基于深度学习的人脸特征检测研究毕业论文
2020-04-11 17:59:36
摘 要
自从2012年Alex在ILSVRC上提出的AlexNet以压倒性的优势超过传统手工模型以及其他深度学习模型并夺得冠军后,CNN吸引了越来越多人的注意,更新更复杂的CNN结构不断被提出。
本文提出一种改进型的CNN模型——D-CNN模型以解决人脸特征检测问题。不同于传统手工模型或单层神经网络,D-CNN模型包含两层神经网络,第一层用于解决人脸识别问题,第二层用于解决人脸特征检测问题。相对坐标的引入使得第一层的结果能大大提高第二层的准确率。
与传统CNN模型92.18%的人脸识别率相比,在FDDB人脸数据集的测试集上,第一层网络可以取得99.15%的人脸识别率。与传统人脸特征检测方法与给定特征点0.1的欧式距离误差相比,在LFW人脸识别数据集的测试集上,第二层网络可以取得与给定特征点0.02的欧式距离误差。
关键词:卷积神经网络 人脸识别 人脸特征检测
Abstract
Since Alexet put forward by Alex win the championship of ILSVRC in 2012 with an overwhelming advantage over traditional manual models and other deep learning models win the championship of ILSVRC in 2012, CNN has attracted more and more attention, and newer and more complex CNN structures have sprung up.
An improved CNN model-D-CNN model is presented in this paper to solve the problem of face detection. Unlike traditional manual models or single-layer neural networks, the D-CNN model consists of two neural networks. The first layer is used to solve face recognition problems, and the second layer is used to solve face feature detection problems. The introduction of relative coordinates makes the results of the first layer greatly improve the accuracy of the second layer.
Compared with the 92.18% face recognition rate of the traditional CNN model, on the test set of the FDDB face data set, the first layer network can achieve 99.15% face recognition rate. Compared with the traditional European face feature detection method and the Euclidean distance error of a given feature point of 0.1, the L2 network can obtain a Euclidean distance error of 0.02 from a given feature point on the test set of the LFW face recognition data set.
Keywords: convolutional neural network ;face recognition ;face feature detection
目录
第1章 绪论 1
1.1 研究目的及意义 1
1.2 国内外研究现状 3
1.3 本文研究内容 4
1.4 本文结构安排 5
第2章 深度学习理论 6
2.1 深度学习 6
2.1.1 深度学习介绍 6
2.1.2 深度学习常用模型 7
2.2 卷积神经网络 10
2.2.1 卷积 10
2.2.2 网络结构 11
2.3 深度学习常用框架 13
第3章 D-CNN模型第一阶段 16
3.1 简介 16
3.2 AlexNet 17
3.3 数据源制作 18
3.4 模型训练 19
3.5 识别人脸框 20
第4章 D-CNN模型第二阶段 22
4.1 简介 22
4.2 网络结构 22
4.3 全局阶段 24
4.3.1 算法框架 24
4.3.2 多标签数据源制作 25
4.3.3 模型训练 25
4.3.4 识别人脸特征点 26
4.4 微调阶段 28
4.4.1 算法框架 28
4.4.2 识别人脸特征点 28
第5章 模型检验 29
5.1 简介 29
5.2 改进效果 29
5.3 多姿态检验 30
第6章 总结与展望 32
参考文献 33
致谢 35
附录 程序清单 36
第1章 绪论
1.1 研究目的及意义
人脸面部特征检测是一种用于研究人脸面部特征的基于计算机实现的技术,它利用计算机提取人脸的相关特征,并给出人脸特征点的位置。人脸特征检测问题一般被定义为:对于给定的图片或视频,寻找出图片或视频中人脸的位置并找出其中的人脸特征点(眼睛,鼻子,嘴巴等),通常是以特征点坐标值作为检测结果,如图1.1所示人脸特征点分布。 人脸特征检测是人脸分析的基础,是视频监控、表情识别、家庭相册库管理、虚拟化妆技术等人脸应用的前提,如图1.2所示虚拟化妆技术。
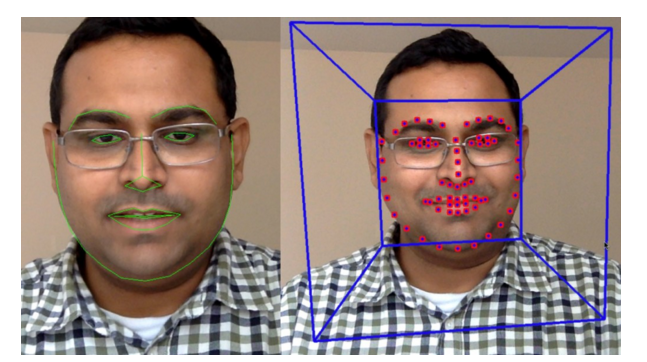
图1.1 人脸特征点分布示例

图1.2 使用虚拟化妆技术前后对比
在生物识别领域,人脸检测技术具有简单,快速,直观,准确,可靠,不需要人工合作的优点。人脸检测在人工智能领域扮演着非常重要的角色。人脸检测技术具有的优势使其在计算机视觉,图像处理,模式识别,多媒体,心理学等领域得到了广泛的应用。
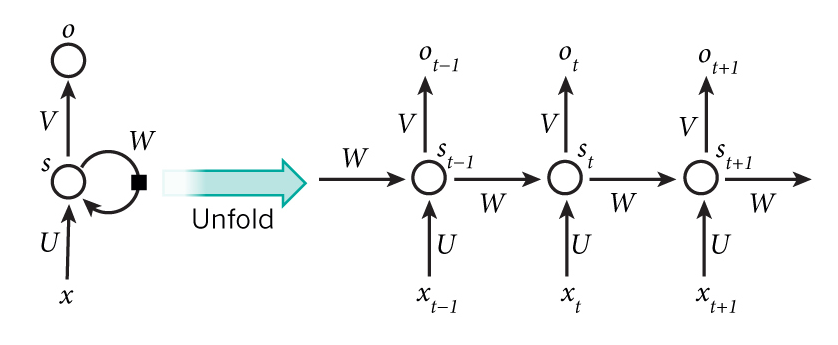
深度学习是机器学习的一种类型,它可以学习以从图像,文本或声音中执行分类任务。通常我们使用神经网络架构来实现深度学习。 术语深度是指网络中的层数[1]。传统的神经网络只包含2层或3层,而深度网络可能有数百层。
由于人类视觉研究的进一步发展,神经网络的研究在20世纪70年代后取得了突破性的进展,人们对机器识别也产生了越来越浓厚的兴趣,人脸特征检测随之发展成为了一个单独的研究领域,这一领域同时具有重大的理论价值和巨大的实用价值。
人脸特征检测对深度学习理论的完善和人工智能技术的发展都具有重大意义:首先它促进了人们对人类视觉感知系统进一步的理解;其次人脸特征检测技术可以运用于某些实际应用领域,比如单位门禁系统,公司上下班打卡等。与目前较常用的其他识别方法(如虹膜检测、指纹检测和DNA检测等)相比,人脸特征检测具有更广阔的应用前景。人脸特征检测技术具有以下三个优点:
①不需要直接接触,上述的其他身份识别方法需要经过被检测对象的配合才能进行,但是人脸特征检测的方法不需要人工干预,可以通过摄像头等电子设备,在不与检测对象直接接触的情况下,获取图片,以用于识别其人脸特征。
②操作便捷,使用限制小,使用方便易得的手机摄像头等就可以满足人脸特征检测系统的需要。
③人脸特征检测的整个过程都是按照既定的配置由计算机完成的,不需要人工参与。
正是由于人脸特征检测技术具有上述优势,它引起了相关研究人员越来越多的关注。
综上所述,基于深度学习的人脸特征检测研究具有重要的现实意义和理论意义。
1.2 国内外研究现状
传统的机器学习技术较难处理大量结构化的原始数据, 长期以来, 构建一个模式识别系统或机器学习系统是一件相当困难的工作,它需要丰富的工程经验和可靠的专业知识,过程包括设计一个特征提取器, 把结构化数据转化为合适的中间特征以作为机器学习系统的输入。
随着计算机硬件尤其是GPU的飞速发展,基于深度学习的人脸特征检测研究在最近十几年取得了一系列突破性的进展。
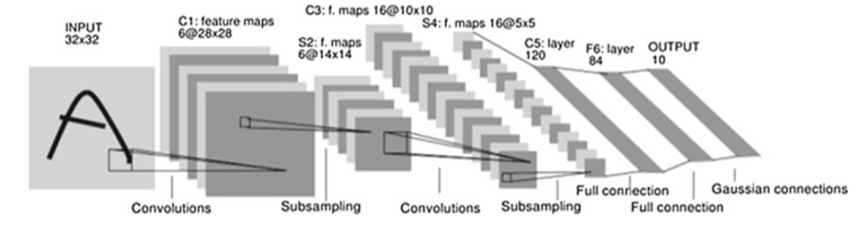
LeCun在1998年提出的LeNet结构被认为是现代CNN(Convolutional Neutral Network卷积神经网络)的开端[1]。高丽萍等人在2002年提出了一种改进的特征脸方法——特征半脸法[2],该方法将人脸图像分成上下两个区域,对上半区域和下半区域分别使用特征脸方法,最后在识别时对上半区域采用较大的权重,下半区域采用较小的权重,求得综合距离最小的人脸图像序号,从而完成人脸识别任务,经过改进特征半脸方法在精度上优于传统的特征脸方法。
2012年,Alex Krizhevsky在 ILSVRC(ImageNet大规模视觉识别挑战赛)中首先提出了AlexNet[3]并以15.4%的误差率夺得第一名,远超第二名26.2%的识别率,此后CNN模型在图像识别领域逐渐占据领导地位。
Donahue等提出了R- CNN算法(Region CNN区域卷积神经网络算法),该算法首先利用Selective Search将原始图像分为2000个相同分辨率的区块, 接着将这些区块输入CNN中以提取特征值, 再经分类器进行分类识别工作, 找到特征窗口, 最后使用回归器进一步修正特征窗口的位置。
Zhang等提出了SPP(Spatial Pyramid Pooling,空间金字塔池化)算法,SPP-Net将原始图像划分为2000个候选窗,接着利用金字塔空间池化将待检测图像输入CNN网络,并提取固定长度的特征向量,最后采用SVM (Support Vector Machine,支持向量机) 算法进行特征向量的分类识别工作。SPP-Net算法解决了R-CNN算法特征提取过程中卷积重复计算的问题, 因此检测效率得到了很大的提升。
Girshirk等提出了fast R-CNN算法和faster R-CNN算法,相比R-CNN算法,它们分别引入了一个简易的SPP层——感兴趣池化层(Region of Interest Pooling Layer)和一个 RPN(Region Proposal Network, 区域建议网络)来进行特征提取工作。
Redmon等提出了YOLO算法,该算法是一种分类网络结构,它将原始图像分成若干个小区域,对这些小区域进行特征提取工作,然后将提取到的特征逐级汇总。
Anguelov等提出了SSD算法,该算法将网络分成两个部分,一个分类相关层和一个卷积特征层。卷积层的特征图大小是随机的,这样的设计使得SSD算法能处理不同大小的识别目标。
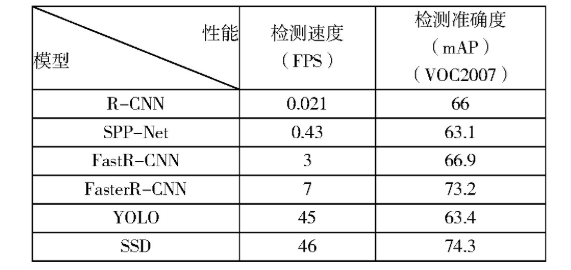
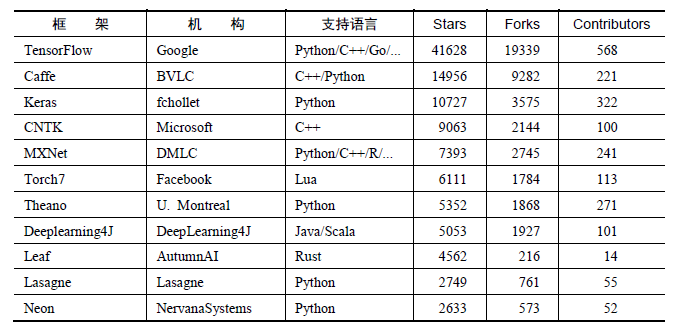
Donahue,Zhang,Girshirk,Redmon,Anguelov等人提出的算法[4]在实质上都是对LeNet和AlexNet的改进和补充,它们的检测准确度有明显的提升,但检测速度有明显的下降,这些深度学习模型的比较如表1.1。
表1.1 一些深度学习模型的比较
1.3 本文研究内容
传统的基于深度学习人脸特征检测算法采用的是多标签训练模型,在这种模型下,检测的结果是人脸关键点的绝对坐标,由于人脸大小不同,人脸在不同图片中的位置也不尽相同,以这种绝对坐标来作为神经网络的训练监督会使得模型的收敛效果和最后结果的准确率受到很大的影响。
本文提出一种结合人脸识别(以矩形框形式给出人脸位置)与人脸特征检测(以坐标的形式给出人脸关键点)的D-CNN(Double Convolutional Neutral Network,双层卷积神经网络)模型,该模型能识别人脸区域并将左眼,右眼,鼻子,左嘴角,右嘴角总计五个特征点标出。
不同于传统人脸特征检测算法的单个卷积神经网络,D-CNN模型包含两个卷积神经网络,整个检测过程分为两个阶段完成。第一阶段使用AlexNet经典模型给出人脸的位置并将位置信息存储到文件中,第二阶段从文件读取人脸位置信息,并在此基础上利用CNN模型预测出人脸特征点相对人脸框的坐标信息,从而得到人脸特征点的相对坐标,接着将其转化为绝对坐标。
由于人类五官相对与人脸的位置相对固定,使用这种相对坐标的方式能明显减小训练量。
此外,第二阶段的CNN模型通过细分操作还能进一步的减少训练和检测时间。本文将第二阶段人脸检测细化为两个阶段,全局阶段和微调阶段。全局阶段预测五个特征点的大概位置,微调阶段在全局阶段的基础上进行微调。
1.4 本文结构安排
本文结构安排如下:
第1章 绪论。主要介绍了基于深度学习的人脸特征检测研究的目的和意义,以及国内外关于深度学习在人脸特征检测方向应用的研究,并阐述了本文的研究内容以及行文结构安排。
第2章 深度学习理论。主要介绍了深度学习的基本概念并着重介绍CNN(卷积神经网络)的数学原理。
第3章 基于CNN的人脸识别算法。本部分主要介绍D-CNN模型的第一阶段——人脸识别阶段,该阶段使用CNN结构的AlexNet作为处理网络。
第4章 基于CNN的人脸特征检测算法。本部分主要介绍D-CNN模型的第二阶段——人脸特征检测阶段,为了进一步提高检测准确率以及检测速率,本部分对第二阶段的算法再一次进行优化,将其细分为两个阶段——全局阶段和微调阶段。
第5章 模型检验。本部分将D-CNN模型的优化结果和已有模型进行比较,并完成分析工作。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示:
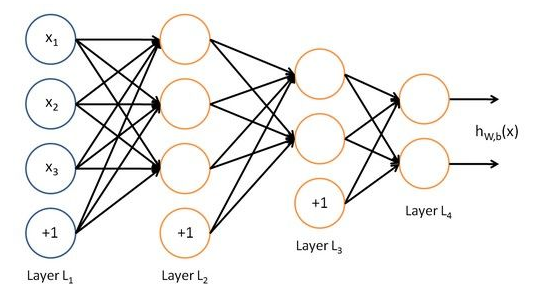

课题毕业论文、开题报告、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。


