基于大型平行语料库的机器翻译词素偏好研究 A Parallel-corpora Study of Morpheme Preferences in Machine Translation毕业论文
2020-04-12 15:41:09
摘 要
本文整理出联合国平行语料库内约三亿词的语料数据,统计并比较了人类翻译和机器翻译的用词行为特征。作者从大量语料资源中筛选提取出符合研究条件的样本,从中英文原文提出,预处理后输入至谷歌翻译以得到中文机翻译本。而后对中文人工译本、中文机翻译本、和英文原文进行分词和标注词性处理,并对标签统计结果进行比较分析。结果表明,人类翻译和机器翻译对词性的把握总体上一致,而区别集中体现在虚词和副词等语素的使用上。一系列具体的偏好趋势在数据中得以体现,同时的显现的还有人机翻译中句法区别。以上结论中具有代表性的几个被提取出来集中分析,并结合实例进行了解释。本文的研究成果可能对机器翻译的改进研究和电脑的自然语言处理方面有一定价值。
关键词:机器翻译;平行语料库;语素
Abstract
This paper compares the lexicon preference of human and machine translation based on the statistical analysis of a 300-million-word parallel corpus. Multiple corpora sources were examined and filtered, after which a large sum of English text from the United Nations Parallel Corpus are selected to be pretreated, and later translated into Chinese using Google Translate. The translation result is segmented and POS tagged for comparison with its human-translated counterpart and English original. Results display a high level of similarity between the two, with differences lying mostly in structural or functional word usage. The comparison of morpheme frequency also lead to discoveries of syntactical variance. Several notable trends and correlations are discovered and analyzed in detail with examples given. This study can help computational linguists determine improvement plans for machine translation algorithms and natural language processing systems.
Key Words: Machine Translation; Parallel corpus; Morpheme
Contents
1 Introduction 1
2 Research method and data Source 2
2.1 Overview 2
2.2 Tools used 4
2.3 Data source 5
3 Pretreatment and processing 6
3.1 Pretreatment 6
3.2 Processing and obtaining results 6
4 Analysis 10
4.1 Overall 10
4.2 Specific cases 11
5 Conclusion 23
Acknowledgements 24
References 24
Appendix 26
A Parallel-corpora Study of Morpheme Preferences in Machine Translation
Introduction
The Evaluation of machine translation (MT) is an important field of work for both computer scientists and linguists. By exploring how MT algorithms process natural languages, it becomes clearer how machines can be improved, and how the human language work (Doddington, 2002). Past research have made much progress in different approaches of MT evaluation.
Manual evaluation by professional linguists is a mature method characterized by high levels of accuracy but low efficiency (Papineni, 2002).
To achieve a similar purpose, the focus of computer scientists varies from optimizing evaluation criteria to utilizing specially trained AI for error detection.
As suggested in more recent research, the combined effort of human language professionals and computer evaluation can yield more promising results (Popović, 2014). Both morphological and syntactical studies have been conducted before, yet none has done so on the United Nations Parallel corpus, nor are they all up-to-date concerning the current development of neural machine translation, whose machine learning process is substantially different from that of statistical or rule-based systems in the past (Wolk, 2015). With regard to the above, the author conducts this research using the most recent version of Google Translate (Google Translate 2018), based on a sample of more than 300 million words, in an attempt to disclose the patterns by which the MT system chooses morphemes differently from human translators.
Research method and data Source
Overview
The goal of this study is to differentiate on a large scale the styles by which human translators and machines use different types of Chinese morphemes. On a sample of over 300 million words, it is considered impractical to measure the exact usage difference of each morpheme within each context (Papineni, 2002), doing so is extremely time consuming and will cause the focus to be lost among thousands of different words or phrases and the unclear connections within. Hence, the subject of this research is chosen to be the parts of speech (POS) in translation, which effectively depicts the morpheme types. POS differences do not necessarily reflect the correctness of text, but are evident enough for the purpose of distinguishing stylistic bias. (Tanawongsuwan 2010)
The language pair being studied is English-Chinese. 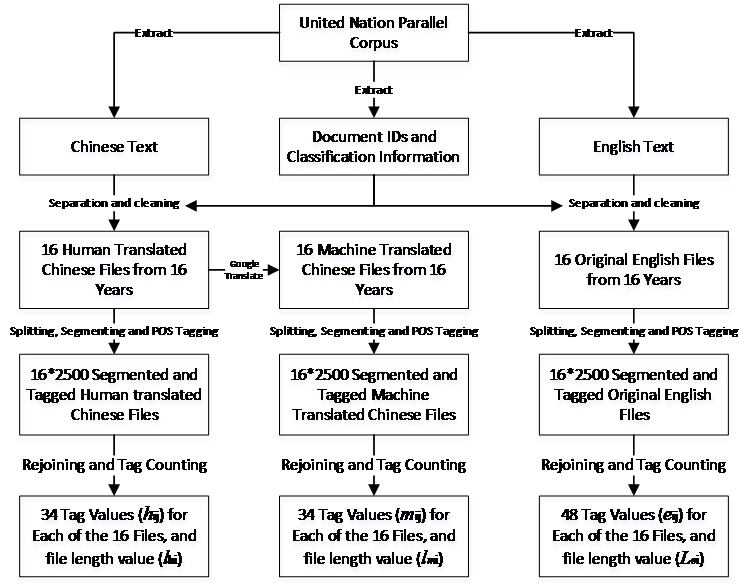
Figure 2.1 Steps from raw data to refined parameters
The course of this study can be divided into three steps, the first two are shown in Figure 2.1.
- Data collection, selection, and pretreatment
- Data processing and obtaining results
- Compilation and analysis
In step 1, a large amount of raw text is obtained and filtered. Those considered research-worthy are reformatted and rearranged for further processing. Unusable data is removed during the rearrangement.
In step 2, the English part of the parallel text is translated into Chinese via Google Translate. The resulting translation, along with the Chinese part of the original text, is segmented by morpheme units. Each unit would then be given a tag according to which POS it belongs to. The segmentation and tagging process is repeated on the English original using English standards (Schmid, 1995).
课题毕业论文、开题报告、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。


