是分量l里的训练函数的中心值,是高斯分量l中训练数据的协方差矩阵,d是x的维数。期望最大化法(EM)和Lioyd聚类算法经常用于计算高斯混合模型的参数。
2.3.3区域生长算法
区域生长法是一种简单的基于区域的图像分割方法,它同样也是一种基于像素的图像分割方法,因为它包含了初始种子点的选择。这种分割方法检验初始种子点附近的像素,从而决定周围的像素是否添加到现有的区域中,这种过程以相同的方式不断的叠加。在实际应用中区域生长法主要由分为三个步骤,第一步确定一组能够正确表示所选区域的种子点,第二步确定种子点不断扩大延伸的规则,第三步要确定区域增长一直到什么时候停止。区域生长法往往不会单独使用,在脑部图像分割中,往往先用区域生长法处理图像中的头骨和其他杂质,然后对脑实质进行分割。但是这种算法的缺陷是,每一个区域都需要人工设置一个初始种子点,同时这种算法对噪声也十分敏感,会使区域出现不连续性。
2.3.4动态控制模型
动态控制模型是基于一条曲线,X(s)=[x(s),y(s)],它被定义为s在[0,1]范围内是弧长的图像域。它以最小化能量函数的方式改变形状。该能量函数具有以下形式:
(2.8)
右侧第一 项称为内部能量,用于控制变形曲线的张力和刚度。 最后一项是用于指导变形曲线朝向目标的外部能量。
2.3.5 LVQ
学习矢量优化(LVQ)是一种竞争的监督学习[5]。LVQ根据训练数据获得输入空间的决策边界,同时LVQ也定义了类边界原型、一种最近邻规则和胜者为王规则。LVQ有三层,分别为输入层、竞争层和输出层。每个目标类有几种模式,竞争层学习类似于自组织映射(SOM)的方式分类输入数据,并且输出层将竞争层类(模式)映射到目标类。学习方法根据训练数据调整神经元的权重,优胜神经元是基于欧几里得距离指定的,然后调整优化神经元的权重。
有很多种方法可以用来学习LVQ网络,LVQ1就是其中一种,LVQ1基于每个数据的正确目标类别在竞争层中选择一组最佳匹配神经元; 如果分类正确或错误,分别调整选定集合的权重以接近或远离输入数据[5]。
LVQ1有两个主要步骤:首先找到一组与输入数据最相似的神经元,由相似因子如欧几里得距离确定,其次,根据输入更新那些神经元的权重。换句话说,如果分类是正确的,选定的神经元的权重或者更接近输入,或者如果分类不正确,则移动远离输入。
2.3.6 SOM
自组织映射(SOM)是Kohonen于1982年提出的一种无监督聚类网络,它是神经网络领域中流行的网络之一。它将可以高维的输入映射到神经元单元的一维或二维离散晶格。它根据像欧几里得距离一样的相似性系数来将输入数据分为不同的模式,每种模式都分配给一个神经元。每个神经元的权重取决于分配给该神经元的模式。根据Tian和Fan的观点,网络会学习输入的规律性和相关性,并调整其之后的响应[5]。它根据输入空间中的分组对输入数据进行分类,并且相邻神经元在输入空间中相邻,因此SOM学习输入数据的分布和拓扑结构。换句话说网络映射保存映射到邻居神经元的输入和相邻输入中的拓扑关系。它由两层组成,第一层是输入层,该层中的神经元数等于输入的维数。第二层是竞争曾,每个神经元在脑部MR图像分割方法中对应一个类(模式)。该层中的神经元数量取决于聚类的数量,竞争层中的神经元像网格一样排列成规则的几何结构。权重向量被分配给从输入层到竞争层中的神经元的每个连接。
SOM有两个主要步骤。 首先,找到胜利的神经元,即根据相似性因素如欧几里德距离对输入来说最相似的神经元,其次,更新赢得神经元的权重及其相邻像素的基础上输入。 换句话说,获胜的神经元及其相邻像素的权重朝向输入改变。
2.3.7基于深度学习的方法
早期图像分析研究中我们所采用的神经网络方法大多是3层结构,如上面提到的LVQ和SOM,这种结构的运算相对简单,对设备的运算能力要求相对不高,但由于网络的复杂性不够,无法了解图片更深层次的信息。随着计算机技术的迅速发展,计算机的运算能力越来越强,越来越多的深度学习网络被提出。
深度学习是一种机器学习中的一种方法,它来源于人工神经网络。David Rumelhart、Geoffrey Hinton以及其他学者把前向传播算法应用到人工神经网络中,从而使得神经网络应用于数据模型[6]。人工神经网络局限于复杂的结构和训练时间过长,因此深度学习应运而生,由于硬件的发展,深度学习可以学习不同层次的特征,它的作用在于学习不同层次的表达以及一些有趣的数据结构,现在的深度学习方法与人脑的运作方式十分相似,最近几年深度学习不断发展,它已经被应用到目标识别任务如ImageNet以及特征学习等方面[7]。
卷积神经网络是一种全部可训练的多层网络,它是深度学习中的一种方法,也是目前应用于图像处理最为广泛的深度学习算法。它可以学习到一张图片的不同层次的特征[8]。卷积神经网络的训练样本不局限于一维数据,它也可以训练二维和三维的图片以及视频卷积神经网络的隐藏层包含卷积层和池化层,这些层得到的特征图代表了从前一层得到的特征数据[9]。
而随着卷积神经网络在目标识别上的快速发展,卷积神经网络在图像分割上也取得了重大成果,主要的分割方法分为两种,一种是基于区块的分割方法[5][10][11],通过一个区块的图像预测这个区块中心点所属的类型,然后最后按照顺序再将这些预测后的像素点拼接起来,得到我们所需的分割图。这种方法所需要的与处理时间较长,因为在训练神经网络之前需要将原始数据分为一个一个的区块,另外这种方法存在的问题是,每一个区块的感受域有限制,忽略了很多全局的特征。FCN(全卷积网络)[12][13]是一种端到端的图像分割方法,与基于区块的方法不同,它的输入和输出都是图像,所以网络的输出就是我们所需要的分割图像,同时FCN的优点在于它不用像基于区块的方法需要对数据进行大量的预处理和后处理,所以减少了工作量,更重要的是FCN的输入是任意大小的图片对输入没有要求,具有很好的拓展性。但是这种方法也有它的缺点,由于为了防止过拟合,FCN网络中往往会有下采样也就是池化过程,这样以来图片的尺寸就会被裁剪,为了能够输出相同大小图片需要对图片进行上采样或者反卷积,而这两个步骤都会使得最后的输出不够精细。
这两种方法各有各的特点,针对不同的任务,我们可以采用不同的方法进行分割,在此基础上已经发展出了很多新的方法和网络结构,比如DeepLab[14],U-net[15]等方法,并且被证实在图像分割任务上有较好的表现。
第3章 基于卷积神经网络的脑部MR图像分割方法
人工神经网络是由从人脑的学习能力得到的灵感,人脑由突触相互连接的神经元组成。 事实上,至少在理论上他们能够学习任何给定的映射,达到任意的精度。另外,它们允许将有关任务的先验知识轻松加入网络架构。在1993年,LeCun 等人介绍卷积神经网络在计算机视觉中的应用[16]。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示:





课题毕业论文、开题报告、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。


