基于朴素贝叶斯的垃圾邮件过滤系统毕业论文
2020-04-15 18:09:45
摘 要
随着电子邮件的广泛使用,垃圾邮件呈现不容忽视的发展趋势,这使得垃圾邮件分类技术成为目前的一大热门研究领域。
本文通过对垃圾邮件泛滥状况的阐述指出本课题的研究具有深刻的现实意义,主要根据垃圾邮件的内容特征即特征词和对应词频建立了基于朴素贝叶斯算法的垃圾邮件分类系统。其中特征词的筛选和朴素贝叶斯算法的实现是两个关键步骤,本文主要针对这两方面重点研究。
在特征词筛选部分,本文提出了一种基于信息增益法的词向量化法。该方法首先根据词汇在邮件文本中出现次数即词频的大小赋予词汇不同权重。权值越大的词汇对于文本性质的区分度越大,越可能选作特征词。然后把权值和词汇一一对应实现文本数字化,建立向量空间模型。为了确定最终的特征集,用动态调整的方法对即选取高于一定权重阈值的特征向量集进行试验,观察结果选择最优的特征维数。通过信息增益法和特征维数动态调整可以极大地减少冗余数据影响,提高系统运行速度同时改善分类性能。
在算法选择方面,主要采用了朴素贝叶斯算法。该算法的基本思想是直接从样本中学习出条件概率。首先根据先验概率加数据分析得到后验概率思路,将文本分成训练集和测试集。然后通过Python分析软件编程,通过训练集的向量文本训练模型,其次利用朴素贝叶斯算法基于条件性独立假设的相关公式计算出测试集的初步分类结果,最后将分错类的邮件文本替换特征词后再尝试,多次反复此操作后得到一个优化的最终结果。
关键词:垃圾邮件过滤 朴素贝叶斯算法 特征词 向量空间模型
The Spam Filtration System Based on Naive Bayes Algorithm
Abstract
With the development of Internet technology and the wide application of e-mail, the problem of spam is becoming more and more serious, which makes the classification technology of spam become a hot research field.
This paper means that the research of the subject has a lot of significance, and explores a spam classification system based on Naive Bayesian algorithm according to the content characteristics of spam. Feature information extraction and algorithm implementation are two key steps. This paper focuses on these two aspects.
In the part of feature information extraction, this paper makes a word vector method based on information gain.Firstly, the method assigns different weights to words according to the number of occurrences of words in e-mail text, i.e. word frequency. The bigger the weight, the greater the distinction between words and texts, the more likely they are to be selected as feature words. Then the weight and vocabulary are corresponded one by one to realize text digitization, and the vector space model is established. In order to determine the final feature set, a dynamic adjustment method is used to test the selection of feature vector set which is higher than a certain weight threshold, and the observation results select the optimal feature dimension. Information gain method and dynamic adjustment of feature dimension can greatly reduce the impact of redundant data and improve system efficiency and classification performance.
In the aspect of classification algorithm, Naive Bayesian algorithm is adopted in the classifier. The basic idea of Naive Bayesian algorithm is to learn conditional probability directly from samples. Firstly, the idea of posterior probability is obtained based on prior probability and data analysis, and the text is divided into training set and test set according to a certain proportion. Secondly, the naive Bayesian algorithm is used to calculate the preliminary classification results of the test set based on the relevant formula of conditional independent assumption. Finally, the misclassified mail text is replaced by the feature words, and then an optimized final result is obtained after repeated operations.
Key Words:Spam filtering;Naive Bayes algorithm;Feature word;vector space modal
目录
第一章 绪论 1
1.1概述 1
1.1.1垃圾邮件的定义 1
1.1.2垃圾邮件特征 1
1.1.3垃圾邮件的危害 1
1.1.4 垃圾邮件现状 2
1.2电子邮件系统 2
1.2.1电子邮件的格式 2
1.2.2电子邮件工作原理 3
1.2.3电子邮件相关协议 3
1.2.4电子邮件的安全风险 4
1.3研究现状综述 5
1.3.1朴素贝叶斯算法的研究状况 5
1.3.2垃圾邮件过滤研究现状 6
1.4研究内容及论文重点 7
1.4.1主要研究内容 7
1.4.2论文重点 7
1.5章节结构 7
第二章 垃圾邮件过滤方案与其它技术 8
2.1垃圾邮件过滤方案的设计 8
2.1.1邮件信息预处理 8
2.1.2特征信息的提取 9
2.1.3特征词的向量化 9
2.1.4特征维数的确定 10
2.1.5 编写程序并试验 10
2.1.6性能评价指标 10
2.2.其它垃圾邮件分类技术 11
2.2.1 决策树 11
2.2.2 支持向量机 12
2.2.3逻辑回归 12
2.2.4卷积神经网络 13
第三章 朴素贝叶斯算法介绍 14
3.1贝叶斯算法概述 14
3.1.1贝叶斯定理 14
3.1.2贝叶斯算法的主要思想 14
3.2朴素贝叶斯算法应用于垃圾邮件分类 15
3.3贝叶斯分类器 15
3.3.1一般贝叶斯模型 15
3.3.2朴素贝叶斯模型 16
第四章 基于朴素贝叶斯算法的垃圾邮件过滤系统实现 17
4.1模型构建 17
4.1.1大致流程 17
4.1.2核心思路 17
4.1.3具体运算处理 17
4.2实验主要结果展现 19
4.2.1特征维数的确定 19
4.2.2最终分类结果 20
4.3评价与分析 21
图4.5 常用的邮件分类技术比较 22
4.4经济性与环保性 22
第五章 总结与展望 23
5.1总结 23
5.2对未来的展望 23
5.3朴素贝叶斯算法应用的影响 23
致谢 29
第一章 绪论
1.1概述
1.1.1垃圾邮件的定义
电子邮件在极大地简便了人们进行网络互动的同时,不可避免地被一些别有用心的人当做谋取私利或达到不可告人目的的工具,从而导致了垃圾邮件的产生。通俗地说,垃圾邮件就是那些对用户没有太大意义且会影响用户的使用体验被强行发送到用户邮箱中的含有如商业广告类的电子邮件。
通常垃圾邮件有以下几种:[1]
- 含有广告宣传等信息的电子邮件。
- 隐藏了发件人信息的电子邮件。
- 被大范围发送的电子邮件。
1.1.2垃圾邮件特征
绝大部分的垃圾邮件都被用作发挥经济、政治、社会等功能,包括但不限于产品宣传、散步谣言、传播色情信息。但也有少数垃圾邮件携带病毒等对用户和网络环境会产生恶劣影响[2]。
垃圾邮件具有以下几种特征:
第一:一般有邮件首部、邮件正文等部分。正文采用HTML格式,含有病毒的邮件通常作为附件。这样使它们具备强大的伪装能力,难以被基于邮件形式的规则过滤。
第二:垃圾邮件内容通常所占内存不大,方便用户查阅。据相关数据显示,93%的垃圾邮件大小在6K以下,其中1K左右的最多,占34%[3]。
第三:垃圾邮件往往倾向于高度密集散播,在短时间内会有大量电子邮件用户收到以扩大影响力。
1.1.3垃圾邮件的危害
垃圾邮件的产生于大量传播对用户和社会都造成了很大的负面影响,如:
- 占用网络资源,造成邮件服务器拥堵不堪重负。
- 影响了用户的日常网络生活,浪费时间精力。
- 对网络安全构成威胁,散播不良信息,破坏社会和谐。
1.1.4 垃圾邮件现状
下图为2009年至2017年全球电子邮件中垃圾邮件比例变化情况[4]。
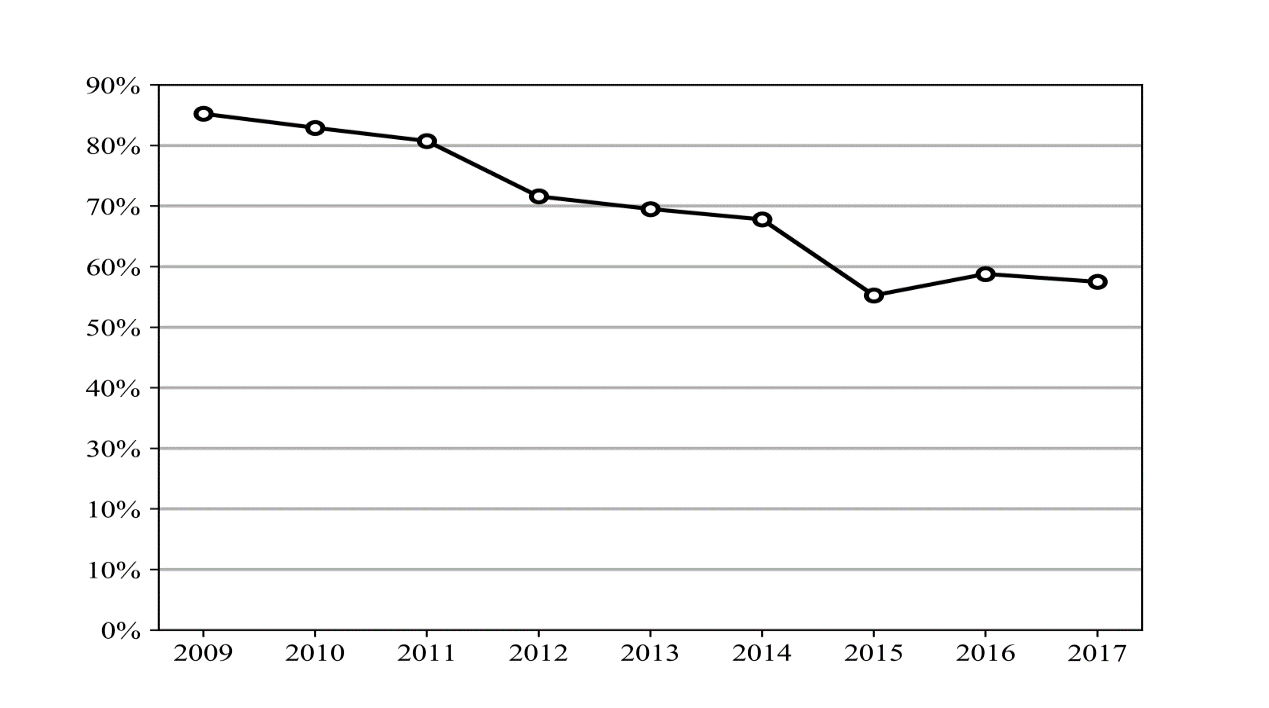 图1-1垃圾邮件比例变化趋势
图1-1垃圾邮件比例变化趋势
可以看出,垃圾邮件所占比例总体虽然有所下降,但2016年较2015年比例有所上升,主要原因是垃圾邮件数量的激增。
根据有关数据显示2016年中国邮件用户已经达到约26000万,中国是垃圾邮件产生最多的地方,大约每6封垃圾邮件里就有一封是中国的[5]。
1.1.5本课题研究意义
垃圾邮件的泛滥给个人和社会造成了极大的不便与危害,虽然目前已有一些垃圾邮件过滤技术但都不太成熟,存在显著缺陷[6],因此对垃圾邮件过滤的研究很有意义。
1.2电子邮件系统
1.2.1电子邮件的格式
现行的通用电子邮件标准格式是在2001年公布的RFC2822《Internet信息格式》[7]。
电子邮件由邮件首部和正文构成,以空行分开。
首部包含了主要参数如发件人、收件人、发送时间等信息如下所示:
From:aaa@qq.com
To:yyy@sina.com
Date:Tuesday,19 Sep 2017 12:06
1.2.2电子邮件工作原理
发件方通过邮件服务器和收件方沟通,收件方接收到通知信息后打开自己的电子信箱来查收邮件[8]。具体流程如下:
 图1-2电子邮件流程图
图1-2电子邮件流程图
1.2.3电子邮件相关协议
TCP/IP协议族是互联网通用的基础通信架构,网络协议的统称。参考模型如下:
应用层 |
传输层 |
互联网层 |
网络访问层 |
OSI模型(Open System Interconnection Reference Model)[9]是一个理想的互联网规范标准,因为协议过于繁琐并未实际应用。这一参考模型共分为七层:。
应用层 |
表示层 |
会话层 |
传输层 |
网络层 |
数据链路层 |
物理层 |
OSI七层的功能[10]:物理层是传输通路;数据链路层检查邮件;网络层提供寻址功能;传输层辅助网络层为两台计算机提供通信保障;会话层维护每个会话按序进行;表示层将各种通信统一标准方便用户;应用层直接服务于计算机各个应用程序。
TCP/IP协议涵盖了OSI模型的基本功能架构并简化,使得系统运行更加流畅可靠[11]。
- IP协议。IP协议是网络层的最重要协议,提供TCP/IP网络的基础网络服务如对链路层的协议封装、无连接数据传输、网络地址标示寻址、网络路由等[12]。
- TCP是用户之间连接的通信协议,工作在传输层。由于IP协议是一个不稳定协议,发送方并不知道对方有没有收到数据,TCP就是用于解决该问题。它提供基于链接的可靠传输协议,保障发送的数据按序抵达对方客户端。
- 电子邮件在网络中通过SMTP协议传输,它的工作方式是[13]:发送方服务器将邮件按时间顺序发送给收件方服务器,收件方每收到一条就做出相应处理,并向发送方服务器回答直到最后一个指令完成,发送方服务器向收件方服务器下达退出指令,双方断开连接。
1.2.4电子邮件的安全风险
电子邮件系统存在着很高的安全风险,如下几点所示:
1.SMTP缺乏服务器安全认证,无法检查服务器之间交换信息的准确性和可靠性等。
2.SMTP协议没有进行严格的加密措施,易被人找到安全漏洞。
3.电子邮件本身也是无加密保障的[14]。这导致其很容易遭到入侵并被利用,引发垃圾邮件泛滥而且不易查到垃圾邮件源头。
4.为了提高邮件发送效率采用的传送过程中的开放式转发也令人有机可乘[15]。
1.3研究现状综述
1.3.1朴素贝叶斯算法的研究状况
贝叶斯算法(Naive Bayes Algorithm)是由贝叶斯定理发展而来的,该算法具有深厚的数学思想。朴素贝叶斯算法对其进行改进,不考虑属性间的相互关联,这样很大程度上降低了实际流程设计与操作的难度和系统的运算量,能够良好地适应文本数量巨大的情况,不需要很多有效属性,对数据缺失不敏感。且原理相较而言不难理解,便于投入应用,因而目前已经成为国内外应用于文本分类方面的经典算法之一,并表现出了误差率很低的优点。
1998年,斯坦福大学的Sahami[16]将朴素贝叶斯算法引入到垃圾邮件的分类实验中。他在使用词汇特征外还包含了词组特征及其它相关属性特征。实验结果显示,其它属性能够富有成效地改善过滤性能,精确率约95%;Androutsopoulos[17]也曾通过朴素贝叶斯算法来识别垃圾邮件,他使用了公开语料库Lingspam作为数据集进行试验并观察不同的数据预处理方式对模型性能的影响,最终发现如果去除停用词并统一相关词会得到更加理想的效果;2015年杨国忠等人[18]开发了一种潜在的选择增强朴素贝叶斯分类器,和传统的SVM分类器相比性能有所改进。
为了削弱不平衡样本集的影响,华南理工大学的杨立洪[19]等人在2018年发布了一种相关属性约减—加权的朴素贝叶斯模型,采用自适应学习选择合适的阈值。
2019年2月武汉理工大学的黄勇[20]等人提出一种基于词向量间余弦相似度的改进朴素贝叶斯算法,有效的降低了特征向量的数据冗余和计算复杂性;
朴素贝叶斯算法发展至今已经有了许多成熟的应用范例,在文本分类领域的卓越表现也使其日渐为人们所青睐。本文在传统朴素贝叶斯算法的理论基础上,主要对特征提取进行优化,采用合理的特征词维数改善了分类性能。
1.3.2垃圾邮件过滤研究现状
目前垃圾邮件的分类方法种类繁多,可以分为以下三种主要类型:基于IP地址的过滤,如黑白名单法;基于邮件首部信息的过滤,有校验审查和授权审查等方法;基于邮件内容的过滤,如本文采用的朴素贝叶斯算法。前两种主要都是针对邮件的一些表面形式进行过滤,很容易被找到破解的办法,因而目前流行的都是基于内容的过滤。
2009年,王岩[21]在中国通信学会介绍了基于内容的垃圾邮件过滤方法,包括Ripper、决策树、粗糙集、自适应增强、贝叶斯、k-NN、支持向量机等。他反映自适应增强、贝叶斯、支持向量机是效果比较领先的技术。
2011年Clotilde Lopes[22]等人介绍了一种结合了协作(CF)和基于内容的过滤(CBF)的一些功能的共生过滤的混合方法,并聚合了来自多个用户的不同本地过滤器,允许使用社交网络来个性化和定制用作过滤输入的过滤器集,为垃圾邮件过滤提供了一个全新视角。
2012年国防科技大学的刘武英[23]等人基于电子邮件过滤是一种在线应用提出了在线主动多字段学习方法,将电子邮件垃圾邮件过滤视为增量监督二进制流文本分类。将现场分类结果的当前方差与历史方差进行比较,主动学习者评估分类置信度,并将更不确定的电子邮件作为请求标签的信息量更大的样本。实验结果表明,所提出的方法可以实现最先进的性能,大大降低了标签要求和非常低的时空成本。
2014年的IEEE第五届国际会议上Thomas[24]等人进行不同特征选择方法的比较研究,此外选择如电子邮件的标题、正文和主题的不同实体的分类预测。通过大量实验证明电子邮件标题和正文的加权互信息特征选择在电子邮件分类中是有效的。
2019年3月,威特沃特斯兰德大学的Melvin Diale[25]根据余弦相似度和自动编码等原理研究一种垃圾邮件过滤的无监督功能学习,降低特征维度,加速计算过程并提高准确性。
1.4研究内容及论文重点
1.4.1主要研究内容
1.调查了国内外垃圾邮件泛滥的现状与危害性,分析垃圾邮件内容特点。
2.介绍贝叶斯定理与朴素贝叶斯算法的应用。
3.利用收集到的邮件数据集和Python软件编程建立基于朴素贝叶斯算法的垃圾邮件分类系统模型。
4.通过训练集得出初步的结果,运用动态调整等方法确定特征维数。
5.将测试集数据投入模型测试并找出分错类邮件改进。
6.将评价指标应用于本文模型并与其它几种技术作对比分析基于朴素贝叶斯算法的垃圾邮件分类的优越性。
7.指出本系统可能存在的问题与今后研究方向。
1.4.2论文重点
1.基于信息增益法思想,根据词频计算公式赋予词对应的权值。
2.通过词向量化的方法对特征词进行数据化处理。
3.动态调整确定合适的特征维数。
4.利用Python编写程序并用训练集文本数据建模。
5.通过测试集数据试验并观察初步结果,将分错类的邮件修改特征词再学习并得出最终结果。
1.5章节结构
第一章介绍了垃圾邮件现状和本文研究重点等。
第二章阐述垃圾邮件过滤方案等。
第三章介绍了本次研究所应用的朴素贝叶斯算法相关知识。
第四章着力于分类系统实现与性能评价等。
第五章总结这次毕设,归纳心得体会,提出未来工作的展望。
第二章 垃圾邮件过滤方案与其它技术
2.1垃圾邮件过滤方案的设计
2.1.1邮件信息预处理
由于一封原始的电子邮件往往包含了不同数据类型的内容,不便于直接处理。因而在分类前首先要进行原始邮件数据的筛选加工等,将邮件文本统一转换成计算机方便分析的形式。主要步骤包括:过滤非法字符、分词、去除停用词、替换相关词等。
1.过滤非法字符
采集到的邮件数据的来源可能五花八门,里面容易夹杂一些非法字符及无意义字符等,比如标点、乱码等不需要的内容,因而首先要删掉邮件数据集中的垃圾数据,避免不必要的麻烦和错误。
2.分词
分词就是将语句切分成一组词,通常分为中文分词和英文分词[26-28]。由于在中文邮件中,词之间没有类似英文的空格分隔,因此中文分词相对复杂。
当前应用最广泛,技术最成熟的中文分词手段是基于统计的分词法[29],通过涉及范围丰富的人为标注的词性和中文词出现频率作为统计特征,学习标注好的文本数据,得到各种分词情况下的词出现概率并选择可能性最大的结果。总体而言这种技术较为全面地考查了词频和词的内容含义,效果要优于其它一些常见的分词手段如基于字符串匹配的分词法[30]、基于理解的分词法[31]、基于词与词相结合的分词法[32-33]等。
3.去除停用词
一般来说停用词是指被频繁使用但无重要含义的词如:“这个,那个this,some”为了减少这些多余的工作量并节省存储空间,在分类前必须要剔除掉这些停用词。
4.替换相关词
替换相关词是对文本数据质量的改进与优化,步骤主要包括:将英文中的动名词、过去式和过去分词、复数形式等统一换成原形;将数值统一换成NUMBER,日期组合如2015-06-18统一换成NUM-DATE,英文和数字组合替换成ENG-NUM等。这些措施可以大幅减小词典的内容含量,提高了模型的运行效率,改善分类效果。
2.1.2特征信息的提取
一封电子邮件的内容很多,不可能将所有的词汇和语句都用于分类,因而必须选择那些具有较高区分度的词汇即能够帮助我们识别出邮件性质的核心信息部分。本文基于信息增益法的思想来实现对特征词的选择[34-36],信息增益法主要用来测量特定的属性对于训练样本的区分度,表明一个特征词提供的信息能使邮件性质的不确定度减少的程度。由于在垃圾邮件中如一些商业广告邮件中类似于“price”这种词的出现次数较高,即权值较大,故信息增益也越大。采用信息增益法可以极大地降低特征向量空间的维数,减少冗余数据影响。改善分类精度,提高效率。
关于权值的统计方法主要有:词频TF(Term Frequency)是一词语在文本中出现的次数除以邮件所有词语数,这样计算可以防止因内容多少而引起的差异;逆文本频率指数IDF(Inverse Document Frequency)是指如果包含某词条的邮件越多,则IDF值越小,即倾向于排除常见词。这两种方法都缺乏理论上的充分证明,关于词的权重计算应具体情况具体分析,目前没有一套标准的比较完善的普遍公式。本文主要通过统计词条出现的次数作为计算邮件特征权值的依据,同时结合IDF理论,综合评估一个词汇的区分度水平,充分运用计算机强大的运算能力得到精确的量化的结果。
2.1.3特征词的向量化
所谓词向量化是指用实数向量表示文本中的词,把任何输入统一转化为方便计算机识别和处理的数值表示形式,即将待分类的邮件通过Word2Vec、随机初始化等多种方式抽象为一个基于其特征词的向量空间模型[37]。用特征向量代表词,一封邮件可以简化成一个n维向量:(A1,A2,A3…Ai…An),这里的Ai(i=1,2,3…n)指特征项的权值。
以下是邮件数据处理的流程图:
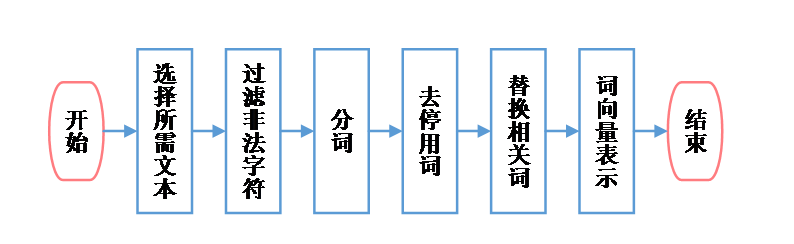 图2-1邮件数据处理流程图
图2-1邮件数据处理流程图
2.1.4特征维数的确定
经过上述操作可以得到初步的特征词集,但特征词数量庞大且里面仍然包含了很多对于文本区分度不高的词汇,因此需要确定一个合理的特征维数,提高运行速率和分类系统性能。选取合适数量的具有较大信息增益的特征词是关键步骤,本文通过动态调整来模拟,依次删除在邮件中出现频率n(n=1,2,3……)的特征词,观察剩下的不同维数的特征词对分类效果的影响。即通过多次试验寻找一个使训练效果达到最佳的特征词维数,从而逐步确定排在前面多少位的特征词向量组成最终的向量空间模型。
2.1.5 编写程序并试验
通过Python分析软件编写程序并用训练集搭建初步的基于朴素贝叶斯算法的垃圾邮件分类系统模型,利用动态调整确定合理的特征维数后再将训练集文本数据投入模型试验。
2.1.6性能评价指标
由于邮件分类属于二分类的范畴,故可将样本数据分类结果贴上四种不同标签:实际为正常邮件的被正确地分成正常邮件的为NP(Normal Positive);实际为正常邮件的被错误地分成垃圾邮件的为NN(Normal Negative);实际为垃圾邮件的被正确地分成垃圾邮件的为SP(Spam Positive);实际为垃圾邮件的被错误地分成正常邮件的为SN(Spam Negative)。目前主要有几下几项评价分类系统性能的指标:
1.准确率(Accuracy):这是整个垃圾邮件分类系统评价的最常见的指标,其含义是正确分类的邮件数量占所有邮件数量的比例,公式如下:
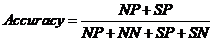 2-1
2-1
2.召回率(Recall):指的是检测为垃圾邮件的邮件数量占垃圾邮件总数的比例,公式为:
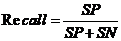 2-2
2-2
3.精度(Precision):精度也叫精确率,指的是被检测为正常邮件的样本数量占实际的正常邮件总数的比例,计算公式如下:
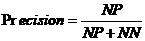 2-3
2-3
4.F1分数(F1 Score):F1分数是将精确率与召回率进行调和的综合评价指标,F1分数在0到1之间,一般达到0.8即可认为比较良好。计算公式如下:
 2-4
2-4
2.2.其它垃圾邮件分类技术
2.2.1 决策树
决策树是一种机器学习分类方法,基于树结构来进行决策分类[38]。决策树的核心思想就是在数据集中找到一个目标属性,然后从这个属性的选值中找最优分裂值。常见的决策树算法是ID3[39]和C4.5[40]。
ID3通过信息增益属性来进行属性筛选,选择分裂后信息增益最大的属性[41],计算公式为:
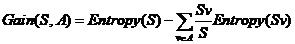 2-5
2-5
公式2-5中Gain表示增益度,v代表属性A的一个参数值,Sv表示S中属性为v的集合,Entropy是信息熵。公式为:
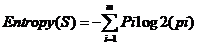 2-6
2-6
2-6中m为类别数。
C4.5算法用信息增益率选合适的属性。公式如下:
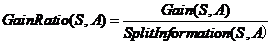 2-7
2-7
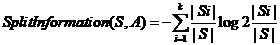 2-8
2-8
公式2-7中GainRatio表示增益率,2-8中SplitInformation表示信息分离程度。
决策树算法适用于训练邮件数较小,待分类邮件中垃圾邮件占比较高的情况,具有一定的局限性,特别是当邮件数量过大时易产生过拟合的情况,不太稳定[42]。
2.2.2 支持向量机
支持向量机是在20世纪90年代兴起的一种模式识别技术,具有深厚的概率论和数理统计基础[43]。其训练原理在根本上是解决一个关于二次规划的问题,并在全局中得到最优解决方案。
支持向量机通过构建最优线性分类超平面切分训练样本,并使得类别之间的间隔最大[44]。Drucker[45]很早将SVM用于垃圾邮件过滤,Androutsopoulos[46]也将此法用于文本分类的实验。不同的是,他采取实数值作为特征权重。总体来说支持向量机的分类效果还不错,实现了结构风险最小化、全局唯一解。但其参数优化问题一直悬而未决,而且需要对一切可能样本都进行分类,工作量太大,需要较长的系统运行时间。
2.2.3逻辑回归
逻辑回归是分类机器学习算法,通过对数似然损失函数用来解决二分类问题。核心思想是以某种事件发生的可能性当作因变量,作用于该事件发生结果的因素为自变量建立回归。因变量的可能取值是二分类变量,如阳性和阴性、男性和女性等[47]。主要步骤包括构建假设函数、寻找决策边界、求解代价函数、梯度下降法求偏导等[48]。逻辑回归属于判别式模型,容易实现。但它对非线性分类问题需要转化为线性分类,从而增加了很多难度和工作量。
2.2.4卷积神经网络
卷积神经网络从神经网络特点启发而研究得来的,它是一种使用卷积计算的前馈神经网络,人工神经元可以响应覆盖范围内的周围单元,也可以应用于文本分类[49]。Kim Y 等人最早将卷积神经网络( CNN) 运用到文本分类任务中[50]。卷积神经网络的权值共享机制降低模型复杂度,并通过空间关系约束参数个数,提高算法训练时的性能。网络结构图示如下:[51]
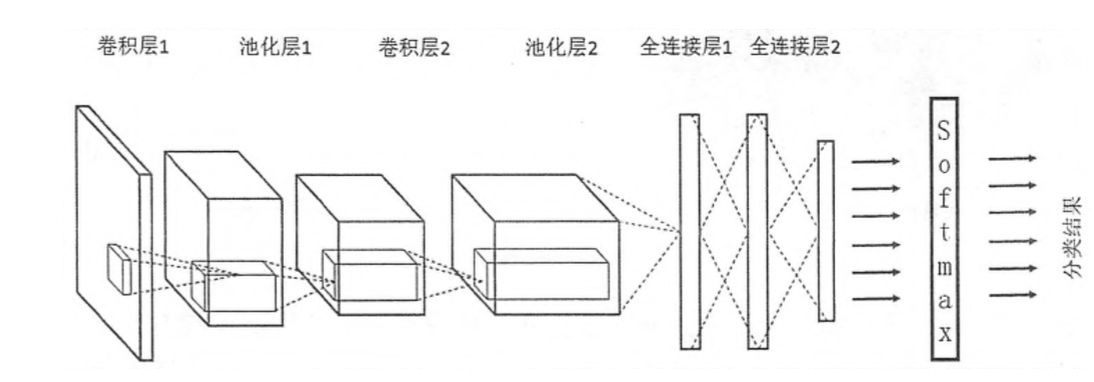 图2-2 卷积神经网络结构
图2-2 卷积神经网络结构
卷积神经网络原理不易理解,复杂的层级关系也导致其不够实用。
第三章 朴素贝叶斯算法介绍
3.1贝叶斯算法概述
3.1.1贝叶斯定理
贝叶斯定理是18世纪英国数学家托马斯·贝叶斯发明的根据已知事件的概率来推测未知事件发生可能性的统计学定理[52]。
3.1.2贝叶斯算法的主要思想
A事物在已发生的B事物条件下发生的概率与B事物在已发生的A事物条件下发生的概率不同但有关,贝叶斯定理以此作为依据。它的思想是:事件A在已发生的事件B的条件下发生的概率是事件B在已发生的事件A条件下发生的概率与事件A发生概率之积再与事件B发生概率之商,即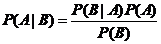 。贝叶斯公式可以通过已知的三个条件概率得出第四个[53]。
。贝叶斯公式可以通过已知的三个条件概率得出第四个[53]。
贝叶斯定理也可理解为条件概率程式,条件概率(conditional probability)P(A|B)指在事件B发生后事件A发生的概率[54]。
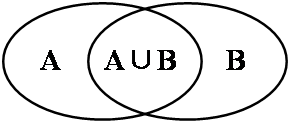
图3-1 条件概率文氏图
P(A)称为先验概率(prior probability),即在事件B发生前事件A发生概率;P(A|B)称为后验概率(posterior probability),即在事件B发生的前提下事件A发生概率,它是获取了其它有效信息的基础上对先验概率做出修正后的概率;P(B|A)/P(B)为可能性函数(likely hood),作为一个调整因素使得预测结果准确率更高[55]。
一言以蔽之,贝叶斯算法的主要思想是先计算待分类样本的先验概率,然后加入实验用的数据集计算样本的后验概率。
3.2朴素贝叶斯算法应用于垃圾邮件分类
相较于其它常见的文本分类方法,基于贝叶斯算法的分类模型系统运行很快、准确度高、属性要求低,能有效应对大数据状况,因而具有良好的可实现性。
本文分类的主要内容是将邮件文本进行向量化表示,核心是向量化后的特征提取,决定了分类的质量优劣从而影响最终预测结果的精确度[56]。
3.3贝叶斯分类器
3.3.1一般贝叶斯模型
 在一般贝叶斯模型中,特征项之间往往存在相互关系,如下图所示:
在一般贝叶斯模型中,特征项之间往往存在相互关系,如下图所示:
图例3-3一般贝叶斯结构模型
C表示一个父结点,通过一组与与父节点相连的子节点Wi(i=1,2,3……)表示各特征属性。子节点间的箭头相连表示两者相关,不是相互独立的。由于特征属性间的连线数量较多,要得到所有特征属性的概率非常繁琐,也极易出错。因此在实际问题处理过程中必须对一般贝叶斯模型进行简化,以减少甚至消除彼此间的相互关系。
3.3.2朴素贝叶斯模型
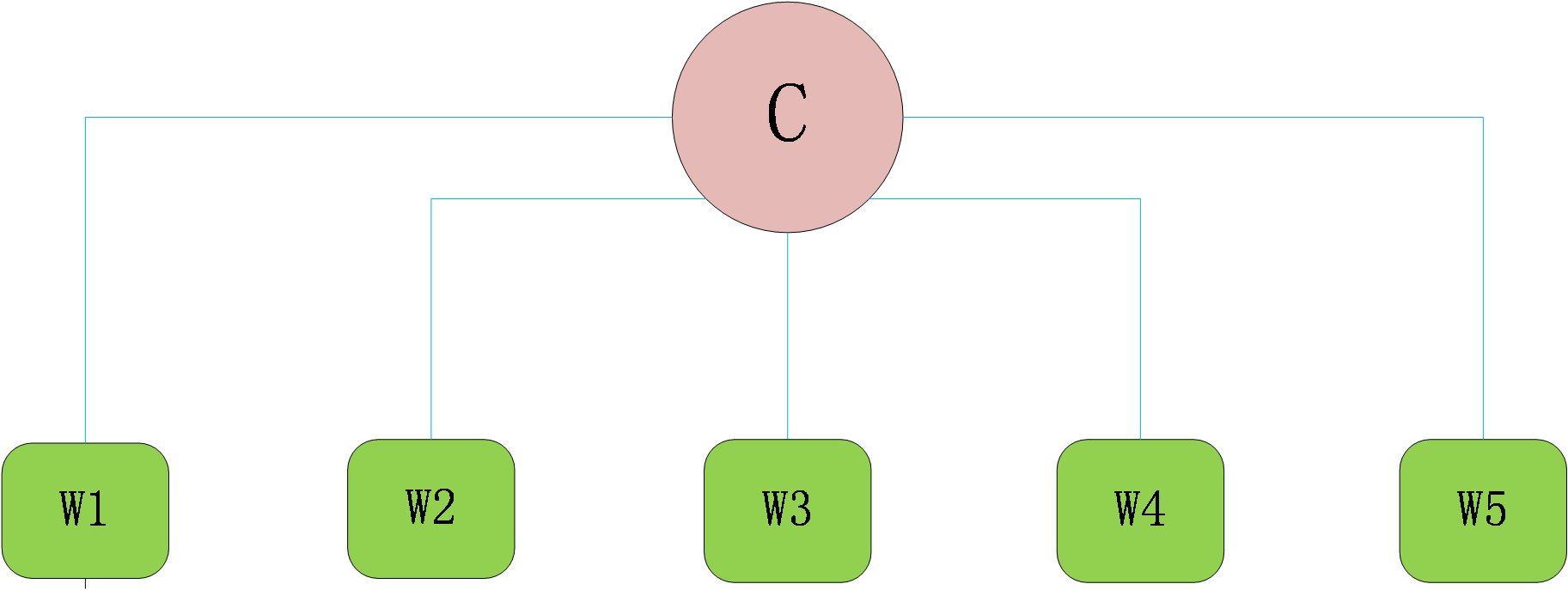 朴素贝叶斯模型假设各属性之间无关联即完全独立,模型如下:
朴素贝叶斯模型假设各属性之间无关联即完全独立,模型如下:
图例3-4朴素贝叶斯结构模型
朴素贝叶斯模型中子结点只和父节点相关,子节点与其他子节点之间相互独立,大大降低了计算量,提高了准确率。因而已被广泛运用于各种文本聚类、分类。
第四章 基于朴素贝叶斯算法的垃圾邮件过滤系统实现
4.1模型构建
4.1.1大致流程
根据第二章的安排,本文的分类流程由四个部分构成:
1.数据预处理:清洗筛选原始数据并换成计算机能够操作的合法格式。
2.向量化表示:将特征词转化成向量并优化,确定合适的特征维数。
3.建立朴素贝叶斯分类模型:利用Python编程并通过训练集数据模拟学习,建立原始模型。
4.测试与评估:使用测试集得出结果并将分错类的邮件替换特征词重新学习,根据各项评价指标评估分类效果。
4.1.2核心思路
本文思路大体如下:从KAGGLE数据库中寻找约一千封包含了垃圾邮件和正常邮件的数据集,按照大约7:3的比例分为训练集和测试集。且所有的垃圾邮件和正常邮件都已确知以便验证分类结果。然后对邮件进行一系列数据预处理工作如过滤非法字符、去除停用词、替换相关词、分词等步骤,通过词向量方法将所有的输入都转化成便于计算机运算的数值表示形式。建立常用词的词典,根据TF-IDF公式计算每个词的词频,将词典和样本数据的词频一一对应并获得每个特征词的向量空间模型如[0.02,0.06,0.08,0.09……]。
4.1.3具体运算处理
1.关于特征词权值的计算
本文根据TF-IDF理论思想,主要统计词频的方法计算特征词权值从而确定特征词集。采用的词频计算公式如下。
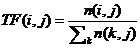 4-1
4-1
现通过下面的例子详细阐述:
这是一封英文邮件的一部分:
My dream used to be work somewhere in the fashion design area,once I took a sewing and design course and I had a wish that I could come to a fashion design course.But I had no talence to realize my dream and it just was a dream.I realized I should work in another area.
引用上文提供的词频计算公式4-1,这段文字中特征词的词频分别为:
Course-0.035,design-0.053,dream-0.070,fashion-0.035,sew-0.018
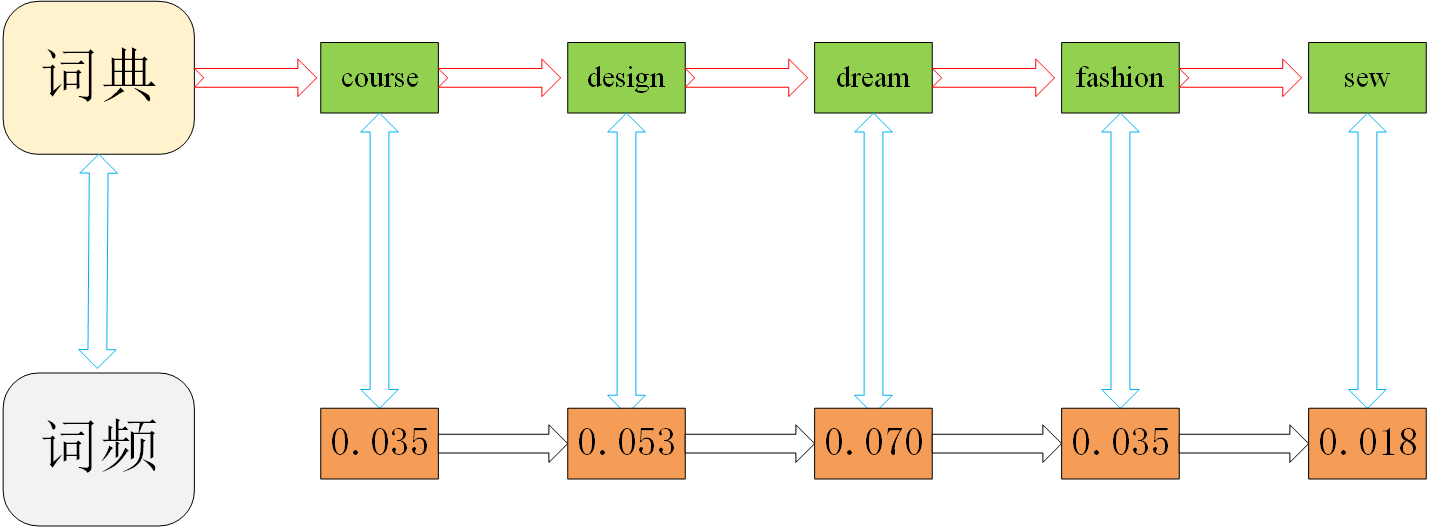 则(0.035,0.053,0.070,0.035,0.018)就是这段邮件的向量化。如下图所示:
则(0.035,0.053,0.070,0.035,0.018)就是这段邮件的向量化。如下图所示:
图例4-1词频统计
2.关于朴素贝叶斯算法的计算
为了方便阐述,首先定义几个变量:xi∈X,yi∈Y{c1,c2,c3……,ck}。X是属性集合,Y是文本分类集合。由3.1.2中的条件概率计算公式可得:P(Y|X)=P(X|Y)*P(Y)/P(X)。由此推理可用如下公式判定未知x类别:
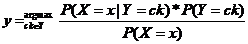 4-2
4-2
而公式4-2中对于ck来说P(X=x)相等,故可简化为:
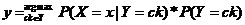 4-3
4-3
公式4-3中P(X=x|Y=ck)为后验概率,P(Y=ck)为先验概率。假设xi可能取值有Sj个,Y可能取值有K个,则需要估计的参数为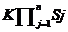 个。为了解决计算复杂度问题,朴素贝叶斯理论提出属性独立假设,公式如下所示:
个。为了解决计算复杂度问题,朴素贝叶斯理论提出属性独立假设,公式如下所示:
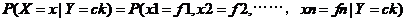
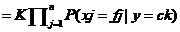 4-4根据公式4-4改进后的公式变为:
4-4根据公式4-4改进后的公式变为:
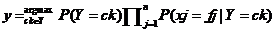 4-5
4-5
通过公式4-5简化后系统只需计算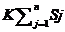 个参数,相比原始参数已经显著提高了效率。
个参数,相比原始参数已经显著提高了效率。
4.2实验主要结果展现
本文从KAGGLE数据库中选取了约一千封邮件作为样本,先通过700多封训练集样本建立了初步的训练模型,通过动态调整确定合适的特征维数。然后通过260封测试集中的样本进行多次测试与优化,得出最终分类结果,统计准确率、查全率等指标,详情如下所示:
4.2.1特征维数的确定
为了确定分类结果达到最优的邮件特征维数,本文进行了多次试验,从100维的特征集每次增加100直到1500维的特征集,以下是绘制的具体数据表:
表4-2 特征维数的确定
特征维数 | Precision | Recall | F1 |
|---|---|---|---|
100 | 81% | 84% | 0.825 |
200 | 82% | 86% | 0.84 |
300 | 84% | 91% | 0.874 |
400 | 87% | 89% | 0.88 |
500 | 90% | 88% | 0.89 |
600 | 92% | 92% | 0.92 |
700 | 91% | 90% | 0.905 |
800 | 90% | 89% | 0.895 |
900 | 91% | 93% | 0.92 |
1000 | 93% | 94% | 0.935 |
1100 | 89% | 95% | 0.919 |
1200 | 87% | 96% | 0.913 |
1300 | 88% | 94% | 0.909 |
1400 | 86% | 91% | 0.884 |
1500 | 83% | 90% | 0.864 |
从上表可以分析出精确率和召回率随特征维数的变化而浮动且缺乏规律性,总体而言特征维数太少或太多效果都不太好。以F1指数作为综合评价指标来看,当特征维数达到1000时分类的效果最优,其中精确率93%,召回率94%,F1值为0.935。故本文选择1000维的特征集进行试验。
4.2.2最终分类结果
本文为了实现预期分类效果,从前一次效果较差的试验中找出被错判的邮件样本,根据IDF思想即词的区分度和出现在不同邮件的频率成反比,修改分错类样本的特征词进一步优化,主要和其它邮件比对特征词,替换掉出现频率较高的特征词,然后将更新后的错判邮件样本重新加入试验。利用公式2-1、2-2、2-3、2-4计算出几次主要分类结果如下表所示:
次数 | NP | NN | SP | SN | Precision | Recall | F1值 |
|---|---|---|---|---|---|---|---|
1 | 117 | 13 | 116 | 14 | 90% | 89% | 0895 |
2 | 120 | 10 | 118 | 12 | 92% | 91% | 0.915 |
3 | 121 | 9 | 119 | 11 | 93% | 92% | 0.925 |
4 | 123 | 7 | 121 | 9 | 95% | 93% | 0.940 |
5 | 126 | 4 | 124 | 6 | 97% | 95% | 0.960 |
表4-3分类情况统计
从上表可以看出随着特征集的不断调整,被正确分类的邮件数量增加,试验效果越来越好,各项指标均有改善。达到的最好效果是NP为126,NN为4;SP为124,SN为6。精确率97%,召回率95%,F1值0.960。下图是最终的分类结果:
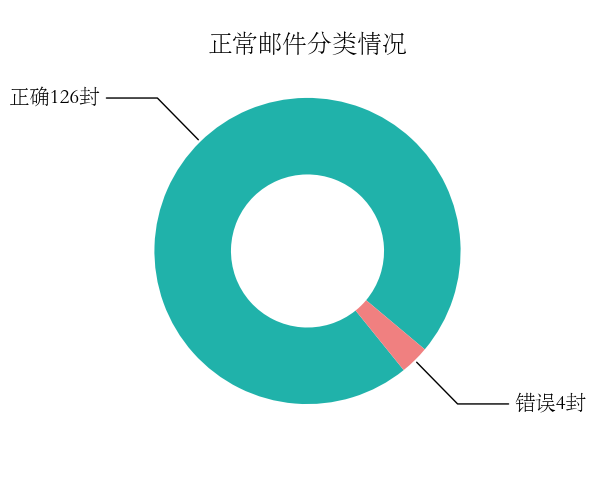
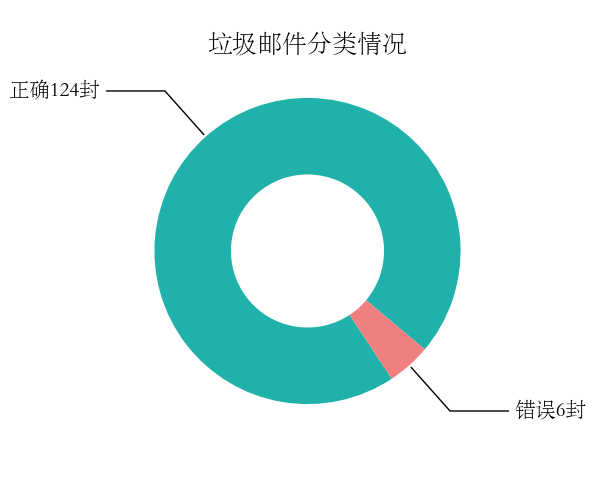
图4-4最终分类结果
4.3评价与分析
为了保证分类系统的结果是科学可靠的,本文基于先验概率加数据分析得出后验概率的思想将所有的邮件文本按照一定的比例分成训练集和测试集,通过词频计算公式和朴素贝叶斯算法相关公式得出分类结果。
将本次试验结果与其它过滤技术对比,如图所示:
图4.5 常用的邮件分类技术比较
从上图可以看出朴素贝叶斯算法在各项主要性能指标上均优于其它过滤技术,特别是比起目前同样应用广泛的支持向量机来毫不逊色,而且原理不算复杂,便于实现且稳定可靠,总体而言取得了预期效果。
4.4经济性与环保性
本系统在设计过程中通过确定合适的特征维数大幅减少了不必要的计算机运算时间与能量消耗;并且实际性能也达到了预期效果,优于其它技术。邮件被误判的比例非常低,尽量减少了垃圾邮件对用户的滋扰,很大程度上降低了用户浪费在垃圾邮件处理上的时间与精力。总体而言基本符合经济性与环保性的要求,良好的效果能够满足用户需求。
第五章 总结与展望
5.1总结
本文首先介绍了垃圾邮件问题与国内外调查现状,其次分析了电子邮件系统的基本原理、工作机制、存在的安全隐患等。相关背景的阐述为本文对症下药地研究与设计基于朴素贝叶斯算法的垃圾邮件分类系统提供了理论依据。以此为基础进而详细介绍了了贝叶斯定理及朴素贝叶斯算法。分类系统实现的主要步骤包括词频统计,特征词筛选,特征维数的动态调整,利用Python软件编写模型程序,对分错类的邮件重新学习等。总体而言运用合理的理论方法并提供了技术支撑,最终也取得了达到预期的效果。
5.2对未来的展望
本次实验虽然取得了不错的结果,但仍存在不少需要改进的地方。而且随着垃圾邮件传播手段的多样化,垃圾邮件抗过滤能力逐渐提高,必然要求我们在严峻的反垃圾邮件新形势下推陈出新,不懈努力追求,学习研究出更先进的反垃圾邮件技术。
在未来的工作中我认为主要注意一下几个研究方向:
1.邮件数据量出现过拟合与欠拟合的情况时怎么处理
2.本系统主要针对的是英文邮件的过滤,相比较而言中文邮件过滤更加棘手,以及中英文混合邮件的过滤都是值得深入研究的方向。
3.对于包含有图像,动画等格式的垃圾邮件的分类问题是目前的一个技术难点与热点[57-58]。虽然已有一些国内外研究公司以图像的视觉特征如颜色、形状等作为分类依据,但技术仍然很不成熟,难以大规模投入实际应用。因此仍需深入探讨,运用更成熟的过滤方案和更先进的过滤技术,通过多样化思维研究该领域。
5.3朴素贝叶斯算法应用的影响
朴素贝叶斯算法与现代自动化领域的结合能够为文本分类提供强大的技术支撑,无需用户自己分辨垃圾邮件,极大地提高效率与准确率,而且缓解了垃圾邮件泛滥的状况,有利于社会秩序的稳定。
但朴素贝叶斯算法在应用的同时不可避免地要获取了用户的邮件内容信息,可以说是一定程度上侵犯了用户的个人隐私,因此需要我们潜心研究,设计出更加安全保密的系统模型。
参考文献
[1]李雨亭. 基于深度学习的垃圾邮件文本分类方法[D].中北大学,2018.
[2]垃圾邮件的特性分析[EB/OL].http://support.foxmail.com.cn.
[3]如何规避收到垃圾邮件[EB/OL].http://www.spamarchive.org.
[4]张健,栗文真,宫良一.恶意邮件检测技术研究[J].信息网络安全,2018(09):80-85.
[5]张小花. 基于文本分类技术的垃圾邮件过滤研究[D].安徽大学,2017.
[6]张幼麟.反垃圾邮件技术[J].信息与电脑(理论版),2016(15):52-54.
[7]段宏斌,张健.改进的Naive Bayes技术在反垃圾邮件系统中的应用[J].西北大学学报(自然科学版),2006(05):737-740.
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示:
课题毕业论文、开题报告、任务书、外文翻译、程序设计、图纸设计等资料可联系客服协助查找。


