基于Web的图像搜索技术的研究毕业论文
2020-04-12 15:56:17
摘 要
现如今我们处于一个飞速发展的时代,信息对于这个时代的意义越来越大,在过去人们主要通过文字传递信息,随着便携式通信设备的飞速发展,人们越来越习惯使用图像传递信息,图像比起传统的文本信息更加直观,让人容易理解,一张图片可以涵盖大量信息,提高了信息传递效率。随着网络的快速发展,网络上更是出现了海量的信息,其中不仅仅是文本信息,还包含了大量的图像信息,人们迫切需要图像搜索技术,来高效率精准的从大量图像中挑选出自己想要的信息,如何有效的管理和检索大量的图像对今后信息时代的发展具有重大意义。
目前图像检索领域有三种主流方式,首先基于文本的图像检索(TBIR),人们从20世纪70年代就开始研究这种方法,不检索图像的内容语义,而是着手于文本描述,例如绘画作品的作者,年代,尺寸,流派,回避对于图像的可视化分析,这种方法较为简单,但是已经远远不能满足现代社会的需求,而且这种方法需要人工标注,较为受限;90年代以后,人们开始研究基于内容的图像检索(CBIR),着重于对图像的内容特征进行检索,主要研究图像的可视化特征,包括图像的颜色特征、纹理特征、形状特征,这种方法虽然提高了效率,但是基于单一特征的图像检索出现失误的几率大大增加,并且无法精准的表现图像的内容特征。
本文立足于实际,通过将图像的颜色特征、纹理特征和形状特征相结合,构造了一个基于颜色纹理和形状特征内容的图像检索模型,完成了多特征融合的图像检索方法的设计与实现。其中图像的颜色特征使用颜色距以及颜色直方图来进行特征提取,使用欧式距离来进行相似度测度,有效提高了图像搜索的准确率;图像的纹理特征通过灰度共生矩阵以及LBP算法提取,同样通过欧式距离进行相似度测度,有效提高了匹配的精确度;图像的形状特征通过Hu不变距和Gabor小波变换提取,同样通过上述方式测度。最后利用三种图像内容特征相融合,实现了精准度较高的web图像搜索模型。
关键词:web图像检索;SSI框架;LBP算法;图像特征提取
Abstract
Nowadays we are in an era of rapid development. Information has become more and more important for this era. In the past, people used text to convey information. With the rapid development of portable communication devices, people are more and more accustomed to using images to transmit information. Compared with traditional textual information, it is easy to understand that a picture can cover a large amount of information and improve the efficiency of information transmission. With the rapid development of the Internet, there has been a tremendous amount of information on the Internet, including not only text information but also a large amount of image information. People urgently need image search technology to efficiently and accurately select from a large number of images. The information they want, how to effectively manage and retrieve a large number of images is of great significance to the future development of the information age.
At present, there are three mainstream methods in the field of image retrieval. The first is text-based image retrieval (TBIR). People began to study this method since the 1970s. Instead of retrieving the content semantics of images, they started to describe texts, such as paintings. Authors, ages, dimensions, genres, and avoidance of visual analysis of images are relatively simple, but they are far from meeting the needs of modern society. This method requires manual annotation and is more limited; after the 1990s, people began to Research on content-based image retrieval (CBIR) focuses on the retrieval of image content features. It focuses on the visualization features of the image, including the color features, texture features, and shape features of the image. Although this method has improved efficiency, it has made mistakes. The odds are greatly increased, and the content features of the image cannot be accurately represented; nowadays, a large number of images on the Internet not only contain their own content semantics, but also the web pages on which they are located provide a large amount of textual information related to them, based on content and text. Image search can not only accurately depict Image features, efficiency is very high, is to retrieve web images most suitable method.
This article is based on reality, completes the content-based image retrieval model, and constructs the model through the color features, texture features, and shape features of the image. The color features of the image are extracted using the color distance and color histogram, and the Euclidean distance is used. Similarity measure. This method can effectively improve the accuracy of image search; the texture features of the image are extracted by the gray level co-occurrence matrix and the LBP algorithm, and the similarity measure is also performed by the Euclidean distance, which effectively improves the matching accuracy; the shape of the image is not affected by Hu. Variable pitch and Gabor wavelet transform extraction, also measured by the above methods, finally integrated the three methods and completed a high-precision web image search model.
At last, this paper uses the SSI model to set up a web server to complete the image retrieval model.
Key Words:web image retrieval;SSI framework;LBP algorithm;Image feature extraction
目录
第1章 绪论 1
1.1 web图像检索的研究现状 1
1.2 web图像的特点 1
1.3 基于文本和内容的图像检索 1
1.4本文完成的工作 2
第2章 基于文本的图像检索 4
2.1自动标注模型 4
2.2词汇相似度计算 5
第3章 基于内容的图像检索 7
3.1基于颜色特征的图像检索 7
3.1.1颜色直方图 7
3.1.2颜色矩 8
3.1.3相似度测量 10
3.1.4实验 10
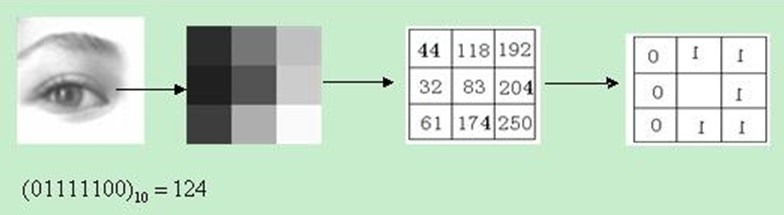
3.2基于纹理的图像检索 12
3.2.1灰度共生矩阵 12
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示:



课题毕业论文、开题报告、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。


