基于MFCC的语音信号特征提取研究毕业论文
2020-04-11 17:51:59
摘 要
在所有生物特征中,语言特征是最方便、实用和自然的。因为在每个人的讲话中使用诸如牙齿,舌头,喉咙,肺和声道的发声器官,它们在形状和大小上存在很大的生理差异,所以不同的人有不同的发音形式,每个人的声音都有很强的个人色彩。此外,语音的生成,传输和提取非常容易实现。因此,利用语音特征进行识别的说话人识别技术将得到广泛的应用。在语音识别应用中,如何提取语音信号的特征参数将是其中的关键之一。本文提出了基于MFCC的语音信号特征提取方法,并通过MATAB进行了仿真实验。论文的主要工作有:
首先分析了声音的产生过程,给出了MFCC的简单解释以及基于MFCC的特征参数提取的意义。
其次,详细描述了MFCC提取特征参数的过程,包括预加重、分帧、加窗、快速傅里叶变换、三角窗口滤波、求对数、离散余弦变换、频谱加权、差分参数等。
最后对matlab结果进行了分析与比较。
关键词:语音识别;语音信号;MFCC;特征提取;时域和频域
Abstract
Of all the biometrics, language is the most convenient, practical and natural feature of human beings. Because of the use of sound organs such as teeth, tongues, throat, lungs and vocal tract in each person's speech, there is a great physical difference in shape and size, so different people have different forms of pronunciation, and each person's voice has a strong personal color. In addition, the generation, transmission and extraction of speech are very easy to implement. Therefore, speaker recognition technology using speech feature recognition will become the most convenient, safest and most environmentally friendly identification technology in biometric technology. The extraction of feature parameters is one of the key technologies of speech recognition. In this paper, the feature extraction of speech signal based on MFCC is proposed, and the simulation experiment is carried out by MATAB. The main work of the paper is as follows:
First, the process of sound generation is analyzed, and a simple explanation for MFCC is given, and the significance of extracting feature parameters based on MFCC is also discussed.
Secondly, the process of extracting characteristic parameters of MFCC is described in detail, including pre accentuation, frame splitting, adding window, fast Fourier transform, triangular window filtering, logarithm, discrete cosine transform, spectral weighting, differential parameter and so on.
Finally, the results of MATLAB are analyzed and compared.
Keywords: speaker recognition; speech signal; MFCC; feature extraction; time domain and frequency domain.
目 录
第1章 绪论 1
1.1研究背景 1
1.2研究意义 1
1.3国内外研究现状 2
1.4特征参数提取和语音识别技术存在的难点和问题 2
1.5本文主要工作 3
第2章 语音信号处理理论基础 4
2.1语音的产生 4
2.2 语音的听觉机理 4
2.3语音信号的数字模型 5
2.4语音信号的基本特征 6
2.4.1 共振峰 6
2.4.2 基音周期 6
2.5 语音信号的时域和频域特性分析 6
2.5.1时域特性 6
2.5.2 频域特性 8
2.6说话人识别方法 9
2.7本章小结 9
第3章 基于MFCC的特征参数提取 11
3.1 特征参数的选取标准 11
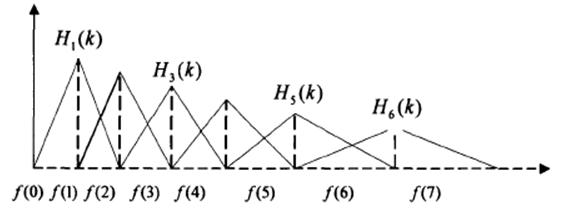
3.2 mel频率的相关概念 11
3.3 MFCC参数的提取过程 12
3.3.1 采样和量化 13
3.3.2预加重 13
3.3.3 分帧 13
3.3.4加窗 13
3.3.5快速傅里叶变换 14
3.3.6三角带通滤波器 14
3.3.7对数能量 15
3.3.8倒谱 15
3.3.9动态差分参数提取 16
3.4本章总结 16
第4章 Matlab仿真分析 17
4.1 Matlab简介 17
4.2 MFCC静态参数提取 17
4.3 MFCC差分系数的提取 18
4.4特征提取的改进和优化 19
4.6基于双门限检测法的端点检测 21
4.6.1双门限检测法的定义 21
4.6.2双门限检测法的matlab实现 24
4.7本章总结 25
第5章 总结与展望 26
5.1 总结 26
5.2展望 26
参考文献 28
致谢 29
绪论
1.1研究背景
语音是人类言语,思想,情感和交流的独特方式。它是人类最自然,最快速的交流平台。它也是人类最方便有效的交流工具。语音信号是声音信号的重要分支。
随着信息技术的迅猛发展,人类社会正在逐渐进入信息时代。计算机的应用也渗透到各个领域。在当今社会,人们不仅仅局限于人与人之间的交流与沟通。
语音信号的发展和研究一直与计算机科学领域密不可分,并且有着广泛而深远的联系。1907年,电子管的出现和1920无线电波的发明在一定程度上放大了微弱的语音信号,促进了语音声学和电声学的有机结合。在20世纪70年代,随着电子技术和计算机的进一步发展,模拟语音信号可以被模数转换器(A/D)采样和量化,并可以在计算机上实现数字信号处理,然后实现对语音信号的处理和数字化,并逐渐形成语音信号的时域分析和频域分析处理两大类[1]。在此基础上,语音信号处理这门新兴学科应运而生。
语音信号处理是涉及多个学科的跨学科学科。这也是一个以生物声学和信号与信息处理技术为基础的新型综合学科,为许多新兴学科和研究领域铺平了道路。将生物学,物理学,信息科学技术和人工智能有机地结合在一起。在现代信息社会中,语音信号处理技术正与商业管理,行政办公,交通,刑侦等公共管理行业同步推进,让人类以最高效、先进和快速的方式来存储、阅读和应用语言信息。例如,定时通讯、手机、飞信、微信等通讯方式,可以让人们轻松地将文字翻译成语言,然后将语音转换为文字。在此基础上,人们还在一些领域实施了语音翻译机,可以自动翻译中、英文或其他语言;语音输入打字机(也称为听写机)可以自动将人们的声音转换为计算机可读代码,智能识别人们的愿望和订单,并自动实施相关的行动。可以说,语音合成、语音可视化和语音识别的技术已经渗透到了各个领域。
1.2研究意义
随着社会经济和科学技术的不断发展,个人身份识别的数字化、快速性、准确性变得越来越重要。然而,与信息社会的便利形成鲜明对比的是,人们不得不携带各种卡,例如身份证、银行卡等,以及各种复杂的密码。如果一旦这些卡片遗失,被犯罪分子有机可乘,那么就有可能造成严重的后果。基于此,为了个人身份识别的准确性和安全性,利用人本身独有的生物特征来识别就显得特别重要。在诸如指纹、人脸、虹膜和声音等生物识别特征中,声音具有独特的优势:
- 可以快速简单地获取语音;
- 获取语音的仪器使用较为简单,识别成本不高。例如一个麦克风即可完成语音的录制;
- 适宜远程身份确认。通过网路(通信网络或互联网)完成远程登录仅需要一个麦克风或电话或手机;
- 说话人识别的算法复杂度低;
1.3国内外研究现状
语音识别的研究起源于上个世纪五十年代,当时研究人员想研究发音因素的特征。直到1952年,贝尔实验室的工作人员才完成了关于特定说话人英语孤立词语的识别,到了1962年,贝尔实验室的 L.G.Kesta提出了一个全新的概念——声纹。优点在于直观明了,因为只要经过稍加训练,观察者就能发现不同语谱图之间的差别;缺点在于不能定量的描述,无法通过现代工具计算机进行识别。伴随着数字信号处理技术取得长足的发展以及在语音识别的应用,1969年倒谱(Cepstrum)技术终于在语音识别中得到了运用,并且得到了较为满意的识别结果。1980年Davis和Mermelstein提出了MFCC的概念,MFCCs(Mel Frequency Cepstral Coefficents)是一种在自动语音和说话人识别中普遍运用的特征。MFCC的优点是它很好地模拟了人耳的听觉感知原理,具有较好的识别效果和鲁棒性,逐渐成为语音信号特征提取的主要参数[2]。
进入21世纪以后,国外知名公司和国内知名企业自行研发的语音识别产品广泛应用于手机、电脑等设备上。随着计算机技术的飞速发展,这一成果充分表明中国已进入国际语音技术的前沿研究领域。
1.4特征参数提取和语音识别技术存在的难点和问题
尽管特征参数提取和语音识别已经发展了半个世纪,但仍有许多不尽人意的因素,主要表现在:
- 信号的不稳定性。即使同一个人说同一段话两次结果也不可能完全相同。说话者的声音不是固定不变的,它受到讲话者年龄、心情和健康状况的影响。例如人感冒造成鼻阻塞时会导致声音频率发生较大变化;悲伤与开心时声音的特征又有较大区别;喉咙发炎时基音周期的变化等。
- 语音往往是可以被模仿的。经常在电视上可以看到有民众对明星的声音进行模仿,很多情况下甚至难辨真假。单纯的娱乐模仿当然无可厚非,但是如果被不法分子利用进行犯罪或者洗脱嫌疑,后果将非常严重。这就要求特征参数提取的相当准确。
- 特征参数不是说话者整体声学特征的最有效和最准确的反映。
- 噪声环境下的语音识别。由于语音识别从实验室环境走向了实际应用,不同环境背景下对识别率的影响效果很大,现实环境下噪声消除技术已成为研究热点[3]。
1.5本文主要工作
本文主要研究了MFCC参数的提取原理和过程,并在MATLAB上进行了结果分析,论文主要内容:
- :绪论。主要介绍特征参数提取的研究背景和发展现状。
- :语音信号处理理论基础。熟悉语音信号产生机制和语音信号的基本特征,从时域和频域两个方面理解语音信号的特征表示。并做了仿真实验分析验证。
- :MFCC概述。从数学和图形两方面来解释MFCC的提取原理。
- :基于MFCC的特征参数提取。详细讨论了MFCC特征参数提取的步骤,并在MATLAB上对结果进行了分析。
第五章:总结与展望。对MFCC参数提取进行了梳理与总结,并提出了今后的研究方向。
第2章 语音信号处理理论基础
2.1语音的产生
人体的肺和气管,喉和声道构成了发声器官。肺是语音产生的能量来源。气管连接肺部和喉部,是肺和声道之间的纽带。喉咙是一个复杂的软骨和肌肉系统,包含一个重要的发声器官-声带。声带是产生语言的主要激励来源。声道是指从声门(喉)到嘴唇的所有发声器官,包括喉、嘴和鼻腔。当人从大脑接收到发声命令时,首先由肺产生压缩空气流,使得声带通过声道周期性地打开或关闭,从而形成规则的间歇气流,形成声源。在发声过程中,由声门的气流引起声带的振动产生类似于周期性脉冲串的声音称为浊音,类似于噪声而不会引起声带振动的音叫轻音[3]。空气通过喉部流向口腔或鼻腔,并扩散形成人们听到的声音。人的发音器官示意图如下:
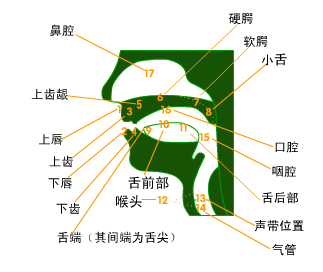
图2.1 人的发音器官示意图
2.2 语音的听觉机理
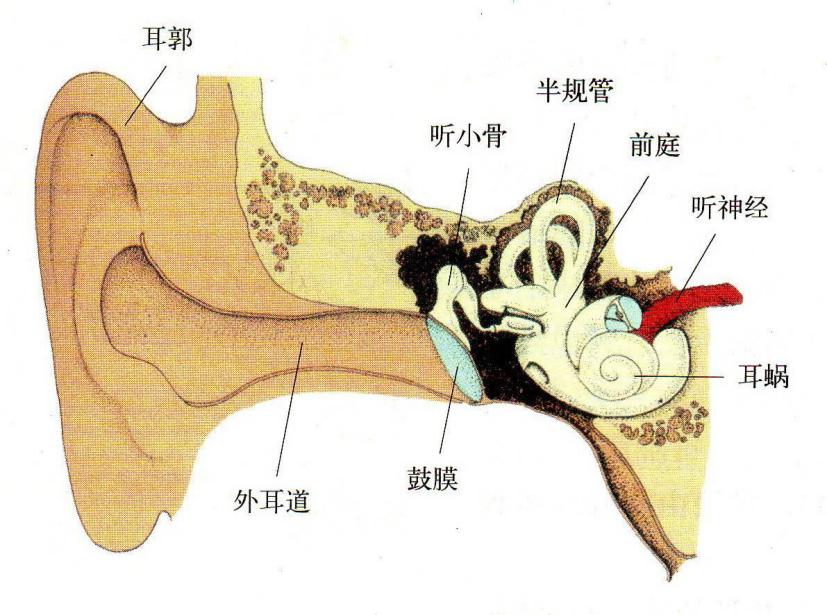
人的听觉器官包括外耳、中耳和内耳。外耳由耳廓、外耳道和耳骨(耳膜)组成;中耳由三块听小骨组成,它们是锤骨、砧骨及镫骨;内耳是由前庭,卵形窗,圆窗和耳蜗组成的充满流体的骨质结构。外耳和中耳的综合作用相当于500HZ到6KHZ之间的平滑滤波器,可用有限冲激响应FIR来模拟。当声音通过外耳进入中耳时,镫骨的运动引起耳蜗中流体压力的变化,这导致行波沿基膜传播。在耳蜗底部,基底膜具有非常高的硬度,并且流体波传播相当快。膜的硬度越来越小,波的传播速度越来越慢。不同频率的声音产生不同的行波,并且峰值出现在基底膜的不同位置。人耳的结构示意图如下:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示:

课题毕业论文、开题报告、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。


